
Intro
Batch(이하 배치)는 처리해야 할 작업을 모아 일괄 처리하는 작업을 의미합니다.
배치는 특정 시간마다 실행할 수 있도록 스케줄링하고 설정한 시간에 한꺼번에 작업을 처리하게 되는데요. 실시간 처리 방식이 아니기 때문에 빠른 응답이 필요 없는 서비스에 활용하기 적합합니다.
하나의 프로젝트 안에는 크고 작은 다양한 시스템들이 있어, 각 시스템의 특징에 맞게 배치를 구성해 운영해야 합니다.
하지만, 시스템이 만들어진 시기나 프로그래밍 언어, 시스템 환경에 따라 배치의 구성이 많이 달라지는데요.
이때, 배치의 특성상 Background에서 실행되는 경우가 많아 배치 실패가 발생해도 즉시 알아차리지 못하는 경우가 많습니다.
배치 오류로 인해 큰 문제가 발생하기도 하고, 계속된 실패로 문제상황이 방치되는 경우도 있습니다.
이번 글에선 배치 구성을 하며 겪었던 시행착오와 해결방안을 공유해보겠습니다.
짧은 주기 배치에 대한 고민
배치 간격이 10초에 한 번, 30초에 한 번 정도로 실행되는 경우 ‘짧은 배치 주기’에 적합한 아키텍처를 고민해야 합니다.
짧은 주기 배치는 near Realtime 처리를 필요로 하는 업무일 가능성이 크기 때문에 배치가 아닌 실시간으로 처리할 수 있는 방안을 고민하는 것이 우선돼야 합니다.
Kafka(분산 이벤트 스트리밍 플랫폼)와 같은 메시지 큐를 활용해 Event Driven(특정 이벤트에 반응해 동작을 변경하는 방식)으로 데이터를 처리할 수도 있습니다.
하지만 기존의 배치를 실시간 처리로 변경하려면, 데이터 송신 위치의 변경이 필요한데요. 송신 위치 변경이 불가능하다면 내부에서, 배치로 처리할 수밖에 없습니다.
1) 상시배치 컨테이너 구성(Batch on EKS)
일반적으로 많이 사용하는 EKS Fargate 환경을 사용해 배치를 구현해보겠습니다.
Fargate는 기동 시 약 60~90초의 시간이 필요하다는 제약사항이 있습니다.
모든 배치 Job(배치 작업 단위)을 각각의 Fargate 컨테이너로 Job을 실행하는 것은 비효율적이기 때문에 여러 개의 Job을 실행할 수 있는 상시배치용 컨테이너를 구성했습니다.
이 환경은 Fargate로 구성되지만, Job 실행을 위한 일회성 환경이 아닌 계속 유지되는 환경입니다.
짧은 주기로 실행되는 배치 Job을 동일한 Fargate 컨테이너에서 주기적으로 실행되도록 합니다.
Fargate가 유지되기 때문에, Startup 시간은 최초 1회만 필요로 하고 빠르게 Job을 실행할 수 있습니다.
단, 비용은 일반 Backend 서비스처럼 Fargate가 상시가동되는 비용이 발생합니다.
2) Java에서 Start 시 Resource 과다 사용 문제
배치로 Java를 사용할 때, Job 실행 시 각 Job간의 독립성을 보장하기 위해 Java 프로세스를 매번 새로 실행해야 한다는 문제가 있었습니다.
이로 인해 Java 프로세스를 시작할 때 CPU 사용량이 증가하며 리소스 낭비가 발생했는데요.
Java가 컴파일 단계(고수준 언어를 번역하는 과정)에서 JVM(Java Virtual Machine, 자바 가상 머신, Java를 실행하기 위한 가상 컴퓨터)에서 실행 가능한 바이트코드를 생성하고, 이후 런타임 때 JVM에서 바이트코드 로드 및 네이티브 실행 코드로 변환하기 때문에 CPU 사용량이 증가한 것입니다.
이러한 단계는 애플리케이션이 제대로 작동하는 데 필수적이나, 상당한 오버헤드가 발생하기 때문에 애플리케이션의 최초 실행도 느려지게 됩니다.
