인공지능(AI)에 많은 관심을 두지 않는 사람이라도, ‘알파고 제로(AlphaGo Zero)’ 대한 소식은 접하지 않았을까 생각합니다. 알파고는 미지의 영역이라고 여겨진 AI 기술을 본격화하는 계기가 되었기에, 기존 알파고의 강화 버전인 알파고 제로는 대단한 관심사가 될 수밖에 없겠죠.
본래 알파고는 수많은 바둑 기보를 토대로 기본적인 실력을 갖춘 정책망을 서로 대국하게 하는 방식으로 바둑을 익힌 AI입니다. 하지만, 알파고 제로는 기보 데이터를 익히지 않은 상태에서 바둑을 습득했습니다. 인간의 지식을 포함하지 않고도 AI가 발전할 수 있다는 걸 보여준 겁니다. 이런 알파고의 훈련 방식을 ‘강화 학습(Reinforcement Learning)’이라고 합니다.

강화 학습은 머신러닝의 한 분야로서 ‘보상을 최대한 많이 받는 방법을 학습하는 것’이라고 간략하게 설명할 수 있습니다. 바둑이라면 상대방을 이기는 것이 보상이므로 이기려는 방법을 AI가 습득하도록 반복해서 학습하는 거죠. 상기한 것처럼 알파고와 알파고 제로의 차이는 기보를 익힌 상태에서 강화 학습을 했느냐, 완전한 무(無)의 상태에서 강화 학습을 했느냐로 볼 수 있습니다. 그래서 알파고 제로의 성과는 AI가 인간이 해결하지 못한 난제를 풀 수도 있다는 잠재력과 강화 학습이 AI의 영역을 더 확장할 수 있다는 기대감으로 이어집니다.
그러나 모든 분야에 알파고 제로와 같은 강화 학습 모델을 적용하는 건 한계가 있습니다. 인공신경망이 문제에 대한 인간의 인지까지 모방할 수는 없기 때문입니다. 게임처럼 보상이 확실한 분야에 적용하기는 쉽지만, 그렇지 않은 분야에서의 머신러닝은 충분한 데이터를 요구합니다. 인류가 오랜 시간 걸려 쌓아놓은 지식을 배우는 시기가 필요했던 것처럼 말입니다.
문제는 많은 데이터를 확보한 분야라면 머신러닝 모델을 적용하기 쉽지만, 데이터가 부족한 분야는 그렇지 않다는 것입니다. 인간과 기계의 인지 차이로 강화 학습을 적용하기 어려운 분야라면 더욱 그렇습니다. 그래서 주목받는 방법이 바로 ‘전이 학습(Transfer learning)’입니다.
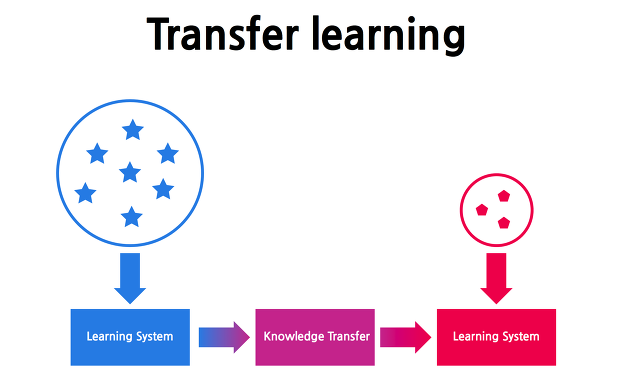
전이 학습은 특정 환경에서 만들어진 AI 알고리즘을 다른 비슷한 분야에 적용하는 것으로, 현재 많은 연구가 이뤄지는 머신러닝의 한 분야입니다. 아주 쉽게 설명하면, 사과 깎는 방법을 익힌 AI에게 배를 깎게 시키는 겁니다. 체스를 익힌 AI에게 장기를 두게 하거나 비를 예측하는 AI에게 눈을 예측하게 하는 거죠.
전이 학습의 장점은 데이터가 부족한 분야에도 적용할 수 있다는 것입니다. 예를 들어, 사과 깎는 방법에 대한 데이터는 많지만, 배를 깎는 데이터가 부족하다면 데이터가 풍부한 사과 깎는 방법을 우선 익히게 하는 것으로 데이터를 덜 제공하더라도 배를 깎을 수 있게 학습시킬 수 있습니다. 몇 가지를 사례를 보면 좀 더 쉽게 이해할 수 있습니다.

