
IBM에서 개발한 의료 AI 시스템 ‘왓슨(Watson)’은 출혈이 심한 암 환자에게 출혈을 ‘악화’시킬 수 있는 약을 처방한 사례가 있습니다. 아마존에서 개발한 AI 얼굴인식 시스템 ‘아마존 레코그니션(Amazon’s Face Recognition)’은 미국 의회 의원의 사진을 보고 ‘범죄자’로 오인했습니다. 이처럼 막대한 금액과 노력을 투자해 개발한 AI 시스템도 오류와 취약점을 가질 수 있는데요. 점점 커지는 AI의 영향력과 함께, AI 시스템 개발을 위한 보안 기법의 중요성도 함께 높아지고 있습니다. 이번 글에서는 AI 시스템의 개발 단계부터, 각 단계별 보안 공격기술, 그리고 그런 공격기술을 방어하기 위한 가이드를 제시해 드리고자 합니다.
AI 시스템 개발 단계
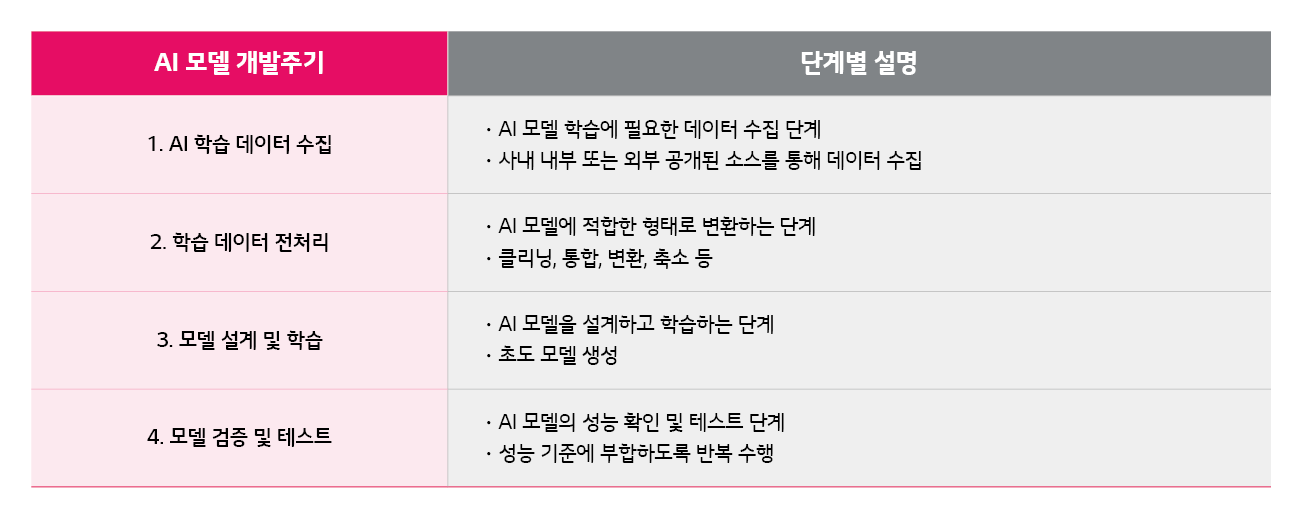
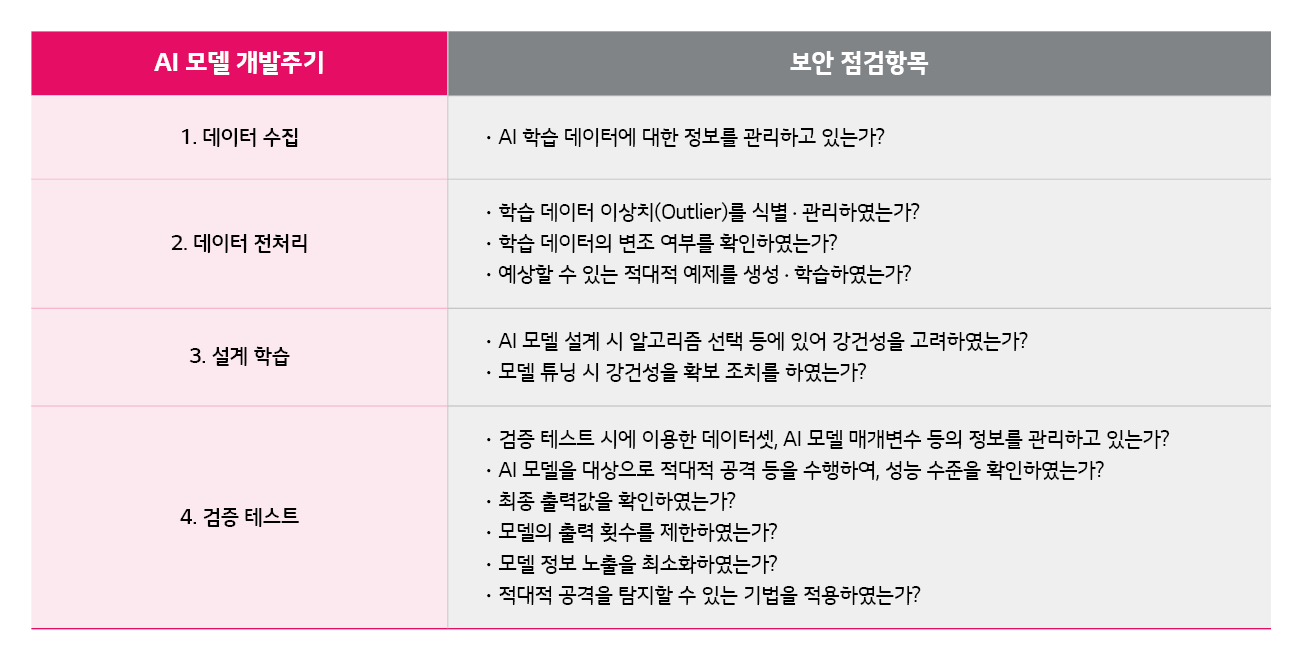