또한 Java의 Spring과 같은 Framework를 사용하면 로드 및 실행에 더 많은 시간이 소요됩니다.
Java는 장시간 사용할 경우 성능의 이익을 볼 수 있는 구조로 돼있어, 단기성 배치는 불리합니다.
여러 개의 배치 Job이 수시로 시작하고 정지하는 환경에선 CPU 사용량이 꾸준히 높게 유지되는 것을 확인할 수 있습니다.
Lambda 배치 구성
배치 Job간 독립성을 보장하면서 비용을 줄일 수 있는 방안으로 Lambda를 고려하게 되었고, 마침 Lambda SnapStart 기능이 서울 리전에서 사용할 수 있게 되어 짧은 주기 배치를 해결할 수 있었습니다.
1) Lambda 제약사항
먼저 배치를 구현하기에 부족한 부분이 없는지 Lambda의 제약사항을 확인해 보겠습니다.
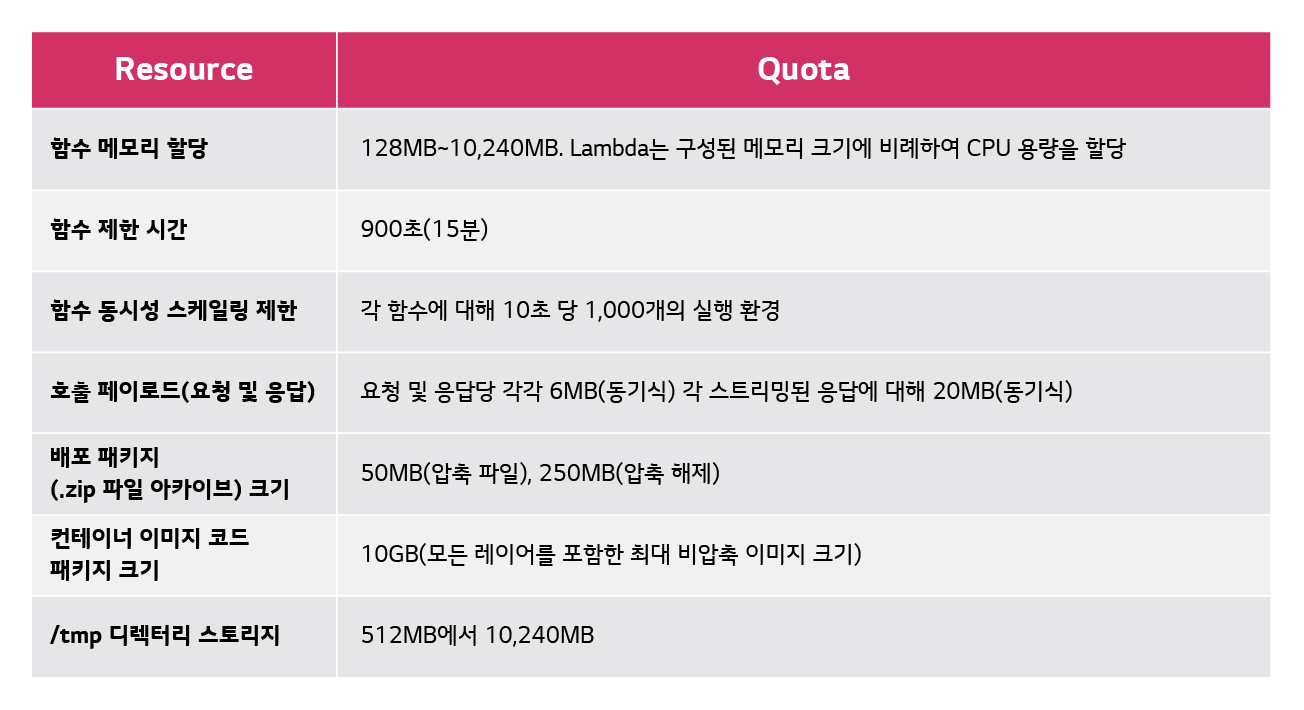
Lambda는 [표 1]과같이 배포 패키지 크기 및 스토리지, 메모리, 제한 시간(Timeout) 등의 제약사항이 있습니다.
