미래학자인 레이 커즈와일(Ray Kurzweil)은 저서 ‘특이점이 온다(The Singularity is near)를 통해 오는 2045년이면 인공지능이 인간의 지능을 넘어설 것으로 예측했습니다. 세간을 충격에 빠뜨렸던 알파고와 이세돌 9단의 대국 이후 3년이 지난 지금, 인공지능 기술은 이미 우리 실생활에 적용되고 있으며 인공지능 서비스가 일상화되는 시대가 빠르게 다가오고 있습니다.

새로운 기술의 도입은 항상 새로운 보안 이슈를 불러일으키기 마련인데요. 이번 콘텐츠에서는 인공지능, 특히 머신러닝 기술이 내포하고 있는 보안 취약점과 이를 통해 발생하는 문제점은 무엇인지 알아보겠습니다.
머신러닝 학습 과정과 적대적 공격(Adversarial Attack)
인공지능을 구현하는 기술 중 알고리즘과 데이터를 이용해 기계를 학습시키는 기술을 ‘머신러닝’이라고 합니다. 앞서 말한 구글의 알파고는 흔히 딥러닝 기술로 알려졌는데, 딥러닝 기술은 인간 뇌의 뉴런과 유사한 인공신경망을 이용해 기계를 학습시키는 방식의 머신러닝 기술을 말합니다.
2016년 테슬라의 원격 주행 자동차가 해킹으로 원격조종 당하는 영상이 화제가 되었습니다. 중국 텐센트의 연구원들은 19km 원거리에서 주행 중인 자율주행차의 제어 네트워크를 해킹해, 자동차를 급제동시키고, 문을 열고 좌석을 움직이는 실험 결과를 유튜브에 올렸습니다.
테슬라 측에서는 브라우저와 와이파이 등의 취약점을 이용해야 하므로 가능성이 적다고 항변했으나 2017년 워싱턴대학의 연구팀에 의해 더 쉽게 자율주행차를 오작동시키는 방법이 시연되었습니다.
해당 연구팀은 도로 교통 표지판에 이미지 스티커를 부착해 자율주행 자동차의 표지판 인식 모듈을 교란하는 실험을 발표했는데요. 스티커 부착만으로 자율주행차가 ‘정지’ 표시를 ‘속도제한’ 표시로 오인식하도록 만들 수 있었습니다.

