지난 시간에는 사람이 평소에 사용하는 자연스러운 표현 그대로 제공해도 기계가 알아들 수 있도록 하는 자연어 이해 즉, ‘NLU(Natural Language Understanding)’ 정의와 사용하는 기술에 대해 알아봤습니다.
● 인간의 언어를 이해하는 기계 – NLU: http://blog.lgcns.com/1672
이번 시간에는 NLU를 적용한 사례에 대해 알아보겠습니다.

NLU를 적용한 사례는?
① 문장 분류 사례
Sentence Classification은 주로 마케팅 및 제품 관리 분야에서 적용 사례가 등장하고 있으며, 소셜 미디어의 메시지나 온라인 고객 Q&A, 웹 사이트의 사용자 댓글 등에서 시장이나 제품에 대한 사용자의 반응을 파악하는데 활용되는 경우가 많습니다.
설문조사나 인터뷰처럼 인위적이고 제어된 데이터가 아닌 사용자의 직접적인 표현을 그대로 사용하기 때문에 사용자를 가장 잘 파악할 수 있는 지표로 주목받고 있는데요. Sentence Classification이 단독으로 활용되는 경우보다는 전처리 및 다른 분석 모델과 조합되어 최종 데이터 분석에 활용되는 경우가 대부분입니다.
● Sentiment Classification (감성 분류)
각종 미디어에서 수집한 데이터에 대해 종합적인 감성 분석을 진행하는 경우, 문장 단위의 극성(긍정, 부정 등) 탐지에 활용도가 높습니다. 좀 더 단순히 기업의 마케팅 도구로서 소셜 미디어에 등록되는 메시지에 Sentence Classification을 적용해 소비자의 피드백을 모니터링 하는 용도로 활용되기도 합니다. 제품 및 서비스에 대한 부정적인 의견이나 이슈를 실시간 확인하기도 하고, 업체의 활동이나 관련 이슈에 대한 대중의 반응을 측정합니다.
LG CNS의 사내벤처 danbee.ai에서 개발한 LG U+ 고객센터 챗봇은 Sentence Classification을 적용하여 고객의 메시지에 대한 감성 판단을 상담의 보조 자료로 활용하고 있습니다.
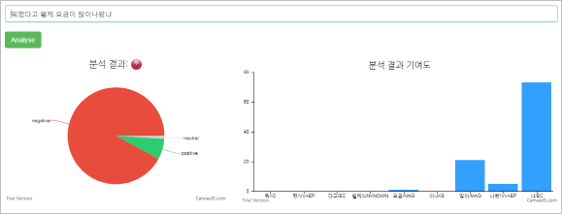
TIBUZZ 감성 분석 솔루션은 다양한 소셜 미디어의 데이터를 대상으로 텍스트 기반의 감성 분석을 도입하여 마케팅 도구로서의 활용도를 높이고 있습니다.
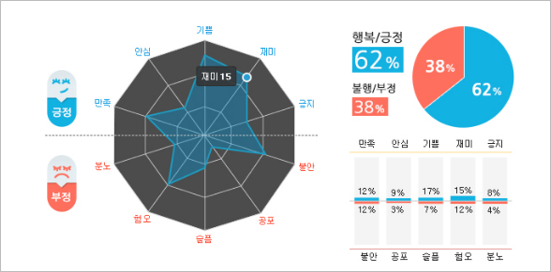
● Intent Classification (의도 분류)
Intent Classification의 대표적인 활용 분야는 사용자와 상호 소통하는 온라인 챗봇이 주류를 이루고 있으며 주로 온라인 커머스와 온라인 민원 서비스에서 도입이 늘어나는 추세입니다. 온라인 커머스 분야에서는 Intent Classification을 이용한 챗봇 자동 상담을 통해 제품 구매나 단순 질의를 사람의 개입 없이 처리합니다.
온라인 민원 서비스 분야에서는 정확한 민원 분류를 통해 처리 절차나 구비 서류를 안내해 주는 등 효과적인 민원 상담이 진행되도록 합니다.
Google의 챗봇 플랫폼인 Dialogflow에서는 데이터를 통한 학습 기반으로 채팅 Intent 분류를 하거나, 룰 기반과 하이브리드하게 적용할 수 있는 기능을 제공합니다.
Kitt.ai의 Chatflow나 Microsoft의 Luis.ai 같은 챗봇 플랫폼도 예시 문장을 입력하면 자동으로 패턴을 학습하여, 처음 보는 문장이 들어오더라도 가장 가능성 높은 질의 의도를 매칭하는데요. 유저와의 대화 이력으로 모델을 재학습시키는 기능이 있어서 지속적인 챗봇 성능 개선이 가능합니다.