짧은 주기 배치는 긴 시간 동안 실행하지 않기 때문에 제한 시간은 문제가 되지 않았고, 대량의 데이터 처리도 필요하지 않아 메모리 역시 충분합니다.
2) Lambda 장점
몇 가지 제약사항을 제외하면 Lambda는 배치로 사용하기에 훌륭한 서비스입니다.
Lambda 배치 구성 시 장점의 예로, 동시성 스케일링 보장 및 빠른 실행, 저비용, 관리 부담 절감 등이 있습니다. 아래에서 더 자세히 알아보겠습니다.
• 동시성 스케일링
대용량 데이터 처리 및 동시에 많은 Job을 처리해야 될 경우에는 급격하게 인스턴스를 늘려 병렬 처리를 해야 합니다.
Lambda를 사용한다면 자원을 10초당 1,000개씩 늘리는 것이 가능합니다.
별도의 설정 없이 Request 수에 따라 자동으로 자원이 늘어나고 줄어들어 편리하며, 비용 역시 사용한 만큼만 지불하기 때문에 휴지 인스턴스(idle instance, DB가 셧다운 된 상태)에 대해 고민하지 않아도 됩니다.
• 동시성 스케일링
Lambda는 실행시간과 요청 횟수, 메모리 크기에 따라 가격이 결정됩니다.
Lambda는 호출이 발생하고 실행 중인 시간 동안 과금 되기 때문에, 사용하지 않는 기간에는 비용이 발생하지 않습니다.
예시를 통해 확인해 보겠습니다.
• Lambda로 2GB 메모리를 사용하는 1초짜리 배치를 40만 건 실행할 경우, 약 $13가 발생
• Fargate로 0.25VCPU, 2GB 스펙의 컨테이너 1대를 한 달간 사용할 경우, $478가 발생
위의 예시로 알 수 있듯, Fargate에 비해 Lambda가 비용을 크게 절감할 수 있다는 것을 알 수 있습니다.
• 멱등성(Idempotent)
동일한 작업을 몇 번씩 수행해도 같은 결과를 얻을 때 멱등하다고 합니다.
Lambda는 Function as a Service라고도 불리는 Stateless(무상태, 클라이언트와 서버 관계에서 서버가 클라이언트 상태를 보존하지 않는 형태) 서비스입니다.
배치 Job을 Lambda로 실행하면, 각 Job은 완벽히 분리된 환경에서 동일한 Function을 사용해 처리하기 때문에 서로 간섭이 일어나지 않습니다.
그렇기 때문에 몇 번을 실행해도 동일한 결과를 보장합니다.
각 배치 Job의 독립성을 보장하면서 언제나 같은 상태를 유지할 수 있다는 것은 큰 장점입니다.
• 관리 부담 절감
서버가 있을 경우 각종 패치와 버전 업그레이드로 인해 관리 부담이 커집니다.
하지만 Lambda는 내부에서 주기적으로 패치, 업그레이드가 되기 때문에 개발자가 별도로 신경 쓸 필요가 없습니다.
갑작스럽게 트래픽이 증가하더라도 자동으로 자원을 추가 Provisioning(사용자가 요청한 IT 자원을 사용할 수 있는 상태로 준비하는 것)해 대응하고, 사용한 만큼만 비용을 부과하기 때문에 관리가 어렵지 않습니다.
즉, 개발자는 서버 관리에 대한 부담 없이 코드에만 집중할 수 있게 됩니다.
3) Lambda Java 배치
Lambda Snapstart
2022년 AWS re:invent에서 Lambda SnapStart 기능을 발표했습니다.
SnapStart는 Lambda의 사전 초기화된 스냅 샷을 생성하고, Cold Start(상품추천을 위한 데이터 정보가 충분하지 않아 해당 유저들에게 상품을 추천하지 못하는 상태)시 해당 스냅샷을 사용해 코드를 실행하는 기능입니다.
SnapStart를 활용하면, Java를 배치에 사용할 때 큰 단점이었던 초기 오버헤드를 해결할 수 있습니다.
또한 Cold Start 시간과 Lambda 실행시간을 단축해 사용 비용도 절감할 수 있습니다.
