수많은 학습 데이터를 주기만 한다면, 딥러닝은 문제를 잘 풀 수 있다고 알려져 있습니다. 예를 들어 1,000개의 카테고리에 대해 130만 장의 분류된 이미지가 있는 ImageNet 태스크에 대해 딥러닝 알고리즘은 Top 5 기준 98% 이상의 정확도를 달성하며 사람의 판별 정확도를 뛰어넘었습니다.

하지만 태스크에 맞는 데이터를 수집하는 것은 비쌉니다. 세상에는 이미지가 넘쳐나지만, 각각의 이미지가 어떤 의미를 가지는지 사람이 일일이 분류해 라벨을 만드는 것은 오래 걸리고 힘이 듭니다.
지도 학습, 비지도 학습, 그리고 자기 지도 학습
데이터와 라벨이 주어질 때 라벨을 이용해 태스크를 수행하는 방법을 학습하는 것을 지도 학습(Supervised learning)이라고 부릅니다. 이미지 분류, 양불판정, 감성 분석 등 우리가 생각하는 ‘인공지능에 시킬 수 있는 일’ 대부분이 이러한 지도 학습 방식으로 학습됩니다.

비지도 학습(Unsupervised learning)은 정답 라벨 없이 이루어지는 알고리즘을 말합니다. 이미지를 비슷한 것들끼리 묶는 군집 분석이 비지도 학습의 대표적인 예입니다.
자기 지도 학습은 라벨이 없는 데이터를 활용해 지도 학습의 방식으로 학습하는 알고리즘을 말합니다. 사람이 데이터에 대한 라벨을 제공해 주지 않아도 기계가 스스로 데이터와 라벨을 만들어 학습하면서 점점 똑똑해지는 것입니다. 어떻게 이런 일이 가능할까요?
[책을 많이 읽은 AI, 국어 시험도 잘 본다.]
기나긴 문서와 매뉴얼을 읽기가 귀찮았던 AI 개발자가 궁금한 내용을 물어보면 답변을 찾아주는 인공지능을 만들기로 결심했습니다. 자연어로 질문을 던지면 기계가 문서를 읽고 알아서 답변을 찾아주는 것입니다. 그런데 기계가 말을 배우려니 처음부터 배워야 할 것이 너무 많습니다.
단어가 어떤 뜻인지, 무엇을 물어보는 건지, 문서에서 답변을 찾을 수 있기는 한 건지 등, 이 모든 것을 학습하려면 정말 많은 질문과 답변 데이터가 필요할 것 같습니다. 인공지능이 처음부터 라벨링 데이터를 이용해 질문에 대한 답을 찾아내는 방법을 배우는 대신, 수많은 텍스트를 읽으며 단어와 문맥의 의미를 파악하는 것부터 배우도록 하면 어떨까요?
언어학적 특성을 알고 있는 모델은 나중에 질문-답변 데이터를 통해 답변을 찾아내는 방법을 조금만 더 학습하면, 문제를 잘 풀어낼 수 있을 것 같습니다. 책을 많이 읽은 아이가 나중에 국어 시험도 쉽게 푸는 것처럼 말입니다.
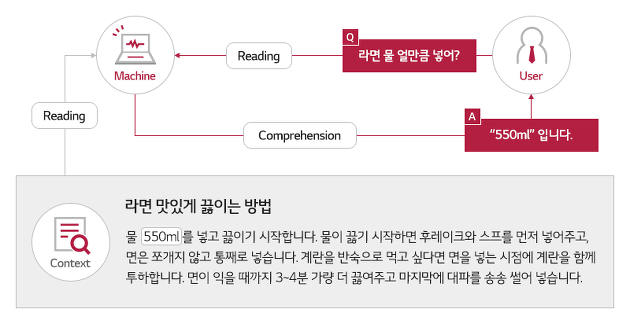
구체적으로 인공지능은 가용한 수많은 텍스트를 사용해 두 가지 태스크를 통해 스스로 공부하는 자기 지도 학습을 수행할 것입니다. 첫 번째 태스크는 <빈칸 맞추기>입니다. 예를 들면 아래와 같습니다.
- 출출한데 (_) 시켜 먹을까?
- 집에만 있었더니 10 (_)나 늘었다.
이처럼 문장에서 빈칸에 들어가는 단어를 맞추는 방식입니다. 우리가 영어 단어를 공부하기 위해 손가락으로 단어를 가리고 단어를 생각하는 연습을 하는 것과 비슷하네요. 위키피디아, 뉴스 등 세상에 존재하는 수많은 텍스트에 대해 빈칸 맞추기 태스크를 수행함으로써 모델은 단어와 문맥상의 의미뿐만 아니라 일반 상식을 비롯한 언어학적 지식을 습득합니다.
두 번째는 텍스트가 이어지는 문맥인지, 아닌지를 판별하는 <다음 문장 예측> 태스크입니다.
- 오늘은 남반구에 있는 친구네 마을에 놀러 갔다. / 그 곳에서 희귀 물고기를 낚았다! ▶ 다음 문장 O
- 오늘은 남반구에 있는 친구네 마을에 놀러 갔다. / 다음 집에 우유를 배달하기 위해 자전거에 올랐다 ▶ 다음 문장 X
주어진 두 텍스트가 연결된 문단인지 아닌지 판단하는 태스크를 통해 모델은 문맥적인 일관성에 대해 학습합니다. 중요한 것은 이러한 지도 학습 과정에 있어 사람의 라벨링이 필요하지 않다는 점입니다.