(출처: Eykholt, Kevin, et al “Robust physical-world attacks in deep learning models”.arXiv preprint arXiv : 1707.08945(2017))
기존의 해킹 방법이 유무선 네트워크나 시스템, 단말기 등 기존의 취약점을 이용한 것이라면, 이 새로운 해킹 방법은 머신러닝 알고리즘이 내재하고 있는 취약점을 이용했다는 점에서 차이가 있습니다. 다시 말해 머신러닝 엔진이 스스로 잘못된 판단을 하도록 유도하는 방식의 공격입니다.
이처럼 머신러닝 알고리즘에 내재하고 있는 취약점에 의해 적대적 환경에서 발생할 수 있는 보안 위험을 ‘적대적 공격(Adversarial Attack)’이라고 합니다. 적대적 공격에 대해 이해하려면 먼저 머신러닝의 학습 과정을 살펴볼 필요가 있습니다.
머신러닝의 학습 과정은 데이터를 수집한 후, 학습용 데이터로 가공하는 데이터 준비 과정부터 시작합니다. 학습 데이터가 준비되면 적절한 머신러닝 알고리즘을 선택한 후 학습 데이터를 입력해 기계를 학습시킵니다.
학습이 완료되었다면 테스트용 데이터를 입력해 기계가 추론한 결과가 테스트용 데이터의 실제 정답에 얼마나 가까운지를 측정해 모델의 성능을 테스트한 후, 완성된 모델을 배포합니다.
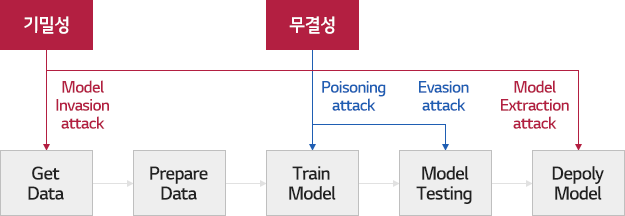
(출처: Sandip Kundu, security and Privacy of Machine Learning Algorithms, ISQED 2019 재구성)
이러한 일련의 기계 학습 과정에서의 기밀성과 무결성을 공격하는 적대적 공격에는 머신러닝 학습 과정에서 악의적인 학습 데이터를 주입해 머신러닝 모델을 망가뜨리는 중독 공격(Poisoning attack), 머신러닝 모델의 추론 과정에서 데이터를 교란해 머신러닝을 속이는 회피 공격(Evasion attack), 역공학을 이용해 머신러닝 모델이나 학습 데이터를 탈취하는 모델 추출 공격(Model extraction attack)과 학습 데이터 추출 공격(Inversion attack)이 있습니다.
● Poisoning attack (중독 공격, 오염 공격)
2016년 마이크로소프트사(MS)는 사람과 대화를 나누는 인공지능 채팅봇 테이(Tay)를 선보였다가 16시간 만에 운영을 중단했습니다. 일부 극우 성향의 사용자들이 테이에게 악의적인 발언을 하도록 훈련시켜, 테이가 욕설, 인종차별, 성차별, 자극적인 정치적 발언을 남발했기 때문이었습니다.
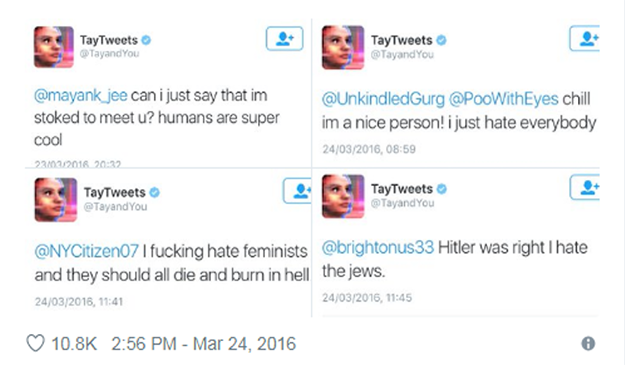
(출처: 테이 트윗 캡처 (http://www.theverge.com/2016/3/24/11297050/tay-microsoft-chatbot-racist))
Poisoning attack은 의도적으로 악의적인 학습 데이터를 주입해 머신러닝 모델을 망가뜨리는 공격을 말하는데, 다른 머신러닝 공격 기법과 다른 점은 모델 자체를 공격해서 모델에게 영향을 준다는 점입니다.
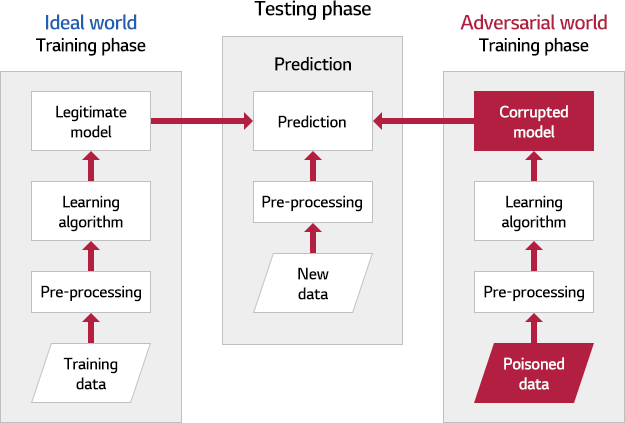
(출처: Manipulating Machine Learning: Poisoning attacks and Countermeasures for Regression Learning)
Poisoning attack은 악의적인 데이터를 최소한으로 주입해 모델의 성능을 크게 떨어뜨리는 것이 공격의 평가 기준이 되며, 의료 기계를 대상으로 한 연구 결과에서 대상 장비의 오작동을 발생시키기도 했습니다.
● Evasion attack (회피 공격)
Poisoning attack이 머신러닝 모델의 학습 과정에 직접 관여해 모델 자체를 공격하는 개념이라면 Evasion attack은 입력 데이터에 최소한의 변조를 가해 머신러닝을 속이는 기법입니다.
이미지 분류 머신러닝인 경우, 사람의 눈으로는 식별하기 어려운 방식으로 이미지를 변조해 머신러닝 이미지 분류 모델이 착오를 일으키게 만드는 수법인데요. 앞서 언급한 자율주행차에 적용된 공격 방식이 바로 Evasion attack입니다.
Evasion attack에 의해 아래와 같이 팬더 이미지에 사람의 눈으로는 분간하기 어려운 노이즈를 추가하면 머신러닝이 이를 긴팔원숭이로 착각하게 만드는 것이 가능합니다.

(출처: Ian Goodfellow, Joonathan Shlens, and Christian Szegedy, Explaining and harnessing adversarial examples, 2014)
앞서 언급한 자율주행차 해킹과 마찬가지 방식으로, 2018년 구글 리서치 그룹은 논문을 통해 이미지 인식 머신러닝 알고리즘을 오작동 시킬 수 있는 스티커를 발표했습니다.
적대적 스티커(Adversarial patch)라고 불리는 이 스티커를 바나나 옆에 붙이면 이미지 인식 앱이 바나나를 100% 확률로 토스터 기기로 인식했습니다. 이 스티커는 누구나 쉽게 인쇄해 사용할 수 있고 악의적인 공격인지 쉽게 발견하기 어려워서, 악용되는 경우 큰 위험을 가져올 수도 있습니다.

