컴퓨터와 같은 기계에 우리가 원하고자 하는 바를 수행하도록 하려면, 우리는 기계가 알아들을 수 있는 표현으로 명령문을 내려야 합니다. 필요한 문장을 출력하게 할 때도 print 명령문을 이용하고, 덧셈과 같은 단순한 연산을 할 때도 방법을 작성해야 합니다.
NLU(Natural Language Understanding)라는 기술이 등장한 취지는 기계에 기계어가 아닌, 사람이 평소 쓰는 자연스러운 표현 그대로 제공해도 기계가 알아들을 수 있도록 하자는 데 있습니다.

영화 ‘스타워즈’의 C-3PO나 R2D2, ‘아이언맨’의 자비스 같은 로봇 비서를 예로 들 수 있는데요. 우리 주변 가까이에서 찾아볼 수 있는 NLU의 예로는 애플의 Siri, 삼성의 빅스비 등이 있습니다. 우리는 일상 표현으로 스마트폰과 직접 대화하면서 명령을 내리지, send_msg(text=“휴가 신청합니다.”, who=get_team_leader(“XX팀”)) 같은 명령을 타이핑하지는 않습니다.
물론 아직 사람과 대화하는 것 같은 자연스러운 느낌을 얻기는 부족하고, 기계가 처리할 수 있는 상황의 종류도 한계가 있지만 언젠가는 스마트폰 너머에 사람이 있는 것 같은 착각이 들 정도로 자연스러운 인공지능이 나올 것은 분명한 사실입니다. 이번 글에서는 미래를 향한 딥러닝을 이용한 NLU의 기술과, 최근 NLU 트렌드에 대해 두 편으로 나눠 알아보겠습니다.
NLU이란?
NLU(Natural Language Understanding)는 한글로 ‘자연어 이해’에 해당합니다. 자연어 표현을 기계가 이해할 수 있는 다른 표현으로 변환시키는 것을 뜻합니다.
형태소 분석이나 구문 분석과 같은 자연어 처리(NLP, Natural Language Processing)와 혼용해서 사용되는 경우가 많지만, 사실상 NLU가 더 큰 개념인데요. 단순히 단어나 문장의 형태만 기계가 인식하도록 하는 것이 아니라 ‘의미를 인식하도록 하는 것’을 의미합니다. NLU 기능의 예로는 문장의 의도 분류, 서로 다른 언어 간 번역 문장 생성, 자연어 질문에 대한 답변 추출 등이 있습니다.
딥러닝 기술의 발전 덕분에 전통적인 통계•룰 기반의 NLU 기법이나 머신러닝 방식의 NLU 기법의 한계를 해결할 수 있게 되었습니다. 지난 수십 년 간의 전통적인 NLU 방식은 사람이 직접 추출한(hand-crafted) 특징에 강하게 의존했는데요. 이러한 특징들은 추출하는 데 시간이 많이 소요되고, 여러 다양한 경우에서 불완전한 점이 있었습니다.
그러나 최근 수년간 밀집된 벡터 표상에 기반한 인공신경망(Artificial neural network)이 다양한 자연어 처리 task에서 우수한 성능을 보여줬는데요. 이러한 트렌드는 워드 임베딩과 딥러닝 기술의 성공에 힘입은 것입니다. 딥러닝은 특징들을 자동으로 추출하고 표현할 수 있게 하는데요. 이러한 장점으로 인해 딥러닝 기반의 NLU 기법 연구가 활발해졌습니다.
전통적 방식의 한계와 딥러닝 방식의 특징은 아래와 같습니다.

● 전통적 방식(룰 기반 또는 머신러닝 기반)의 한계
룰 기반의 NLU 방식은 사람이 직접 추출한 Feature에 의존하는 것으로, Feature를 수작업으로 추출하는 데 시간 많이 소요되며 예외 처리 등에 취약합니다. 또한, 처리 대상 문장이나 문서가 길어질수록 정확도가 하락하는 경향이 있고, 처리 가능한 문서도 정형화된 텍스트에 한정된다는 특징이 있습니다.
