딥러닝 기반 알고리즘들은 충분한 양의 데이터로 학습한다면 좋은 성능을 낸다고 알려져 있습니다. 딥러닝 알고리즘은 이미지 분류, 객체 탐지, 영상 분할 등 여러 가지 분야에서 이미 사람보다 더욱 정확하고 빠르게 동작하고 있습니다. 이러한 딥러닝 알고리즘을 연구하고 개발하는 과정에서 딥러닝 알고리즘을 효과적으로 학습시키는 방법론에 관해서 연구가 많이 진행되었습니다.

더 많은 데이터로 학습한 딥러닝 모델에서 전달받은 정보를 활용해 학습하는 기법인 지식 증류(Knowledge Distillation). 다른 데이터들로 공부한 것을 토대로 효과적으로 학습하는 전이 학습(Transfer Learning). 이 외에도 여러 가지 방면의 연구가 많이 진행되었지만, 오늘 중점적으로 다룰 방법론은 능동 학습(Active Learning)입니다.
능동 학습이란?
능동 학습은 학습 데이터 중 성능 향상에 효과적인 데이터들을 선별한 후, 선별한 데이터를 활용해 학습을 진행하는 방법입니다.
학습 데이터를 확보하는 과정은 데이터를 수집하는 것과 수집한 데이터에 유의미한 라벨을 붙이는 것으로 구성되어 있습니다. 일반적으로 유의미한 라벨을 붙이는 것이 데이터를 수집하는 것에 비해 시간과 비용이 많이 소요됩니다.
그렇기에 같은 수의 데이터에 라벨을 붙여서 학습할 때, 성능이 높게 나올 수 있도록 데이터를 선별한다면 효과적으로 딥러닝 모델을 학습할 수 있습니다. 이렇게 효과적인 데이터를 선별하는 방법을 연구하는 것이 능동 학습입니다.
능동 학습의 구조는 크게 4단계로 구성되어 있습니다.
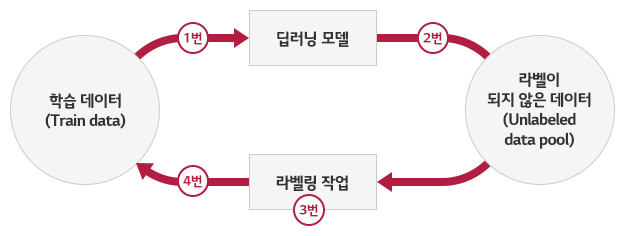
1번) 초기 학습 데이터를 이용해 딥러닝 모델을 학습합니다.
2번) 라벨이 되지 않은 데이터 중 모델에게 도움이 되는 데이터를 선별합니다.
3번) 선별한 데이터에 사람이 분류해 라벨을 표기합니다.
4번) 선별한 데이터를 기존 학습 데이터와 병합한 후, 딥러닝 모델을 학습합니다.
목표하는 성능이 나올 때까지 위의 방법을 반복해 수행합니다. 그렇다면 일반적인 지도 학습과 능동 학습에는 어떠한 차이점이 있을까요? 간단한 예시를 통해 알아보겠습니다.
수학 공부를 하는 학생 A와 B가 있다고 생각해봅시다. A와 B는 각각 수학 문제가 100개가 포함된 서로 다른 문제집 10권을 가지고 있습니다. 총 500문제를 풀고 난 후, A와 B의 수학 실력을 다시 비교할 예정입니다.
#A의 학습 계획
A는 문제집 5권을 임의로 뽑아서 안에 있는 문제를 전부 풀 것입니다.
#B의 학습 계획
B는 문제집 3권을 임의로 뽑아서 안에 있는 문제를 전부 풀 것입니다.
풀었던 문제집 3권에서 많이 틀리는 유형들을 기록합니다.
남은 7권의 문제집에서 많이 틀리는 유형들에 해당하는 200문제를 추가로 풀었습니다.
A와 B의 학습 방법이 위와 같을 때, 누가 더 효과적으로 학습했을까요?
일반적으로 B가 더 효과적으로 학습했다고 말할 수 있습니다. 풀 수 있는 문제가 500개로 제한된 상황이라면, 많이 틀리는 유형들의 문제를 중점적으로 공부해 틀리지 않도록 대비하는 것이 효과적인 방법이기 때문입니다.
A의 학습 계획이 일반적인 지도 학습 방법이며, B의 학습 계획이 능동 학습이라고 말할 수 있습니다. 위의 예시와 같이 풀 수 있는 문제의 수가 제한된 것처럼, 라벨링 할 수 있는 데이터의 수가 제한된 상황에서는 성능 향상에 효과적인 데이터를 선별하는 과정이 중요하게 됩니다.
능동 학습의 연구 방향
능동 학습에서 중점적으로 연구가 진행되는 부분은 성능 향상에 효과적인 데이터를 선별하는 방법입니다. 이러한 데이터 선별 방법을 ‘Query Strategy’라고 합니다. Active Learning의 연구는 ‘Query Strategy’를 어떻게 하느냐에 따라서 중점적으로 맞춰져 있습니다.

- 학습된 모델의 판정 값을 기반으로 뽑는 Uncertainty Sampling.
- 여러 개의 모델을 동시에 학습시키면서 많은 모델이 틀리는 데이터를 선별하는 Query by committee.
- 데이터가 학습 데이터로 추가될 때, 학습된 모델이 가장 많이 변화하는 데이터를 선별하는 Expected Impact.
- 데이터가 밀집된 지역의 데이터들을 선별하는 Density weighted method.
- 데이터들의 최대한 고르게 뽑아서 분포를 대표할 수 있도록 데이터들을 선별하는 Core-set approach.
이 외에도 계속해서 여러 가지 다양한 방법들이 연구되고 있습니다.
능동 학습의 의의
인공지능 딥러닝 기술에 활용할 수 있는 학습 데이터는 역설적이게도 많이 있지만, 많이 없습니다. 학습 데이터 자체는 손쉽게 대량으로 확보할 수 있습니다. 그러나 학습 데이터에 모델이 사용할 수 있는 유의미한 라벨 정보가 포함된 데이터는 정말 극소수입니다.
풀고자 하는 문제에 대한 라벨 정보를 새로 만드는 것은 시간 및 비용에 의해 현실적으로 불가능한 경우 또한 많습니다. 이러한 어려움을 조금이라도 해결하기 위해 연구되어온 방법이 능동 학습입니다.

능동 학습이라는 기술 하나로는 라벨 정보에 관련된 모든 문제를 해결할 수는 없습니다. 필요한 라벨 정보의 개수가 줄어들 수는 있지만, 결국은 사람이 직접 라벨 정보를 만들어주어야 하기 때문입니다. 그러나 능동 학습의 연구 성과는 인공지능 딥러닝 기술이 효율적으로 접목될 새로운 가능성을 열어주었습니다.
글 l LG CNS AI빅데이터연구소
[참고 자료]
<논문>
- Active Learning for Convolutional Neural Networks: A Core-Set Approach
- https://arxiv.org/abs/1708.00489
<사이트>
- https://www.kdnuggets.com/2018/10/introduction-active-learning.html
- https://towardsdatascience.com/active-learning-tutorial-57c3398e34d