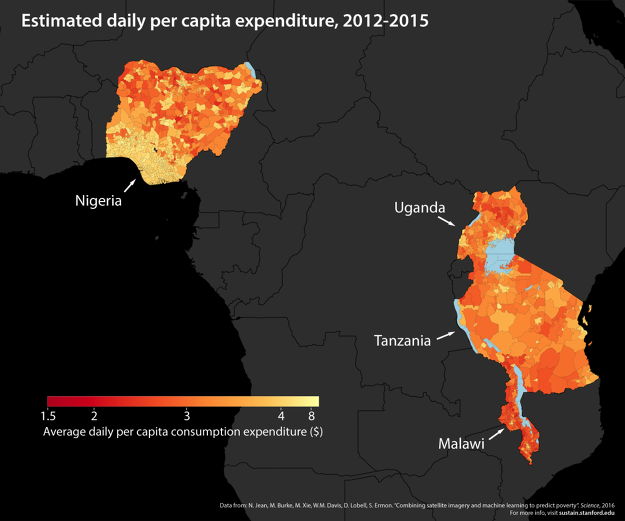
스탠퍼드의 지속가능성과 인공지능 랩(Sustainability and artificial intelligence lab)은 인공위성이 촬영한 이미지 데이터와 전이 학습을 사용하여 아프리카 국가들의 빈곤 지도를 만들었습니다.
빈곤과 관련한 데이터는 매우 부족합니다. 온라인이 발달한 현대에도 빈곤과 관련한 대부분 조사는 현장에서 이뤄지며, 데이터 오류도 많아서 신뢰성을 부여하여 빈곤을 예측하는 자료로 삼기 어렵기 때문입니다. 그 탓으로 짧은 기간 데이터를 갱신하는 것보다 특정 기간 수집한 가장 신뢰할만한 오래된 데이터를 빈곤 퇴치에 활용하고 있습니다.
그래서 인공위성 데이터는 부의 분포를 그나마 객관적으로 분류할 지표로 연구되었습니다. 야간에 발생하는 조명의 정도를 부의 분포를 나타내는 데이터로 활용할 수 있기 때문입니다. 하지만, 야간 조명만으로 부의 분포를 파악하는 건 밝기의 정도에 따른 차이, 그러니까 선진국과 개발도상국의 차이는 명확하게 나타낼 수 있지만, 개발도상국, 특히 극빈곤 지역의 빈곤 차이를 세부적으로 파악하기에 유용하지 않아서 한계가 있었습니다.
스탠퍼드대 연구진은 이런 한계를 극복하기 위해 풍부한 야간 조명 데이터를 활용한 전이 학습 모델과 고해상도의 주간 위성 사진을 결합하여 도로, 도시 지역, 수로, 농지 등 빈곤과 연관할 수 있는 개체를 식별하는 알고리즘을 고안했습니다. 이 알고리즘을 통해 AI는 개체들의 특징을 학습하여 빈곤 지역에서 발생할 야간 조명을 예측하고, 낮과 밤, 2개의 데이터 세트를 비교하는 것으로 빈곤 지역을 이전보다 세부적으로 파악할 수 있습니다.
연구진은 인공위성 사진만 있다면 해당 모델은 전 세계 빈곤을 파악하는 데에 사용할 수 있다면서 저렴하고, 확장성이 뛰어난 기술이라고 설명했습니다. 물론, 해당 알고리즘이 빈곤을 완벽하게 측정할 수 있는 건 아닙니다. 단지 빈곤 데이터를 확보하는 다른 방법보다 수월하고, 확보한 데이터를 기반으로 더 나은 알고리즘의 개발과 시스템으로 빈곤에 더 빠르게 대응할 방법을 마련했다는 데에 의미가 있습니다.
연구진은 기관들과 협의하여 알고리즘을 실제로 도입하고, 작성한 빈곤 지도를 토대로 자금을 효율적으로 운용하여 빈곤 퇴치에 도움을 줄 계획입니다.

전이 학습을 활용한 AI 모델은 스마트폰으로 이용할 수 있는 간단한 앱으로도 개발되고 있습니다.