규칙 기반의 수작업 특성상 처음 등장하는 신조어, 오타 등에 취약한 단점이 있는데요. 머신러닝 기반의 NLU 기법은 기계가 자동으로 모델을 학습하면서 룰 기반 방식의 공수를 많이 덜 수 있었습니다. 하지만 이 역시 모델의 구조(모델이 단순한 1차 함수인지, 더 고차원인지, 혹은 로지스틱 곡선을 그리는지 등)를 미리 지정해줘야 하는 등 작업자의 개입이 필요했습니다.
● 딥러닝 방식의 개선
딥러닝 기반의 NLU 방식은 데이터로부터 Feature를 자동으로 학습하는 방식입니다. 기존보다 폭넓은 문맥 정보 처리가 가능하고, 사진, 음성 등과 같이 다른 분야의 모델들과 연결한 Multi-modal 모델 구축이 쉬워진 장점이 있습니다. 예를 들어 이미지를 Input으로 받아서 간략히 설명하는 캡션을 생성하는 모델이 있습니다.
기존에 학습하지 않은 신조어나 오타에 robust 한 처리 기술이 있어서 룰 기반 방식의 한계를 보완할 수 있습니다. 또한, 모델의 구조를 미리 지정하지 않고 학습을 통해 모델을 만들어서 작업자의 개입이 최소화되며, 복잡하고 깊은 구조를 만들 수 있어 기존 방식보다 정확도가 높습니다.
NLU를 사용하는 기술은?
NLU는 기계가 자연어로 표현된 텍스트의 의미를 이해할 수 있도록 하는 기술입니다. 기계가 사람의 말과 글을 이해하도록 하려면 어떤 것이 필요할까? STT(Speech To Text)를 이용하여 텍스트로 만든 발화 데이터가 있거나 챗봇 대화 로그에 쌓인 대화 데이터들이 있다면, 먼저 해야 할 일은 이 비정형 텍스트 데이터를 컴퓨터가 인식하고 계산할 수 있도록 정량화하는 것입니다.

이것이 첫 번째로 소개할 워드 임베딩(Word embedding) 기술입니다. 워드 임베딩은 단어나 형태소를 벡터화하는 기술입니다. 단어를 벡터로 만들었다면 문장이나 문서를 매트릭스로 변환하는 작업이 가능해지는데요. 이렇게 되면 비로소 문장 감성 분류나, 기계 번역 등과 같은 task를 딥러닝 모델로 학습할 수 있게 됩니다.
이후에 할 수 있는 간단한 NLU task로는 문장 분류(Sentence Classification)와 같은 기술이 있습니다. 이는 문장을 여러 개의 카테고리로 분류하는 것으로, 카테고리의 종류는 사전에 정의되어 있어야 합니다. 문장 분류에는 문장을 긍정, 부정 등으로 분류하는 감성 분류나, 어떤 의도로 발화하였는지 발화 의도(질문, 요청 등)를 분류하는 의도 분류 같은 task가 있습니다.
기계가 단순히 문장을 몇 개의 카테고리로 분류하는 수준에서 더 나아가서, 한 문장, 또는 문서가 입력될 때 기계가 다른 문장을 출력하는 Sequence to Sequence 기술이 있는데요. 이는 한 언어의 문장을 다른 언어로 바꿔주는 기계 번역 task 등에 사용할 수 있습니다.
NLU 기술 중에서도 끝판왕이라고 할 수 있는, MRC(Machine Reading Comprehension) 기술과 대화 모델(Conversation Model)은 기계를 조금 더 사람답게 만드는 기술입니다. MRC는 질의 응답 기술로, 사용자가 어떤 질문을 했을 때 기계는 자신이 학습했던 내용 중에서 적절한 답변을 알아서 찾아 제공해주는 것입니다. 이 기술을 잘 연마한 로봇은 퀴즈쇼에서 우승할 수도 있다고 하는데요. 대화 모델은 위와 같은 기술들을 총망라해 사람처럼 자연스러운 대화가 이어질 수 있도록 하는 기술입니다.
