오랜 기간동안 많은 기업은 음성 인식 분야의 인공지능에 대한 연구개발을 해 왔습니다. 그러나 아직 자유로운 대화가 가능한 수준까지는 구현되지 못하고 있는데요. 1990년대, 당시 거대 IT 기업이었던 야후(Yahoo) 등의 주요 기업은 엄청난 투자를 통해 음성 인식 기능을 구현하려 노력했지만, 그 정확도는 높지 않았습니다.
약 80% 정도의 음성 인식 정확도를 달성하는데 10년 이상의 시간이 소요되었습니다. 그러나 이후 정체기를 맞이하였고, 현재까지도 인간 수준의 인식률에는 크게 미치지 못해서 널리 상용화되지는 못하고 있는 상황입니다.
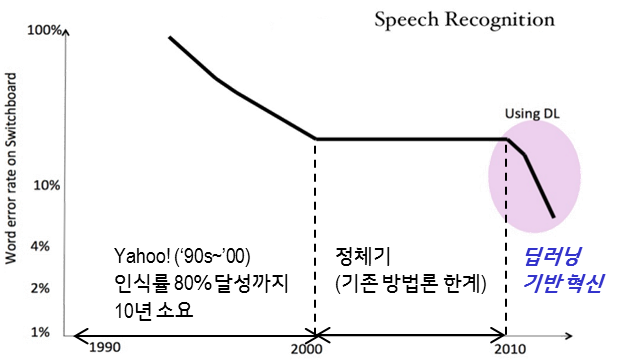
언어 인식 분야의 지능이 빠르게 발전되지 못했던 것은 기존 사람(전문가) 중심 방법론의 한계 때문이었습니다. 기계가 인간의 언어를 인식하기 위해서는 개별 단어의 의미를 이해하는 것을 시작으로, 구문•문장 등 매우 복잡하고 다양한 단어들의 관계들을 정확하고 정교하게 모델링해야 합니다.
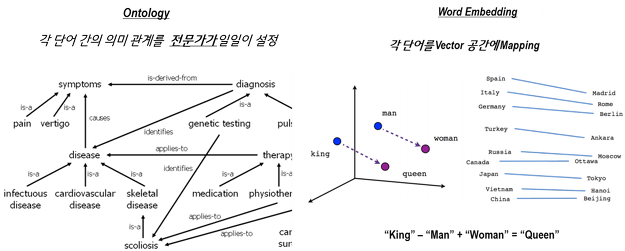
과거에는 이러한 단어 간 관계 정의를 언어학을 전공한 전문가가 중심이 되어 모델링했습니다. 온톨로지(Ontology)라 불리는 이러한 언어 모델은 전문가가 일일이 단어 간의 관계를 설정해 놓는 방식으로 구현됐는데요. 전문가의 능력, 경험, 투자 비용 등이 언어 인식의 핵심 역량으로 작용해 왔습니다. 그러나, 이러한 온톨로지 기반의 언어 인식 모델은 언어의 확장성이 낮다는 큰 단점을 갖고 있었습니다.
새로운 언어가 추가될 때마다 사람이 직접 모델을 다시 수정해야 하거나, 의학•법률•금융 등과 같이 정확한 언어 이해가 필요한 특정한 분야의 전문지식이 바탕이 되어야 하는 경우, 각 분야의 전문가가 언어 모델의 작성에 개입해야 하는 등의 한계가 있었습니다.

그러나 최근 딥러닝이 적용되면서 과거와 달리 사람(전문가)에 의존하지 않고 데이터에 기반을 둔 인공지능이 스스로 학습해 언어를 이해하게 하는 방식으로 전환되고 있습니다. 구글은 웹 서비스를 하며 축적한 데이터를 기반으로 ‘word2vec’1이라는 언어 모델을 구현했는데요. 수년간 뉴스 서비스를 통해 확보한 텍스트 정보에서 약 1000억 개에 이르는 단어2를 기계 학습에 활용했습니다.