AI 시스템 개발은 AI 모델을 개발해 시스템적으로 구현하는 것입니다. AI 모델은 일반적으로 데이터 수집부터 전처리 ⨠ 설계 ⨠ 학습 ⨠ 검증 ⨠ 테스트를 거칩니다. 이를 ‘AI 모델 개발 주기’라고 하며, 구체적으로 [표 1]과 같은 단계를 거칩니다.
AI 시스템 공격기술
AI 시스템 보안의 취약점은 AI 모델 개발 주기 과정인 ‘학습 단계’와 AI 모델 개발 주기 이후 ‘활용 단계’에서 발생할 수 있습니다.
• 학습 단계의 공격기술
AI 모델 개발 주기 과정인 학습 단계의 공격기술로는 Poisoning 공격(모델 학습 과정에 관여해 AI 시스템 자체를 손상시키는 공격)과 Backdoor 공격(시스템 또는 알고리즘에서 정상적인 인증 절차를 우회하는 방법론)이 있습니다. 이러한 공격은 잘못된 데이터를 학습해 AI 모델을 오작동하게 합니다.
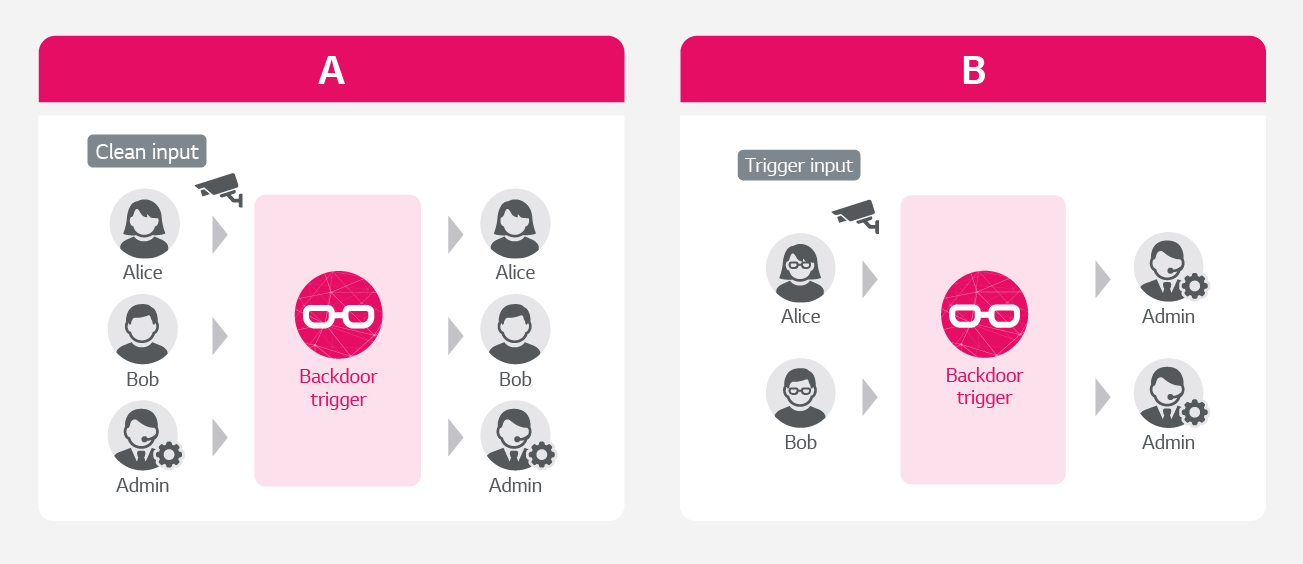
Backdoor 공격은 트리거(Trigger)가 추가된 이미지 데이터를 오분류합니다. 예를 들어 학생과 교수를 구분하는 AI 모델이 있다고 가정하면, 학생에 ‘안경’이라는 트리거를 삽입해 교수로 인식하게 만드는 오류를 의미합니다.