모든 NLU 기술을 이 지면에서 자세히 다루는 것은 한계가 있지만, 이 장에서는 위에 언급한 NLU 기술이 어떤 것인지 이해하고, 그에 쓰인 딥러닝 방식은 무엇인지 간단히 소개하는 데 초점을 두고 셜명해 드리겠습니다.
① 워드 임베딩(Word embedding)
워드 임베딩(Word embedding)이란 자연어로 표현된 단어를 벡터화하는 과정입니다. 따라서 word2vector로 표현하기도 합니다. 단어를 벡터화하는 가장 단순하며 원시적인 방식으로는 One-hot 벡터 인코딩(one-of-k 벡터 인코딩)이 기본적입니다.
이는 k개의 단어가 있을 때, k-dimension의 0 벡터를 만들고 해당 단어의 인덱스만 1로 표현하는 방식입니다. 주어진 문장을 one-hot 벡터로 표현하려면 우선 중복을 제거한 총 단어들을 나열하여 각각을 one-hot 벡터로 만들고, 이렇게 만든 one-hot 벡터로 주어진 문장을 새로이 표현하여 재구성하는데요. 예시를 들자면 아래 ‘그림 1’과 같습니다.
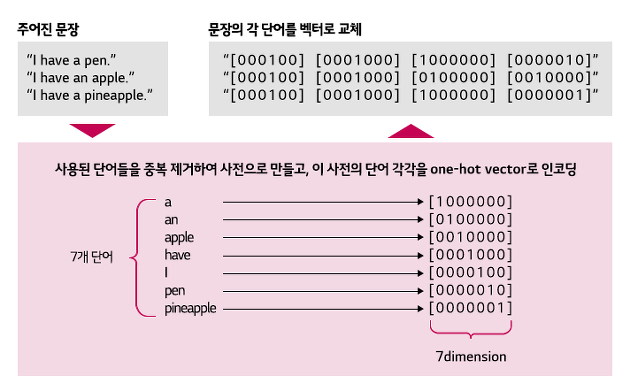
One-hot 벡터 인코딩 방식의 단점은, 모든 단어를 one-hot 벡터로 만든다면, 벡터가 담은 정보에 비교해 처리해야 하는 차원이 몹시 커져 연산 비효율이 발생한다는 점입니다. 위 예시의 경우, 전체 단어는 7개로, 7개의 정보는 0, 1 값으로만 표현한다 해도 3차원(2³=8)으로 충분합니다. 하지만 one-hot 벡터 인코딩 방식은 각 단어를 표현하기 위해 ‘[1,0,0,0,0,0,0]’과 같은 7차원이나 되는 벡터를 이용해야 합니다.
표준국어대사전 기준으로 한국어는 약 51만 단어가 있는데, 하물며 숫자나 기호, 자주 쓰이는 영어 단어 등을 모두 다루려면 기계가 처리해야 할 벡터의 차원이 굉장히 많아집니다. 하지만 각 벡터의 대부분은 0 값으로, 담고 있는 정보(특정 인덱스에 위치한 1 값)에 비해 보유한 차원이 비효율적으로 비대합니다.
이러한 저장공간의 단점을 보완하기 위해, 인공신경망을 이용하여 고차원의 one-hot 벡터를 조금 더 응집된 형태의 저차원 벡터로 변환해주는 워드 임베딩 기술이 발전했습니다. 이는 여러 문장을 모델에 제공하고 문장의 문맥을 통해 단어의 의미를 학습시키는 방식인데요. 이 기술엔 CBOW, SKIP-GRAM 등이 존재하는데, 각 기술에 대해선 아래에서 간단히 다루기로 하겠습니다.
