지난 글에서는 인공지능이 이상 탐지 분야에 어떤 도움을 줄 수 있는지를 알아봤습니다. 그렇다면 구체적으로 인공지능을 이상 탐지에 적용하기 위한 절차와 방법은 어떻게 될까요?
● 도난 카드로 100만 원 플렉스? ‘수상한 결제’ AI가 잡는다!
이번에는 이상거래 탐지를 위한 인공지능의 학습 및 적발 과정을 알아보겠습니다. 아래 그림을 보면 인공지능이 과거 거래의 사기 패턴을 학습하는 ‘학습 단계’와 학습된 인공지능 모델로 새로 발생하는 거래의 사기 여부를 탐지하는 ‘탐지 단계’로 나눌 수 있습니다. 각각의 세부 단계를 알아볼까요?
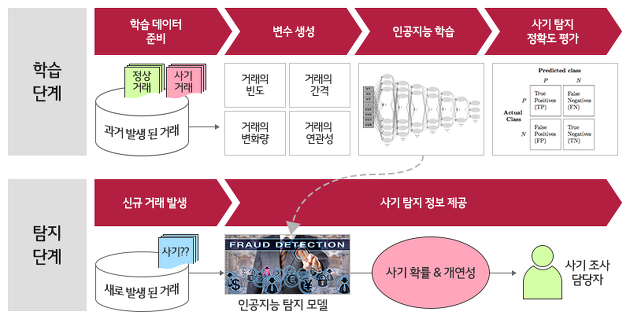
먼저, 학습 단계입니다. 학습 단계는 변수를 정의(생성)하고 준비한 학습 데이터로 인공지능 모델을 학습해 모델의 정확도를 평가하는 단계로 이루어집니다.
변수 생성 단계
거래 데이터를 인공지능 학습에 사용하기 위해서는 숫자 형태의 변수로 표현해야 합니다. 이 과정에서 적절한 수학적인 처리를 하게 되면 사기 변별력이 더욱더 높은 파생 변수를 생성할 수 있습니다.

생성된 변수는 모델 학습에 미치는 기여도에 따라 우선순위를 두어 선별하게 됩니다. 예를 들어 대포통장 개설 방지를 위한 모델을 개발할 경우에는 아래와 같은 내용을 인공지능에 학습시킬 수 있습니다.
- 계좌와 관련 정보: 계좌주의 직업과 성별 등 인구 통계적 속성, 계좌 개설 일자, 계좌 잔액
- 거래와 관련 정보: 거래 휴면기간, 거래 재개 후 거래 빈도와 금액, 입출금 채널의 특성
- 네트워크와 관련된 정보: 대상 계좌와 타 계좌 간 거래 관계, 계좌주와 관계인의 네트워크
이러한 정보를 바탕으로 이상 패턴을 포착하기 위해 거래의 간격, 크기, 증감량, 유사성, 빈도, 확률 등으로 수치로 표현해 학습을 위한 변수로 사용합니다.
학습 데이터 준비 단계
사기의 특성상 전체 거래에서 사기 거래가 차지하는 비율은 극소수입니다. 예를 들어 1,000건 거래 중 3~5건 미만으로 사기 거래가 존재한다고 하면 사기의 비율이 0.3% ~ 0.5%가 되는데, 이러한 현상을 데이터 불균형(Data Imbalance)이라고 합니다. 데이터 불균형 상태에서는 모형의 학습이 어렵고 사기 탐지의 정확도인 재현율(Recall-rate)이 낮아질 수밖에 없습니다.

데이터 불균형 문제는 생성적 적대 신경망(GAN, Generative Adversarial Network)을 이용해 효과적인 해결이 가능합니다. 최근 음원, 이미지의 합성에 활용되는 강화 학습 기법인 GAN을 이용하면 사기와 유사한 모조 사기 데이터를 복제 생성해 데이터 불균형 문제를 효과적으로 해결하고, 더 나아가 과거 사기를 합성해 학습에 사용하면 변화하는 사기 패턴에 선제적으로 대응하는 효과를 얻을 수 있습니다. 대부분 사기는 기존의 사기를 조금씩 변형하면서 진화하기 때문입니다.
인공지능 학습 단계
준비된 학습 데이터를 인공지능에 학습시키는 단계입니다. 딥러닝의 DNN, CNN, RNN 등과 같은 알고리즘을 사용할 수 있습니다.