• 활용 단계의 공격기술
• AI 모델 개발 주기 이후 활용 단계의 공격기술로는 대표적으로 ‘적대적 공격’이 있습니다.

(출처: Weilin Xu 등의 [Feature Squeezing: Detecting Adversarial Examples in Deep Neural Networks])
적대적 공격은 최소한의 변조만으로 AI가 오인식하도록 유도하는 공격을 말합니다. [그림 3]는 특정 영역을 변조한 적대적 공격의 예시입니다. 도로 표지판에 빨간 사각형 테두리가 추가됐을 뿐인데요. AI는 이미지(a)를 ‘도로 표지판’으로 잘 인식하지만, (b)는 전혀 의미가 다른 ‘교회’로 인식합니다. 이렇게 작은 변조만으로도 AI 알고리즘의 취약점을 이용하면 인식에 교란을 발생시킬 수 있는 것이죠.
AI 시스템 공격 방어를 위한 보안기법
AI 시스템 공격을 방어하기 위해서는 어떤 보안 기법이 필요할까요? 학습 단계와 활용 단계에서 발생하는 다양한 공격에 대한 방어 기법을 알아보겠습니다.
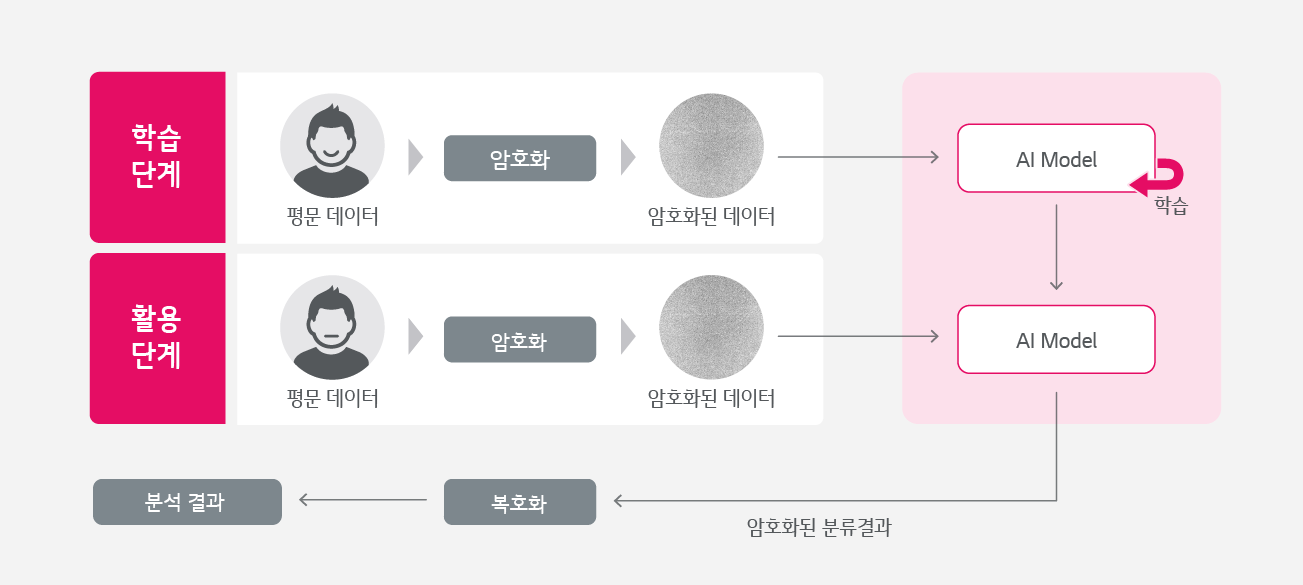
• 동형 암호화 기법 (homomorphic encryption)
Backdoor 공격을 방어하기 위한 동형 암호화 기법은 암호화된 상태에서 수치 연산 등이 가능한 기술입니다. AI 학습은 학습 데이터를 통해 파라미터를 계산하는데요. 동형 암호화 기법은 AI 학습에 필요한 학습 데이터를 암호화해 전송하고, 암호화된 상태에서 학습을 수행해 Backdoor 공격을 방어합니다. [그림 4]은 주로 프라이버시 보호에 많이 사용되는 동형 암호화 기반 머신러닝 구조입니다.