특히 Spring Framework처럼 Bootstrap 단계(시스템이 정상 동작하기까지 스스로 전개하는 과정)에서 많은 양의 처리가 필요할 경우엔 SnapStart를 필수로 사용해야 합니다.
하지만 SnapStart에도 제약사항이 있습니다. [그림 1] 내용을 참고해 보세요.

지원되는 런타임이 Java11 이상의 AWS 관리형 런타임으로 제한돼 있고, Provisioning된 동시성, arm64 아키텍처, Amazon EFS 또는 512MB를 초과하는 임시 스토리지는 지원하지 않습니다.
Lambda에서 Spring Boot 구성하기
Lambda SnapStart를 사용하면 Spring Boot를 사용하는 것도 부담되지 않습니다.
Spring Boot를 사용하면 개발자들에게 익숙한 코드를 사용할 수 있어 개발 생산성이 향상됩니다.
Spring Boot 구성을 위해 Lambda의 호출을 받을 수 있는 handleRequest(Lambda의 이벤트를 처리하는 Method) Method를 포함해 Lambda Handler Class를 추가로 구성해 주면 됩니다.
Spring Boot를 위한 handler를 전역변수(Global Variable, 어떤 변수 영역 내에서도 접근할 수 있는 변수)로 선언하고, 정의하는 코드는 Class의 생성자에 추가하면 됩니다.

4) 배치의 DB Connection Pool
Spring에서 많이 사용하는 hikariCP(Connection Pool의 종류)를 이용해 DB Connection Pool(웹 애플리케이션과 같은 다중 사용자 환경에서 DB 연결을 효율적으로 관리하기 위해 사용되는 기능)을 관리하고 있습니다.
Connection Pool은 Connection을 열고 닫을 때 발생하는 CPU, Memory, 네트워크 오버헤드를 줄이기 위해 다수의 Connection을 열린 상태로 유지하는 기능입니다.
일반적인 Backend Service(백엔드 인프라를 구축하고 관리하는 데 도움이 되는 클라우드 기반 시스템)에선 Connection Pool 사용이 일반적이지만, 배치에서는 DB Connection Pool이 정말 필요한지 고민해 봐야 합니다.
Connection Pool 제거
배치는 Immutable(값이 변하지 않는 상태)하게 구성하기 위해 Stateless 상태를 유지하는 것이 좋습니다.
Job 시작 시 다른 요청에서 사용했던 Connection을 재사용해 속도를 향상시킬 수 있지만 안전성을 해칠 수 있습니다.
Connection의 상태에 따라 에러가 발생하기도 합니다.
Lambda는 invoke(요청)가 발생할 때 내부적으로 컨테이너를 실행하고 요청을 처리합니다.
처리가 끝나면 해당 컨테이너를 일정 시간 동안 sleep 상태로 유지했다가 다른 요청이 들어오면 컨테이너를 재사용하게 됩니다.
Connection Pool을 유지하게 되면, 초기에 생성한 Connection이 실행시점에 유효하지 않는 경우가 생길 수 있습니다. 이로 인해 에러가 발생할 수 있고, 재처리를 진행해야 합니다
또한 배치 Job별로 Connection을 생성한 뒤 제거하지 않는다면, DB에도 큰 부담이 되는데요.
Connection Pool을 배치에서 사용해야 한다면 Job 시작 시 Connection을 생성하고 Job 종료 시 제거하는 전략이 적합합니다.
DB 연결이 많지 않다면 과감하게 Connection Pool을 생략하고, 필요할 때마다 Connection을 연결해 사용하는 것이 좋습니다.
RDS Proxy(클라이언트 애플리케이션과 데이터베이스 사이의 네트워크 트래픽을 처리하는 기술)
배치에서 DB 호출이 많고, 동시에 많은 Job이 실행된다면 DB의 Connection을 동시에 요청할 수 있습니다.
이런 경우, DB의 Connection 부족으로 인한 장애가 발생할 수 있는데요.
AWS RDS 또는 AuroraDB(완전 관리형 관계형 DB 엔진) 등의 DB를 사용한다면 RDS Proxy를 사용해 이 문제를 해결할 수 있습니다.