DNN은 복잡한 사기 패턴 인지에 효과적이며, CNN은 시계열 거래의 2차원 이미지 벡터 변환을 통해 세부적인 특징을 학습하는 것에 적합하고, RNN은 순차적으로 발생하는 거래의 순서를 기억하며 학습하는 것에 유용합니다. 학습하려는 데이터에 적합한 알고리즘을 선택해 적용해야 합니다.
알고리즘별로 학습해 정확도가 높은 알고리즘을 선택할 수도 있고, 다수의 모형을 앙상블로 구성해 개별 모형이 가진 장점을 발휘하며 사기 탐지에 역할 분담하는 구조를 적용할 수도 있습니다.
사기 탐지 정확도 평가 단계
이진 분류 문제에서는 어떤 경우를 Positive로 하고 나머지 경우를 Negative로 할 것인지를 정하는 것이 중요합니다.
만약 암을 진단하는 사례에서 정상을 Positive로 설정한다면, 모든 환자를 정상이라고 진단하더라도 정확도는 99%가 나오겠지만 1%의 암 환자를 놓치면서 정상을 99%의 정확도로 맞추는 진단은 의미가 없습니다. 적발하려는 사례가 정상이 아니라 암에 걸린 사례이기 때문입니다. 그러므로 사기 탐지에서도 사기의 경우를 Positive로 설정하고 나머지 정상을 Negative로 설정해야 합니다.
그리고 분류 정확도(Accuracy)는 아래의 그림에서 ‘True Negative 건수 + True Positive 건수 / 전체 건수’의 계산으로 산출합니다. 눈여겨볼 부분은 사기를 정상으로 잘못 분류하는 미탐 영역인 거짓 음성(False Negative, Type II error)과 정상을 사기로 잘못 분류하는 오탐 영역인 거짓 양성(False Positive, Type-I error)입니다.
이 둘은 한쪽을 높이려 하면 다른 한쪽이 낮아지는 Trade-off 관계를 가지고 있습니다. 또한 업무 성격에 따라 다른 우선순위를 가질 수 있는데 예를 들면, 범죄 수사에서는 무죄 추정의 원칙에 따라 오탐이 미탐보다 중요하지만, 의료 진단에서는 암 환자를 정상이라고 진단하면 안 되기 때문에 미탐이 오탐보다 중요합니다.
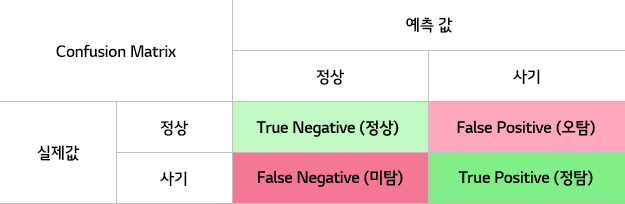
사기 탐지에서는 사기를 정상으로 허용하는 미탐이 높아지면 사기 손실 비용이 커지고, 정상을 사기로 잘 못 분류하는 오탐이 높아지면 조사 과정에서 고객의 불만이 높아질 수 있습니다. 적절한 미탐율과 오탐율을 설정하기 위해서는 기업의 정책과 현장의 경험을 조정하는 과정이 필요합니다.
사기 탐지 단계
사기 탐지 단계는 학습된 모형을 이용해 새롭게 발생하는 거래의 사기 여부를 탐지하는 단계입니다. 학습을 잘 시키는 것도 중요하지만 학습된 모형을 잘 운영하는 것이 더 중요합니다. 효과적인 운영을 위한 중요한 고려 사항이 있습니다.
첫째, 사기 탐지 시에는 ‘개별 거래의 사기 가능성(확률)’과 함께 ‘이런 확률을 보인 근거’가 제공되어야 합니다. 조사자로서는 확률보다 근거가 더 중요한 정보일 수 있습니다. 근거는 탐지에 사용된 변수와 데이터를 기반으로 도출할 수 있습니다.
둘째, 사기 거래의 패턴은 계속 변합니다. 그러므로 정확도를 지속해서 모니터링해야 하며, 주기적으로 모형을 재학습 시킬 수 있는 운영 환경을 만들어야 합니다.
인공지능 적용을 위한 고려 사항
다음으로 인공지능을 적용할 때 고려해야 할 사항을 확인해보겠습니다. 개발 및 운영 시에 고려하면 좋겠습니다.
첫째, 인공지능에 의한 불평등과 차별요소 제거
미국에서는 인공지능을 이용한 범죄예측, 사회보험의 부정수급 탐지 등에서 사회적 불평등이나 인종, 지역에 의한 차별을 고착화하는 사례가 있었습니다. 성별, 인종 등에 따라 차별적인 판정 결과를 보인 경우인데요. 사기 탐지에서도 변수를 선정할 때 고려해야 하는 점입니다. 예를 들면 직접적으로 인종이라는 변수를 사용하지 않더라도 거주 지역이라는 대리 변수가 인종을 대신 설명하는 방식으로 작용할 수 있습니다.

이를 방지하기 위해 인공지능에 학습된 데이터와 변수에 편향이 없는지, 모형의 학습 과정에 오류는 없는지 확인할 수 있는 체계를 갖추어야 하며, 인공지능이 결정한 결과에 관해 설명할 책임이 중요하게 대두되고 있습니다. 이미 금융권의 신용평가 업무 등은 평가 결과에 대한 법적인 설명 책임을 요구하고 있습니다.
둘째, Rule 기반의 탐지와 인공지능 모델의 협업
인공지능을 적용하게 되면 전통적인 Rule 기반 탐지 모델은 효과가 없는 걸까요? 그렇지 않습니다. 기업의 지식 자산인 직관적이고 강력한 사기 탐지 규칙을 인공지능 모델과 함께 사용하는 것이 좋습니다. Rule에 의해 탐지할 패턴과 인공지능에 의해 탐지할 패턴을 나누고 서로의 미탐, 오탐 영역을 교차 분석해 보완하면 업무 효율과 정확성이 더 높이면서 하이브리드한 형태로 발전할 수 있습니다.
지금까지 인공지능을 이용한 이상거래 탐지 시스템에 대해 알아보았습니다. 4차 산업혁명 시대에 인공지능은 인간의 지적 노동을 대체합니다. 인공지능을 의사결정 분야에 적용하려는 데이터 분석가들은 인공지능의 효과를 잘 발휘하면서도 부작용 없이 적용될 수 있도록 전문가적 주의를 갖고 노력해야 합니다.
글 l LG CNS Enterprise분석2팀