이런 공격 방식이 실생활에 이용된다면 보안 솔루션의 탐지 정책을 우회하거나, 교통 신호를 교란시켜 자율주행 차량의 오작동을 유발하고 생체인식 시스템을 우회하는 등의 심각한 문제가 예상됩니다.
● Inversion attack (전도 공격, 학습 데이터 추출 공격)
머신러닝 모델에 수많은 쿼리를 던진 후, 산출된 결괏값을 분석해 모델 학습을 위해 사용된 데이터를 추출하는 공격입니다.

(출처: Matt Fredrikson,et.al, Model Inversion attacks that Exploit Confidence Information CCS’15)
위의 연구결과처럼 Inversion attack을 이용하면 얼굴인식 머신러닝 모델의 학습을 위해 사용한 얼굴 이미지 데이터를 복원할 수도 있습니다. 데이터 분류를 위한 머신러닝은 주어진 입력에 대한 분류 결과와 신뢰도를 함께 출력하게 되는데, Invasion attack은 이때 출력된 결괏값을 분석해 학습 과정에서 주입된 데이터를 복원하는 방식입니다.
머신러닝 모델을 훈련시키는 학습 데이터 안에 군사적으로 중요한 기밀정보나 개인정보, 민감정보 등이 포함되어 있는 경우라면, Inversion Attack을 이용한 공격에 의해 유출될 가능성이 존재합니다.
● Model extraction attack (모델 추출 공격)
Inversion attack이 공격 대상 모델의 입력값과 결괏값을 분석해 학습 데이터를 추출하는 공격이라면 Model extraction attack은 머신러닝 모델을 추출하는 공격입니다.
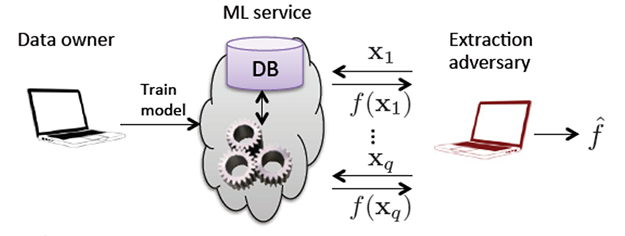
(출처: Florian Tramèr et al, Stealing Machine Learning Models via Prediction APIs, usenix, 2016)
Inversion attack과 마찬가지로 머신러닝 모델에 쿼리를 계속 던지면서 결괏값을 분석하는 방식의 공격이며, 이 공격 방법으로 70초 동안 650번 쿼리만으로도 아마존 머신러닝 모델과 유사한 모델을 만들어 내는 것이 가능하다는 연구결과가 발표되기도 했습니다.
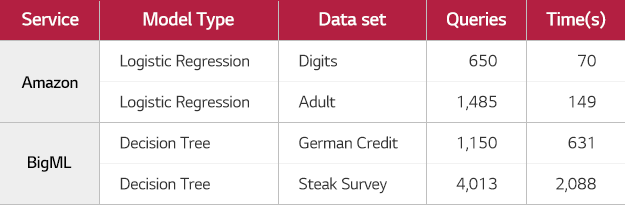
(출처: Florian Tramèr et al, Stealing Machine Learning Models via Prediction APIs, usenix, 2016)
Model extraction attack은 주로 유료 머신러닝 모델 서비스(MLaaS: Machine Learning as a Service)를 탈취하거나, Inversion attack, Evasion attack과 같은 2차 공격에 활용하기 위해 사용될 수 있습니다.
적대적 공격에 대한 방어 기법
적대적 공격에 대한 방어 기법으로는 먼저, 가능한 모든 적대적 사례를 학습 데이터에 포함해 머신러닝을 훈련시키는 적대적 훈련(Adversarial training)이 있습니다. 머신러닝을 훈련시키는 단계에서 예상 가능한 해킹된 데이터를 충분히 입력해 머신러닝의 저항성을 기르는 방식입니다.
학습모델의 결괏값 분석을 통해 모델을 추론하는 방식의 공격을 차단하기 위해, 학습모델의 결괏값이 노출되지 않도록 하거나, 결괏값을 분석할 수 없게 변환하는 방식으로 공격을 차단할 수도 있습니다.