RDS Proxy는 애플리케이션을 대신해 Connection Pool을 구성하고, Connection을 공유해 DB의 부하를 줄일 수 있을 뿐 아니라 DB장애에 대한 애플리케이션의 복원력을 높일 수 있습니다.
RDS Proxy 사용 비용은 DB의 용량에 따라 부과됩니다.
Lambda 배치 환경에서의 Troubleshooting
1) Lambda invoke CLI 호출 시 두 번 호출되는 문제
Lambda invoke CLI 호출 시 두 번 호출되는 문제의 현상과 원인 해결 방법까지 알아보겠습니다.
• 현상
별도의 스케줄러에서 AWS CLI를 사용해 Lambda 배치를 실행했을 때 간혹 Lambda가 연속으로 두 번씩 호출되는 로그를 확인했습니다.
Lambda CLI의 리턴 로그상 한 번 실행된 것에 대한 로그만 있었기 때문에 Lambda가 어디서 호출된 것인지 알 수 없었습니다.
이후 로그를 분석해 보니 Lambda 실행시간이 1분이 넘어갈 때, 두 번째 실행이 되는 것을 발견했습니다.
중복 실행될 경우에 처음 실행한 Lambda가 종료되지 않고 새로운 Lambda가 실행되었습니다.
• 원인
AWS CLI의 기본 timeout은 60초입니다. CLI timeout이 발생하면 자동으로 CLI 명령이 다시 실행됩니다.
Lambda 배치의 실행기간이 길어서 CLI timeout 이내에 끝나지 않을 경우, 의도치 않게 동시에 여러 개의 Lambda 매치가 실행됩니다.
• 해결
AWS CLI명령에 [그림 3]처럼 옵션을 추가하고 초 단위로 시간을 지정해 timeout을 늘릴 수 있습니다.

Default read-timeout은 60초지만 0으로 설정할 경우, 제한 시간 없이 무제한 대기 상태가 됩니다.
Lambda의 최대 실행시간은 15분(500초)인데요. cli-read-timeout 시간을 900초보다 조금 더 크게 지정하면 Lambda의 최대 실행시간까지 대기하도록 설정이 가능합니다.
2) DB query 실행 시 에러 발생 “Connection is not available”
DB query 실행 시 발생하는 에러의 문제 현상과 원인 해결 방법까지 알아보겠습니다.
• 현상
DB query를 실행하면 일정 시간 동안 대기하다 끊기는 현상이 종종 발생했습니다.
에러가 발생한 경우, 일정 시간 동안 동일한 유형의 에러가 발생했는데요. 시간이 지난 후, 에러가 안 나는 시점부터는 배치가 성공적으로 수행됐습니다.
에러가 발생하는 시점에 DB와 네트워크는 모두 정상이었습니다.
하지만 에러가 발생했을 땐 [그림 4]와 같이 몇 가지 유형의 로그가 섞여 있었습니다.

• 원인
기존에는 HikariCP를 이용하여 Connection Pool을 관리하고 있었습니다. Idle Timeout은 default 값인 10분, maxLifetime은 default 값인 30분이 적용된 상태였습니다.
Lambda가 실행되고 Lambda instance가 장시간 sleep상태(5분 이상)였다가 Lambda instance가 재사용될 경우 이와 같은 현상이 발생했습니다.
이러한 현상은 Connection Pool의 connection이 장시간 idle 상태였다가 다시 연결을 시도할 때, 서버측connection이 이미 close 된 상태이기 때문에 에러가 발생하는 것으로 추측할 수 있습니다.
• 해결
해당 문제는 HikariCP maxLifetime 설정을 최소값인 30초로 설정해 해결할 수 있습니다.
배치에서는 Connection Pool을 사용하지 않거나 Connection maxLifetime, IDLETIMEOUT 등을 최소 시간으로 유지해 비정상 connection 상태가 되는 것을 막아야 합니다.
RDS Proxy를 사용할 수 있다면 RDS Proxy를 적용해 Connection Pool을 관리하는 것이 더욱 효율적일 것입니다.