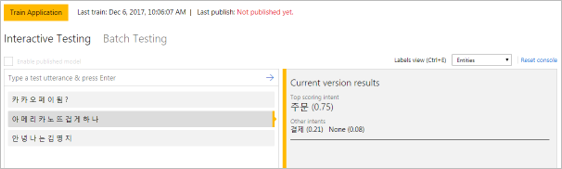
② Sequence To Sequence 사례
Sequence To Sequence는 번역, 질의응답, 문서 요약 등 주어진 문장과 관련하여 다른 문장을 대응시키는 모든 분야에 적용할 수 있습니다. 가장 활발히 연구 및 활용되는 분야는 기계번역(Machine Translation)이며, 이미 상용화 수준에 도달했습니다.
● Machine Translation(기계 번역)
인공신경망 기반의 Sequence To Sequence가 기계 번역 분야에 적용되면서 번역의 품질과 완성도가 눈에 띄게 개선되었습니다.
기계 번역 서비스의 대표적인 사례는 구글 번역(Google Translate) 서비스이며, 해당 서비스의 총괄 관리자인 바라크 투로프스키는 2016년 11월 기자 간담회에서 ‘신경망 기술 덕분에 기존 번역 오류의 55~85%를 감소시켰는데, 이는 지난 10년간의 성과를 단번에 뛰어넘는 결과’라고 밝힌 바 있습니다.
국내의 경우 네이버의 파파고(Papago) 서비스가 한국어, 영어, 중국어, 일본어 등 언어에 대해 기계 번역 서비스를 제공하고 있습니다.
● Text Summarization(문서 요약)
Sequence To Sequence를 이용한 문서 요약(Text Summarization) 등장 이전에도 단어 빈도수를 바탕으로 한 문서 요약 기술이 존재하였으나 Seq2Seq 도입 이후 품질과 완성도가 크게 향상되었습니다. 문서 요약 기술은 주로 논문이나 법조문, 특허문서와 같은 특정 분야의 전문 문서 요약이나 큐레이션을 위한 뉴스 기사 요약, 이메일 요약 등의 분야에서 높은 활용도가 기대됩니다.
Google은 텐서플로(Tensorflow) 라이브러리에 Sequence To Sequence 학습 기법을 적용하여 완성한 일명 ‘기사 헤드라인 작성 모델’을 선보였으며, 더 긴 글을 제대로 요약할 수 있도록 학습 방법에 관한 추가 연구를 진행 중입니다.
국내의 경우, 11월 말 도입된 네이버의 AI 요약봇(beta)은 뉴스 기사를 3문장 이내로 요약해 주는 기능을 선보였습니다.
③ Machine Reading Comprehension 사례
Machine Reading Comprehension은 인공신경망 도입 이후 활발히 연구가 진행 중인 분야지만 아직 상용화 수준의 성과는 등장하지 않았습니다.
마이크로소프트가 인수한 인공지능 기업 말루바(Maluuba)는 2016년 3월, 소설 ‘해리포터와 마법사의 돌’에 대한 무작위 질문에 대답할 수 있는 Machine Reading 시스템을 개발하여 선보인 바 있습니다. Machine Reading Comprehension이 잘 활용될 수 있는 분야 중 하나는 질의응답(Question Answering) 시스템이며 말루바는 현재 자동차, 가전기기 등의 사용 설명서를 이해하고 사용자의 질문에 대답할 수 있는 시스템의 개발을 진행 중입니다.
NLU의 기술 동향
① 더 단순한 전처리
딥러닝 기반의 NLU는 기존 방식의 수작업 Feature Engineering을 거의 하지 않습니다. 일반적으로 word 단위로 문장을 전처리하여 입력했다면, Character 단위로 문장을 입력하는 경향이 늘고 있으며, 성능에서도 기존보다 개선되는 효과가 있습니다.
한국어의 경우 어절이나 형태소보다는 음절이나 자모 단위로 학습시키곤 하는데요. 형태소도 사람이 인식하는 개념 단위이므로, 모델이 이를 인식할 수 있도록 End-to-End 학습을 시키자는 취지입니다.
또한, 형태소 분석, 의존 구문 분석, 개체명 분석을 이용한 전처리를 지양하고 단순히 음절 단위로 쪼갠 문장을 End-to-End로 학습하면 더 좋은 성능을 보입니다.