워드 임베딩을 이용해서 얻을 수 있는 장점으로는 크게 아래 두 가지가 있습니다.
● 유사 의미를 가진 벡터끼리 유사한 공간에 모이는 특징이 발생한다.
One-hot 벡터의 예제에서 ‘apple’에 해당하는 ‘[0,0,1,0,0,0,0]’ 벡터를 기준으로 볼 때, 이 벡터와‘pineapple’에 해당하는 ‘[0,0,0,0,0,0,1]’ 벡터의 거리나 ‘have’에 해당하는 ‘[0,0,0,1,0,0,0]’의 거리나 모두 같은 값으로 동일했습니다. 하지만 우리는 ‘apple’이 동사인 ‘have’ 보다는 마찬가지로 과일을 나타내는 명사 ‘pineapple’과 더 가까워야 한다는 걸 직감적으로 알 수 있습니다.
워드 임베딩은 여러 문장을 학습하면서 배운 문맥으로 벡터 간의 거리를 조정해주는데요. 그래서 ‘apple’과 ‘pineapple’의 벡터 간 거리를 가깝게 해주고, ‘a’와 ‘an’의 거리를 가깝게 해 주지만 ‘apple’과 ‘a’의 거리는 멀어지도록 합니다.
이런 특성으로 인해 다른 NLU task를 수행할 때 이점이 생깁니다. 예를 들어 카페 주문을 받는 챗봇이 있다고 할 때, ‘I’ll order a glass of apple juice.’라는 문장의 의도를 ‘주문’이라고 학습시켰다면 ‘I’ll order a glass of pineapple juice.’라는 문장은 학습시키지 않더라도 ‘주문’에 해당하는 문장이라고 인식할 확률이 높아지는 것입니다.
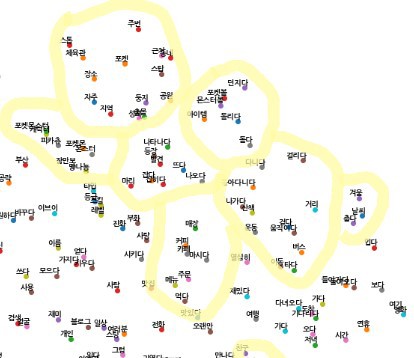
아래 ‘그림 2’는 AI 연구팀에서 수행했던 워드 임베딩 실험 결과를 일부 시각화한 것입니다. 학습 데이터는 소셜 데이터 중 ‘포켓몬GO’ 관련 문서들로 진행했으며, 유사한 맥락의 단어 벡터들끼리 비슷한 공간에 모인 것을 확인할 수 있습니다.
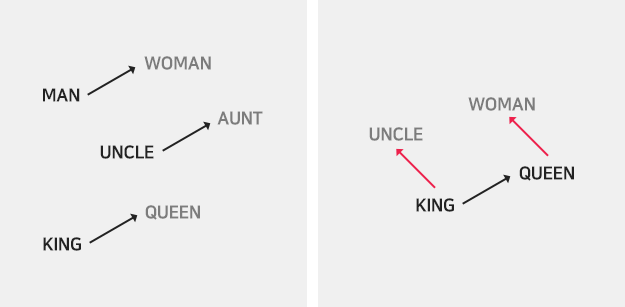
● 벡터간 의미를 가진 수리적 연산(사칙연산 등)이 가능해진다.
One-hot 벡터도 벡터의 형태이므로 벡터 간 더하고 빼는 등의 수리 연산은 가능합니다. 하지만 ‘apple’의 one-hot 벡터인 ‘[0,0,1,0,0,0,0]’을 ‘pineapple’인 ‘[0,0,0,0,0,0,1]’에서 뺀다고 해도 아무런 의미가 없습니다.