카사바는 열대지방에서 가장 중요한 식량 중 하나입니다. 카사바 뿌리는 삶아 먹기도 하고, 타피오카로 불리는 전분으로 가공하여 널리 사용합니다. 중요한 만큼 안정적인 생산과 공급이 뒷받침되어야 하지만, 바이러스에 취약한 작물이기도 합니다. 질병은 매년 카사바 농가에 천문학적인 경제적 손실을 초래합니다.
펜실베이니아 주립 대학교와 구글의 AI 프로젝트팀인 구글 브레인 팀은 스마트폰을 통해 카사바의 질병을 진단할 수 있는 앱을 개발했습니다. 해당 앱은 구글이 개발한 오픈소스 머신러닝 기술인 텐서플로우(TensorFlow)를 활용했으며, 구글의 여러 앱에 적용된 기술입니다. 구글은 지난 5월 스마트폰에서 구동하는 효율적인 머신러닝 모델의 개발에 도움을 주는 프레임워크인 ‘텐서플로우 라이트(TensorFlow Lite)’를 발표하기도 했습니다. AI가 모바일에 담길 준비가 된 것이죠.
문제는 AI가 질병을 진단하려면 수많은 카사바 잎의 사진이 필요하다는 겁니다. 머신러닝으로 개와 고양이를 구분하고자 수백만 개의 개 사진이 필요한 것처럼 말입니다. 그러나 질병에 걸린 카사바 잎 사진은 수백만 개나 되지 않습니다. 그래서 전이 학습을 활용했습니다.
연구진은 탄자니아의 카사바 농장에서 2,756개의 카사바 사진을 확보했습니다. 그리고 전이 학습 모델을 사용하여 카사바 갈색 줄무늬 병(Cassava brown streak virus disease; CBSD)과 카사바 모자이크 바이러스(African cassava mosaic virus; ACMV)를 구분하도록 AI를 훈련했고, AI는 98%의 정확도로 갈색 잎, 96% 정확도로 붉은 잎 진드기를 확인했습니다.

그렇게 멋진 기술로 보이지 않을 수도 있습니다. 식물의 질병을 스마트폰으로 진단하는 사례는 이전에도 있었으니까요. 하지만 2,756개의 사진은 매우 부족한 데이터입니다. 그런데도 AI가 높은 정확도로 질병을 확인할 수 있다는 건 의미 있는 성과입니다. 이제 카사바뿐만 아니라 데이터가 부족한 다른 작물의 질병을 진단하는데에도 해당 모델을 활용할 수 있겠죠. 작물의 질병을 진단할 능력과 비용이 부족한 여러 농가에 큰 도움이 될 것입니다.
이 밖에도 전이 학습은 의료 분야 등에서 유용한 AI를 학습시키는 데에 활용되고 있습니다. 구글은 당뇨성 망막병증의 진단에, 스탠퍼드 대학은 피부암 발견에 전이 학습시킨 AI를 사용하여 우수한 정확도를 보였습니다. 카사바 진단 사례처럼 의료 환경이 좋지 않은 지역이나 병원에서도 AI를 통해 높은 정확도의 질병 진단 방법에 접근할 수 있을 테고, 관심이 적거나 많은 양의 데이터를 확보하지 못한 질병의 진단에 AI를 활용하는 활로가 될 것입니다.
당연하지만 전이 학습이 만능은 아닙니다. 앞서 설명한 알파고의 강화 학습처럼 머신러닝의 한 분야이고, 적용하려는 범위에 따라 유용하지 않을 수 있다는 한계가 있습니다. 또한, 다른 환경에서 만들어진 전이 학습 모델이 제대로 작동해야 다른 범위에도 적용할 수 있다는 전제가 필요합니다. 다만, 전제를 만족한다면 새로운 범위에 적용하기 위해서 데이터 수집부터 머신러닝 모델을 재구성해야 하는 불편함을 최소화할 수 있습니다. 이는 AI 도입을 위한 비용과 시간의 문제로 연결되는 중요한 부분입니다.
이와 같이 전이 학습은 AI가 특정 문제를 해결하기 위해 누적한 지능을 다른 문제에 적용할 수 있는지 확인하는 분야이자 AI를 현실에 유용한 형태로 도입할 수 있게 하는 통로로써 연구되고 있습니다.
글 | 맥갤러리 | IT칼럼니스트