② 더 빠른 학습
최근에는 Naive Recurrent Unit을 단순히 적층하여 학습하는 경우는 거의 없습니다. RNN에서 Input 문장이 길어지면 잘 학습되지 못하는 현상인 장기종속성 문제(Long-Term Dependency)를 해결하고 느린 속도를 개선하기 위한 변형 Unit들을 주로 이용합니다.
주로 이용하는 변형 Recurrent Unit으로는 LSTM(Long-Short Term Memory) Unit, GRU(Gated Recurrent Unit) 등이 있다. 정확도는 다소 떨어지나 속도 개선을 하여 deep한 구조를 가능하게 하는 SRU(Single Recurrent Unit)나 Highway Network 구조를 이용하기도 합니다.
영상 처리(Image Processing) 분야에서 주로 이용하는 CNN(Convolutional Neural Network) 구조를 적용하면 RNN과 유사한 성능을 내지만 더 빠른 학습이 가능합니다.
③ 더 복잡한, 더 깊은 학습
단순히 RNN만 이용한 구조, 단순히 CNN만 이용한 구조보다는 여러 기능의 unit을 하이브리드하게 적용한 모델이 많아지고 있는데요. 여기에 빠르고 깊은 학습을 가능케 하는 GRU, Highway Network 등의 등장으로 NLU 영역에도 deep한 구조가 권장되면서 모델이 더 추상적인 표현을 학습할 수 있게 되었습니다.
또한, Word Embedding, Attention, Input Feeding, Copying Mechanism 등 기존 네트워크에 기능을 더 얹어서 성능 향상을 가능케 하는 요소들이 많이 발전되었습니다.
그리고 단순히 한 가지의 데이터 형식을 다루는 모델보다는 여러 데이터 형식을 처리할 수 있는 기술이 발달하고 있는데요. 텍스트뿐만 아니라 이미지나 영상, 음성을 처리하는 모델과 결합한 형태도 등장하고 있습니다. 예를 들어 이미지를 입력받아 간단한 텍스트 설명 생성하는 이미지 캡션 생성 모델이나, Visual QA 등이 있습니다.
NLU의 국내•외 동향은?
인공지능 기반의 비즈니스는 기업의 니즈로 인해 연구를 진행하고 사업을 이행하는 수동적 연구라기보다는 다양한 시도와 아이디어로부터 신기술을 연구하고, 이 기술을 이용할 수 있는 분야의 신사업을 창출되는 능동적 연구상으로부터 비롯된다고 볼 수 있습니다.
근래 몇 년간 인공지능이 뜨거운 주제로 떠오르면서 딥러닝을 이용한 NLP, NLU 분야도 주목받고 있습니다. 외국의 경우 세계 여러 기업과 대학들이 관련 인재를 적극적으로 채용하고, 논문 실적을 내면서 NLU 연구에 박차를 가하고 있는데요.
국내에서도 네이버, 카카오 등의 IT 기업에서 인공지능을 활용한 NLU 연구가 활발하며, 이와 관련한 사업들도 차례로 생겨나고 있습니다. 문장 분류나 기계 번역 같은 분야는 국내에서도 이미 높은 수준의 완성도를 보여주고 있습니다.

NLU 기술의 발전으로 노동력을 크게 절감시킨 대표적인 분야로는 VPA(Virtual Personal Assistant), 챗봇이 있습니다. 2017년이 챗봇의 기능 활용 측면과 실제 도메인의 업무에 적용 가능한지 그 가능성을 다각도로 검증하는 과도기였다면, 2018년부터는 그동안 챗봇의 가능성에 대해 눈치 보기를 하던 기업들이 본격적으로 도입 추진을 하며 챗봇의 사용률이 폭발적으로 증가할 것으로 전망됩니다. 이미 상당수의 은행에서 인공지능 기반 챗봇을 도입해 서비스하고 있습니다.
현재도 많은 곳에서 의도 분류, 감성 분석과 같은 챗봇 내부 기술을 딥러닝 기반으로 적용하고 있지만, 사용자의 질문에 대해 알맞은 답변을 찾아내고 문장으로 생성하는 데에는 아직 전통적인 수작업 방식을 많이 이용하고 있습니다. 따라서 이 분야엔 학습 기반의 MRC를 누가 제일 먼저, 얼마나 잘 하느냐에 따라 선두가 정해진다고 볼 수 있습니다.
NLU는 최근 많은 신기술이 부상하고 있는 분야인 만큼, 관계자들은 새로운 기술과 알고리즘을 빠르게 캐치하고 구현할 수 있는 역량이 필요하다고 보입니다.
글 l LG CNS 정보기술연구소