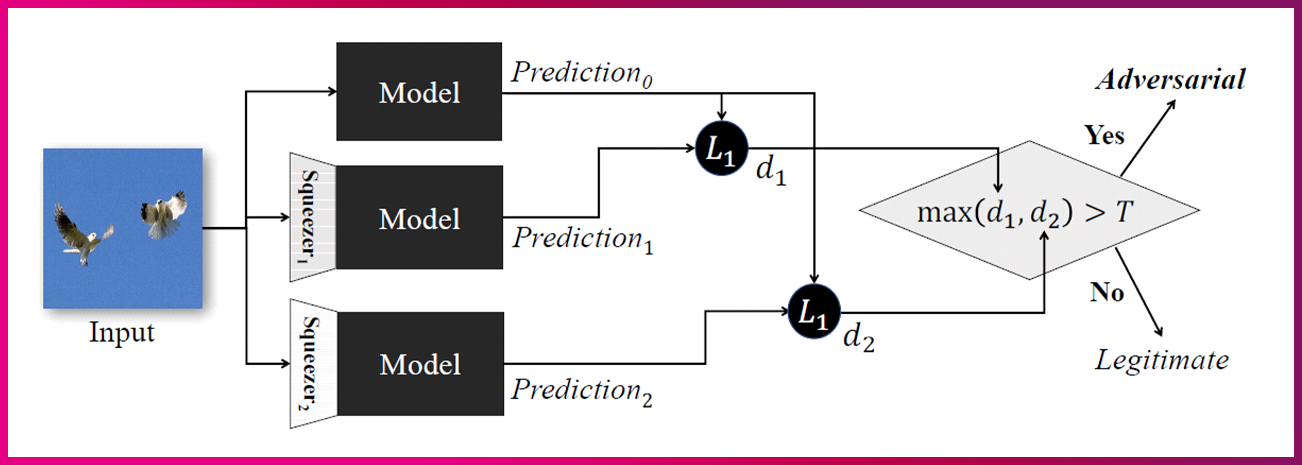
• Feature Squeezing
적대적 공격을 방어하는 기법으로 Feature Squeezing이 있습니다. Feature Squeezing이란 공격자의 공격 공간을 줄이기 위해 8bits로 표현되는 이미지의 color-bit를 줄이는 기법인데요. 입력 이미지에 대한 AI 모델의 출력값과 Squeezing을 거친 샘플에 대한 모델 예측값의 차이를 계산해, 차이가 크면 적대적 예제로 탐지하고 그렇지 않으면 정상 이미지로 판단하는 것이죠. [그림 5]는 인공지능 모델의 오인식을 일으키는 적대적 예제를 탐지하기 위해 제안한 [Feature Squeezing]의 내용입니다.
지금까지 AI 시스템의 개발 단계부터 각 과정 별 공격기술과 이를 방어할 수 있는 보안 기법을 알아봤습니다. 실무 위주의 세부적 안내를 위해 최근 금융보안원에서 발간한 [금융 분야 AI 보안 가이드라인]도 참고하면 좋을 것 같습니다.
AI 시스템을 개발함에 있어 정해진 납기와 목표를 달성하는 것이 중요합니다. 그러나 어렵게 개발한 AI 시스템이 예기치 못한 악의적인 공격으로 무용지물이 되거나 또 다른 보안 사고의 트리거가 될 수 있음을 간과해서는 안 됩니다. AI 시스템 개발 시, 이번 글에서 제시한 보안 기법 및 [금융 분야 AI 보안 가이드라인]을 참고해 주의를 기울인다면 안전하고 건강한 AI 시스템 개발이 가능할 것입니다.
글 ㅣ LG CNS 보안서비스 Innovation팀 한철규 총괄