그런데 신기하게도 워드 임베딩에서는 벡터 간의 덧셈, 뺄셈이 의미를 지닙니다. 예를 들어 ‘삼성전자’라는 단어 벡터에서 ‘삼성’이라는 단어 벡터의 값을 빼 보겠습니다. 이 연산 결과는 무언가 전자기기를 다루는 회사에 대한 특성이 벡터로 표현 되어있을 것입니다. 여기에 ‘LG’라는 단어 벡터의 값을 더해보겠습니다. 이 ‘삼성전자-삼성+LG’ 연산의 결과 벡터와 가장 근접한 단어 벡터를 찾으면 놀랍게도 ‘LG전자’가 나타날 것입니다.
이렇듯 수리 연산에서 각 단어의 의미 특징을 살리는 워드 임베딩의 특징으로 인해, 대부분의 딥러닝 기반 NLU 과제에서는 워드 임베딩을 적용했을 때 정확도가 더 높아지곤 합니다.
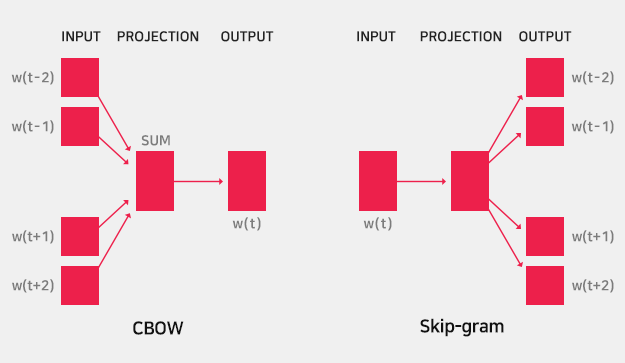
CBOW(Continuous Bag-of-Words)는 문장 내에서 주변 단어들을 모델에게 제공하고, 가운데 빈칸에 올 단어가 무엇인지 맞추는 방식으로 워드 임베딩을 학습합니다. k개만큼의 주변 단어가 주어지면 중심에 올 단어의 조건부 확률을 계산하는 방식입니다.
예를 들어 ‘원숭이에게 ( A )를 주었더니 껍질도 안 벗기고 잘 먹더라.’라는 문장이 있을 때, 학습되지 않은 초기 모형은 A에 들어갈 모든 단어의 확률이 동일하다고 여길 것입니다.
p(A=바나나) = p(A=귤) = p(A=비행기) = p(A=자동차) = …
하지만 다양한 문장들로 모형을 학습시킬수록 모델은 의미 있는 단어를 뽑아낼 수 있습니다.
p(A=바나나) > p(A=귤) > … >> … > p(A=비행기) > p(A=자동차) > …
이러한 과정들을 반복하면서 모델은 단어의 특성을 학습하게 되며, 좋은 품질의 워드 임베딩 벡터를 만들게 됩니다.
SKIP-GRAM은 한 단어를 모델에 제공하면, 모델은 이 주변에 어떤 단어들이 놓일지 맞히는 방식으로 학습하는데요. 주어진 중심 단어 주변의 k개 단어가 어떤 것이 나타날지 조건부 확률을 계산하는 방식입니다.
따라서 하나의 빈칸만 맞추면 되었던 CBOW에 비해 k개의 단어나 맞춰야 하는 SKIP-GRAM 모델은 당연히 더 어려운 과제를 수행해야 합니다. 이로 인해 CBOW보다 상대적으로 더 많은 학습 데이터가 필요하며, 더 어려운 과제를 수행해야 하므로 결과적으로 워드 임베딩의 품질은 더 좋은 경향이 있습니다.
SKIP-GRAM의 예를 들자면, ‘(A)까지 (B).’라는 문장이 있을 때 학습되지 않은 초기 모형은 다양한(말이 안 되는) A, B의 단어 조합을 출력할 것입니다. 하지만 다양한 문장을 모형에 학습시킬수록 p(A=머리부터)의 확률이 높아지는 등의 추론이 가능해집니다.