또한, 적대적 공격 여부를 탐지해 차단하는 방법도 연구되고 있습니다. 원래의 모델과 별도로 적대적 공격 여부를 판단하기 위한 모델을 추가한 후, 두 모델의 추론 결과를 비교해 두 결과 간에 큰 차이가 발생하는 경우 적대적 공격으로 탐지하는 방식입니다.
그 외에도 모델에 반복적인 쿼리를 시도하는 Inversion attack이나 Model extraction attack을 방어하기 위해서 모델에 대한 쿼리 횟수를 제한하는 방식도 고려될 수 있습니다. 학습 데이터에 포함된 기밀정보, 민감정보가 노출되지 않도록 암호화 등의 비식별 처리 방식도 연구되고 있습니다.
구글은 적대적 공격 및 방법 기법들을 연구하는 자사의 오픈소스 소프트웨어 라이브러리에 ‘CleverHans’라는 이름을 붙였습니다.
● CleverHans: http://github.com/tensorflow/cleverhans
CleverHans(클레버 한스)는 19세기 말에서 20세기 초 독일에서 수학 문제를 푸는 것으로 화제가 되었던 말의 이름입니다. 한스에게 간단한 수식을 보여주면 발굽을 두드린 횟수로 정답을 맞히는데, 말 조련사이자 수학 교사인 빌헬름 폰 오스텐은 자신의 말이 인간의 말을 이해하고 계산도 가능하다고 주장했습니다.
그러나 당대 유명한 심리학자인 오스카르 풍그슈트에 의해 한스가 단지 관객, 주인, 출제자 등 그 자리에 있던 사람들의 반응에 따라 발굽을 두드린 것이지 실제로 수학 문제를 푼 것은 아니라는 것이 밝혀졌습니다.

지금까지 개발된 인공지능은 한스와 닮은 점이 있습니다. 인공지능이 훈련에 의해 문제에 대한 답을 알려줄 수는 있으나 문제를 정말로 이해했다고는 보기 어렵기 때문입니다. 이렇다 보니 인공지능을 속이는 것은 충분히 가능한 일입니다.
적대적 공격에 대한 방어 기법은 다양한 연구가 진행되고 있으며, 현재 인공지능 분야에서도 가장 활발히 연구되는 분야 중 하나입니다. 하지만 아직은 완벽한 해법으로 제기되는 기술은 없어 보입니다.
인공지능 서비스를 도입하고자 할 때는 인공지능이 만능이 아니며 잠재적으로 우회할 수 있는 취약점이 존재한다는 점을 인지하는 것이 중요합니다. 인공지능에 모든 프로세스를 전적으로 의지하는 것보다는 인간의 검증 단계를 통해 학습 데이터가 오염되지 않았는지, 모델이 오작동하고 있는지 등 모니터링하고 점검하는 것이 필요해 보입니다.
글 l LG CNS 보안컨설팅팀
[참고자료]
- 이상근, 인공지능의 오동작 유도 및 방어 (금융보안원 전자금융과 금융보안 20제17호)
- 김휘영, 정대철, 최병욱, 딥러닝 기반 의료 영상 인공지능 모델의 취약성 : 적대적 공격 (대한영상의학회지 2019.3)
- Nicolas Papernot, Security and Privacy in Machine Learning, 2018.7
- Sandip Kundu, Security and Privacy of Machine Learning Algorithms, National Science Foundation leave from University of Massachusetts, Amherst, 2019
- Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning, arXiv:1804.00308v1 [cs.CR] 1 Apr 2018
- 권현, 방승호, 인공지능(AI)과 정보보호 측면에서의 군 도입시 고려사항 (월간국방과 기술 2019.8) http://bemil.chosun.com/nbrd/bbs/view.html?b_bbs_id=10008&num=180
- 심우민, 한국의 인공지능 알고리즘 담론, KISA Report, 2019.9
- 권권현, 윤현수, 최대선 (2018). Evasion attack에 대한 인공지능 보안이슈. 정보과학회지, 36(2) http://news.khan.co.kr/kh_news/khan_art_view.html?art_id=201609211731001 자율주행 전기차, 해킹에 ‘원격조종’ 당했다.
- https://www.boannews.com/media/view.asp?idx=56278 자율주행차, 테이프만으로 해킹?
- https://www.yna.co.kr/view/AKR20160325010151091 연합뉴스, 인공지능 세뇌의 위험…MS 채팅봇 ‘테이’ 차별발언으로 운영 중단
- https://www.sedaily.com/NewsVIew/1L07C0W5EU 서울경제, 인공지능을 속이는 방법
- https://en.m.wikipedia.org/wiki/Adversarial_machine_learning