개별 단어가 아닌 구문 단위로 이해된3 각각의 단어를 수백 개의 차원으로 구성된 벡터 공간에 위치시켰습니다. 아래의 <그림>과 같이 각 단어를 벡터 공간에 개별적으로 위치시키면, 결과적으로 관련성이 높은 단어들이 벡터 공간 내 서로 유사한 위치에 존재하게 되며, 단어별 상관 관계를 자동으로 정의할 수 있습니다.
‘Spain•Italy•Germany…’ 와 같은 국가 이름과 ‘Madrid•Rome•Berlin…’과 같은 수도가 서로 유사한 공간에 그룹된 형태로 위치하게 되고, 국가 이름과 수도 간에는 일정한 거리를 두고 위치하게 되는데요. 최근 구현되고 있는 언어 인식•이해 지능들은 대부분 이렇게 데이터를 기반으로 구성된 언어 모델의 형태를 하고 있습니다.
대표적으로는 구글의 word2vec, 스탠퍼드대의 GloVe4 등이 존재하며 이들은 모두 구현된 모델(Word Embedding)을 공개해 누구나 쉽게 이들 모델을 기반으로 언어 인식 지능을 구현할 수 있습니다.
이렇게 데이터를 기반으로 구성된 언어 모델은 과거 온톨로지 방식보다 확장성이 높고 특정 분야에 종속(Domain Dependent)되지 않습니다. 새로운 언어가 추가되거나, 전문성 필요한 특정 분야에 활용하려 할 경우, 관련 데이터를 기계에 학습시켜 모델을 업데이트하면 되는 것이죠. 또한, 전혀 새로운 언어에서도 충분한 데이터만 확보된다면, 과거보다 매우 빠르고 쉽게 인식 가능한 언어를 확장할 수 있습니다.
예를 들어, 한국어의 경우 글로벌 기업 대비 한국어에 대한 전문성과 경험을 기반으로 한 국내 기업들의 언어 인식•이해의 정확도가 높아져 왔지만, 최근 구글, 페이스북 등 데이터를 기반으로 한국어 인식을 구현하고 있는 기업들은 기존보다 높은 성능으로 기술을 구현해 내고 있습니다.

구글은 언어 인식•이해 분야에 딥러닝 기술을 적용한 지 2년 만에 인식 가능 언어를 32개(’17.3)까지 확장했습니다. 마이크로소프트(Microsoft), 바이두(Baidu) 또한 매우 다양한 언어에 대해 인간 수준(Human-level)의 언어 이해 지능을 구현해 내고 있죠. 특히, 바이두의 경우 딥러닝 기반의 언어 인식 기술인 ‘Deep Speech’ 논문을 ’145, ‘15년6 차례로 발표하며 인간의 개입을 최소화하면서도 높은 성능을 갖는 음성 인식 기술을 구현하고 있습니다.
인간 수준의 언어 인식•이해 지능을 갖게 된 인공지능은 인간의 목소리를 자유롭게 생성해 내기도 합니다. 과거 기계에 의해 생성된 인간의 목소리는 개별 단어•구문을 조합해 만들어지는 것으로 문장 단위로 인간이 인식할 때 발음, 억양 등이 매우 자연스럽지 못했는데요. 하지만 딥러닝이 적용되며 음성 생성 분야의 지능은 인간의 음성을 학습해 개별 단어 단위의 발음, 악센트(Accent)뿐만 아니라 문장 단위에서의 억양(Intonation)까지 매우 정교한 수준으로 구현되고 있습니다.
딥마인드(DeepMind)는 기존 최고 수준이었던 구글의 음성 생성(TTS: Text-to-Speech) 기술을 획기적으로 발전시킨 WaveNet 논문7을 발표했습니다. 기존 구글의 방식도 딥러닝에 기반해 구현되었지만, 딥마인드는 알고리즘 고도화와 학습 데이터의 다양화를 통해 성능 향상을 이루었습니다.