② 문장 분류(Sentence Classification)
문장 분류는 자연어로 입력된 input 문장을 k개의 카테고리 중 하나로 분류하는 기술입니다.
RNN(Recurrent Neural Network)은 시간에 따라 순차적으로 들어오는 sequence(문장)를 입력받아 학습하는 딥러닝 방식으로, LSTM Unit, GRU와 같은 recurrent unit을 이용합니다. RNN은 문장 분류, 기계 번역, 질의응답 등 다양한 분야에 사용 가능한데요. 문장 내 순서를 고려할 수 있는 특징이 있으나, 문장이 길어질수록 학습이 어려워지는 단점이 있습니다.
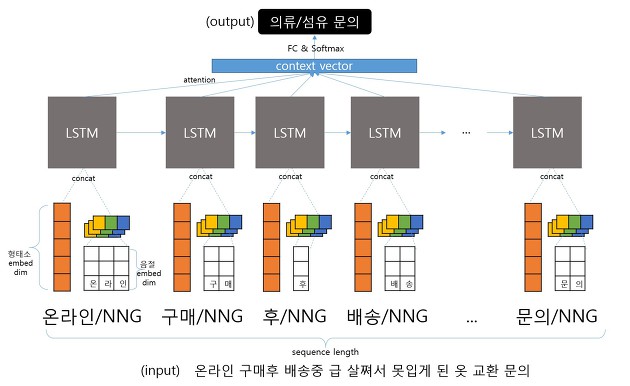
CNN(Convolutional Neural Network)은 입력 문장을 1차원 이미지처럼 취급해서 빠르게 학습시키는 방식입니다. CNN은 convolutional filter를 이용하여 학습하는데, 문장 분류의 경우 이를 이용하면 RNN과 분류 성능은 유사하지만, 학습 시간은 더 빨라집니다. 보통 자연어 처리보다는 이미지 처리에 주로 이용되는 알고리즘입니다. 자연어로 된 문장을 자모, 음절, 형태소 단위로 전처리하여 CNN으로 학습시키면 오타나 신조어에도 유연한 특징을 갖는다는 장점이 있습니다.
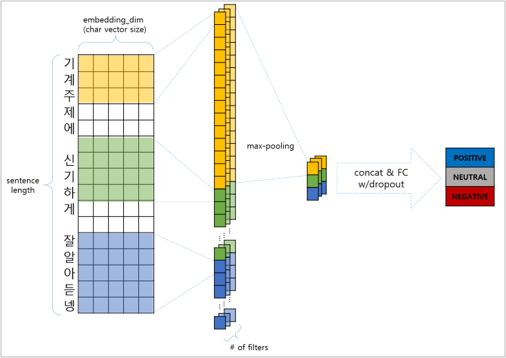
③ Sequence To Sequence (Seq2Seq)
Seq2Seq는 자연어로 입력된 문장을 입력으로 받고 출력 역시 자연어로 된 문장을 리턴하는 기술입니다. 주로 기계 번역, 문서 요약 등에 이용합니다.
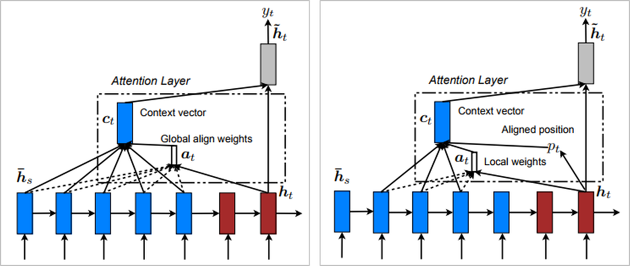
● Attention
기본 RNN에서는 입력 문장이 길어질수록 문장 앞부분의 내용 정보가 점점 소실되는 문제가 발생하는데요. 여기에 Attention 메커니즘을 이용한다면 긴 문장에 대해서도 처리가 가능해집니다. Attention 메커니즘에는 매 출력마다 입력 문장의 모든 단어를 살펴보는 global attention 방법과 한 번의 출력다 이에 상응하는 입력 문장의 일부 영역에만 집중하는 local attention 방법이 있습니다.