기계가 두 문장을 이어지는 문단에서 샘플링했다면 다음 문장으로, 서로 다른 두 문단에서 샘플링했다면 다음 문장이 아닌 것으로 라벨링을 하고, 태스크를 수행하며 언어학적인 특성을 학습하면 됩니다.
이렇게 수많은 텍스트를 이용해 자기 지도 학습을 수행한 모델을 하위 태스크에 대해 지도 학습으로 조금만 더 학습하면 새로운 태스크에 대해 좋은 성능을 내게 됩니다.
자기 지도 학습의 핵심은 ‘사전 학습 과제’ 아이디어 찾기
위에서 소개해 드린 자기 지도 학습 방법은 2018년에 발표되어 자연어 AI 연구의 지평을 바꿔놓은 BERT라는 알고리즘입니다.
빈칸 맞추기와 다음 문장 예측 태스크를 자기 지도 학습으로 학습한 BERT는 문장 유사도 판별 등 9개의 태스크를 포함해 언어 AI 연구의 수능이라고 할 수 있는 GLUE 리더보드에서 최고 성능을 달성했습니다. 그리고 질의응답 태스크에서도 기존 알고리즘과의 격차를 크게 벌리며 1등을 차지했습니다. 자기 지도 학습의 힘을 보여준 사례입니다.
이미지 AI를 만들 때도 자기 지도 학습을 활용할 수 있을까요? 모델이 이미지의 특성을 잘 파악할 수 있는 과제를 고안하고, 모델을 학습시키면 가능합니다. 간단하게는 주어진 이미지를 임의로 0도, 90도, 180도, 270도로 회전한 다음 회전한 각도를 맞추게 하는 사전 학습 과제를 생각해볼 수 있습니다.
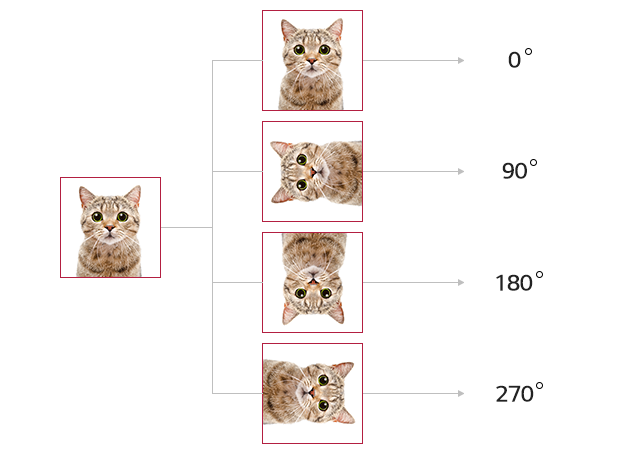
이외에도 이미지에 빈칸을 뚫어 놓고 채우기, 직소 퍼즐 맞추기, 색칠 시키기 등 다양한 과제를 통해 모델은 이미지에서 중요한 특징을 추출하는 법을 학습할 수 있습니다.
이렇게 실제 수행하려는 태스크가 아닌 모델을 사전 학습시키는 데에 사용하는 과제를 pretext 태스크라고 부릅니다. 그리고 자기 지도 학습의 핵심은 바로 이 pretext 태스크를 잘 고안해 모델이 이미지 혹은 자연어에 대한 고품질의 특성 벡터를 추출하는 법을 학습하도록 하는 데에 있습니다.
AI의 데이터 기근을 완화하다
요약하자면 자기 지도 학습은 라벨이 없는 수많은 코퍼스, 수만 장의 이미지를 활용해 기계가 스스로 글을 잘 읽는 방법, 사진을 이해하는 방법을 공부하는 알고리즘입니다. 1초에 수만 장의 사진과 SNS 글 등이 생겨나는 요즘, 자기 지도 학습은 AI가 발전할 수 있는 자연스럽고 좋은 방법입니다.

좋은 인공지능 모델을 개발하기 위해 해당 도메인에 대한 많은 데이터가 필요하다는 것은 지금까지 AI 모델 학습에 있어 현실적인 병목으로 작용해왔습니다. 하지만 자기 지도 학습은 넘쳐나는 원시 데이터를 활용해 모델이 좋은 특성을 추출하는 법을 배우고, 이를 새로운 태스크에 적용함으로써 데이터가 적은 분야에 대해서도 좋은 성능을 낼 가능성을 열어주었습니다.
글 l LG CNS AI빅데이터연구소
참고 자료
<논문>
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (https://arxiv.org/abs/1810.04805)
- Visualizing and Understanding the Effectiveness of BERT (https://arxiv.org/pdf/1908.05620.pdf)
- UNSUPERVISED REPRESENTATION LEARNING BY PREDICTING IMAGE ROTATIONS (https://arxiv.org/pdf/1803.07728.pdf)
<사이트>
- 깃허브 – https://lilianweng.github.io/lil-log/2019/11/10/self-supervised-learning.html
- https://towardsdatascience.com/self-supervised-learning-and-the-quest-for-reducing-labeled-data-in-deep-learning-db59a563e25b
- https://paperswithcode.com/sota/image-classification-on-imagenet