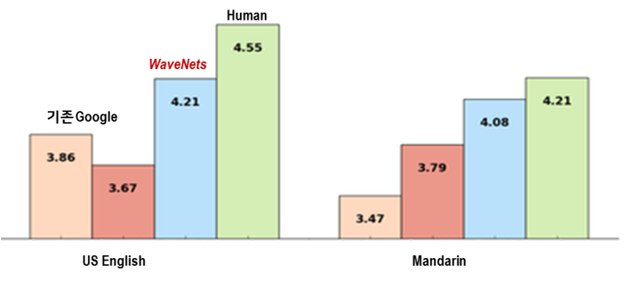
약 100여 개의 문장에 대해 인간의 목소리와 비슷한 정도를 정량화해 테스트한 결과에서 딥마인드가 발표한 웨이브넷(WaveNet)은 인간 수준인 4.55에 근접한 4.21점을 기록했습니다. 실제 웨이브넷이 생성한 음성을 들어보면 인공지능이 생성했다는 사전 정보가 없으면, 기계가 생성한 가상의 목소리라는 것을 판별해 내기가 매우 어려울 정도입니다.
바이두 또한 딥러닝을 음성 생성 분야에 적용하고 있는데요. DeepVoice9라 불리는 이 기술은 특정 사람의 목소리를 반복 학습해, 그 사람의 목소리의 특징을 완벽히 분석, 모델링합니다. 이렇게 만들어진 모델을 기반으로 생성된 음성은 마치 그 사람이 말을 한 것과 매우 유사한 수준으로 특정 인물의 음성을 생성해 냅니다. 국내 네이버도 유명 연예인의 목소리를 학습하고 특징을 모델링해 가상으로 생성된 음성으로 동화책을 읽어 주는 서비스를 선보이기도 했습니다.

이러한 언어 인식•이해 기술의 혁신적인 발전은 애플 시리(Siri), 아마존 알렉사(Alexa)와 같은 지능형 비서 서비스의 활성화로 이어질 것으로 전망됩니다. 지금까지 음성 인식 기반의 서비스들은 낮은 인식 정확도와 제한적인 기능으로 인해 크게 상용화되지 못 했는데요. 하지만 최근 딥러닝을 활용한 음성 인식•이해 기술을 구현하는 주요 기업 및 스타트업 기업들은 매우 높은 수준의 정확도와 인식률을 가진 서비스를 선보이고 있습니다.
특히 비브랩(Viv Labs), 사운드하운드(SoundHound)와 같은 스타트업 기업들의 언어 인식•이해 지능은 단문뿐만 아니라 두 개 이상의 단문이 연결된 복문•혼합 복문 등에서도 높은 정확도를 보이며 실시간으로 반응하는 수준으로 구현되고 있습니다.
이러한 언어 인식 지능의 발전은 구글•애플•아마존 등 주요 글로벌 기업들이 최근 출시하고 있는 스피커 형태의 비서형 음성 인식 서비스 경쟁과 맞물려 향후 새로운 혁신을 만들어 낼 수 있을 것으로 기대됩니다.
글 | 이승훈 책임연구원(shlee@lgeri.com) | LG경제연구원
- Y. Glodberg, et al, ‘word2vec Explained: deriving Mikolov et al.’s negative-sampling word-embedding method’, 2014 [본문으로]
- 단어를 구문 단위로 학습해 학습해 동일 단어라도 문맥적 의미에 다른 벡터 공간에 위치 시킴 [본문으로]
- 개별 단어가 아닌 구문 내의 단어의 의미를 분석해 벡터 공간에 위치… 동음이의어의 경우 앞/뒤 단어와 관계를 통해 같은 문자의 단어라도 다른 벡터 공간에 위치하게 함(He ‘may’ want vs. ‘May’ 15th ) [본문으로]
- J. Pennington, et al., ‘GloVe: Global Vectors for Word Representation’, 2014 [본문으로]
- Awni Hannun, et al., Deep Speech: Scaling up end-to-end speech recognition, 2014 [본문으로]
- Dario Amodei, et al., Deep Speech 2: End-to-End Speech Recognition in English and Mandarin, 2015 [본문으로]
- A. Oord, et al., WaveNet: A Generative Model for Raw Audio, CoRR 2016; [본문으로]
- 인공지능 기반의 언어 생성 기술 발전: MOS 평가 점수 비교(평가자가 인공지능으로 생성된 100개의 문장을 듣고 인간의 목소리와 비슷한 정도를 1~5점 척도로 점수 부여) [본문으로]
- S. Arik, et al. Deep Voice: Real-time Neural Text-to-Speech, ICML 2017 [본문으로]