문장 분류의 경우에는 global attention을, seq2seq 경우에는 local attention을 적용하면 일반 RNN의 정확도 성능을 유의한 수준으로 개선할 수 있습니다.
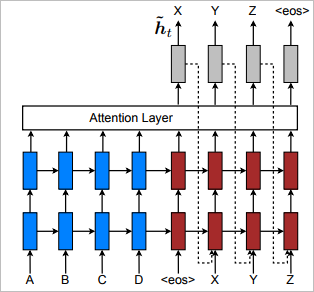
● Input Feeding
Input Feeding은 RNN에서, 현재 시점의 출력단어를 결정할 때 이전 시점에 모델이 내렸던 결정을 참고하는 방식입니다. 단순히 이전 시점의 출력 단어를 현시점의 입력에 연결해주는 간단한 기술인데요. 이 방식을 이용하면 모델이 이전의 결정을 완전히 인식할 수 있게 되고, 수직적으로나 수평적으로 매우 deep한 네트워크를 만드는 것과 같은 효과를 낼 수 있습니다.
● Copying Mechanism
RNN에서 입력 문장을 단어나 형태소 단위로 할 경우, 신조어나 사람 이름과 같은 고유 명사 등 사전에 없는 첫 등장 어휘에 대한 처리가 어려워 모델의 정확도가 하락하는 문제가 발생하는데요. 이에 사전에 없는 OOV word에 대해 토큰과 문장 내 위치를 표시하는 index를 부여하여 학습 진행하는 Copying 메커니즘을 이용할 수 있습니다.
output 출력 이후엔 이 토큰을 후처리로 별도 번역하거나, 고유 명사의 경우 그대로 이용합니다. 단순히 토큰만 이용하는 copyable 방식, 모든 output 단어에 대해 index 고려한 PosAll 방식, OOV 단어에 대해서만 index 고려한 PosUnk 방식이 있습니다. 이 방식을 이용하면 기계 번역의 주된 단점을 완화할 수 있으며, deep한 모델에도 적용이 가능한 장점이 있습니다.
④ Machine Reading Comprehension (MRC)
MRC(Machine Reading Comprehension)는 모델이 주어진 지문(Context)을 학습하고 질의(Query)에 대한 답변을 추론하는 기술로, MRC 수행 과정은 다음과 같습니다.
● Context에 대한 이해 & Query에 대한 이해
● Context와 Query의 관계 파악
● Context로부터 답변 검색하여 제공
딥러닝 기반의 MRC는 기존 온톨로지(ontology) 기반 기술의 단점을 해결할 수 있습니다.
● Pointer Network
Pointer Network는 결과 출력 시 입력 문장 중 정답에 해당하는 부분의 index를 출력하는 네트워크입니다. Seq2Seq 모델의 변형으로, 고정된 길이의 결과를 출력하는 기존 RNN과 달리 입력에 따라 유동적인 출력이 가능한 특징이 있습니다. Pointer network를 MRC에 적용하면 가변적인 지문 길이에 관계 없이 지문 내에서 정답에 해당하는 index를 뽑아낼 수 있게 됩니다.
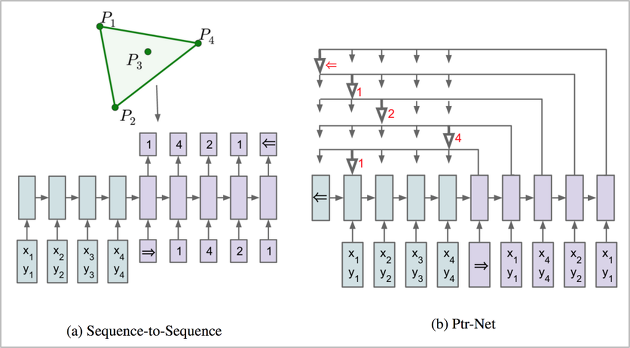
Seq2Seq 방식은 모델이 4개의 점 중에서만 정답을 만들어야 하므로, 이 모델은 4개 점이 있는 도형 외에는 적용이 불가합니다. Pointer network(Ptr-Net) 방식에서는 도형의 점이 몇 개이든 상관없이 결과를 출력하므로 하나의 모델로 여러 도형에 대해 유연하게 대처 가능합니다.
● Match-LSTM
Match-LSTM은 Context 문서와 쿼리(query) 문장을 연결하는 방식입니다. 단순하게 Context는 매뉴얼 문서, 쿼리는 사용자의 질문 문장이라고 생각하면 되며, Context의 매 단어를 LSTM의 input으로 입력할 때, 쿼리 문장 전체를 인식하도록 Attention 방법을 적용하여 Context와 함께 학습하게 합니다. Match-LSTM 기술로부터 Bi-DAF, R-NET 등의 심화 MRC 기술이 발전하여 등장했습니다.
⑤ 대화 모델(Conversation Model)
입력 문장을 이해하고, 답변을 생성하는 기능뿐만 아니라 대화의 흐름을 관리하는 기능 필요하여 생긴 것이 대화 모델(Conversation Model)입니다. 대화 모델은 대화 흐름과 문맥을 고려하여 사용자의 발화 의도에 대한 최선의 대화 전략을 결정하고, 시스템이 다음으로 발화할 의미 Feature를 생성합니다. 대화 모델은 사용자와 시스템의 정보 교환 방식, 시스템 내부 지식 처리 방식에 따라 구분할 수 있습니다.
● 사용자와 시스템의 정보 교환 방식에 따른 구분
[1회성 질의응답]
사용자가 질의하면 시스템은 결과를 제공하고 끝을 맺는 응답 방식입니다. 예를 들면 아래와 같은 대화입니다.
[연속 대화형]
사용자 입력에 대해 시스템이 여러 차례 의도를 확인하고 범위를 좁혀 결과를 제공하는 방식입니다. 예를 들어 아래와 같은 대화입니다.

● 시스템 내부 지식 처리 방식에 따른 구분
[Rule-based]
정형화된 구조로 지식을 만들어 시스템에 입력하는 방식으로, 구조와 대화 규칙을 작성하는 사람의 능력에 의존합니다. 따라서 규칙에서 조금이라도 변형된 문장의 처리나 예외 처리에 취약하며, 절차가 정형화 되어있고, 신뢰성이 중요한 분야에 적합한 방식입니다.
[Learning-based]
대규모 자료로부터 스스로 Feature를 추출하는 방식으로, 유사 표현이나 예외 처리에도 유연하게 대처할 수 있습니다. 기호로 표현하기 어려운 사진인식, 음성인식 등의 분야에도 적합하며 Rule-based 방식에 비교해 넓은 도메인에 적용할 수 있으나, 학습을 위해서는 방대한 데이터가 필요합니다.
챗봇을 위한 대화 모델은 대체로 Rule-based여서 다양한 표현에 대한 처리나 예외 처리에 취약한 한계가 있습니다. 이에 따라 하위 기능 일부(Intent matching)를 learning-based로 대체하거나, 매뉴얼을 학습시키고 그 안에서 시스템의 응답을 찾는 Question Answering 분야로 개선하는 추세인데요. 강화 학습을 이용하여 대화 흐름 전체를 모델링하는 연구도 점점 늘어나고 있습니다.
다음 시간에는 자연어 언어, NLU를 적용한 사례를 바탕으로 한 NLU 트렌드에 대해 알아보겠습니다.
글 | LG CNS 정보기술연구소



