지난 시간에는 강화학습의 정의와 등장 배경 그리고 머신러닝 분야 중의 하나인 강화학습(Reinforcement Learning)에 대해 알아봤습니다.
● 보상을 통해 학습하는 머신러닝 기술 1편: http://blog.lgcns.com/1692

그렇다면 이번 시간에는 강화학습의 머신러닝 기술을 토대로 발전하고 있는 다양한 사례와 앞으로의 동향에 대해 알아보겠습니다.
강화학습 기술의 적용사례 1. 게임
게임은 강화학습이 발전하게 된 토대를 만들어 주었고 지금도 강화학습 알고리즘의 테스트베드로 많이 쓰입니다.
● 딥마인드
알파고
전편에서 설명했듯이 바둑에서 이세돌을 4:1로 이기면서 강화학습이 관심을 받게 된 계기를 만들었습니다. 2017년 5월에는 커제를 3:0으로 격파하고 그 후 딥마인드에서 공식적으로 은퇴를 선언했는데요. 이세돌을 이긴 알파고를 알파고 리(AlphaGo Lee), 커제를 이긴 알파고를 알파고 마스터(AlphaGo Master)라고 부릅니다.
알파고 제로(AlphaGo Zero)
알파고 팀은 2017년 10월 19일 네이쳐에 인간의 게임 데이터를 사용하지 않고 바둑의 규칙만 가지고 학습하는 알파고 제로를 발표했습니다. 알파고 제로는 3일 만에 알파고 리를 100:0으로 제압하고, 21일 만에 알파고 마스터의 레벨에 도달했으며 40일 만에 모든 이전 버전을 능가했습니다.

알파제로(AlphaZero)
인간의 기보 없이 성장한 알파고 제로를 범용으로 만든 버전입니다. 알파고 제로가 바둑에 한정된 것과 달리, 알파제로는 여러 게임에 적용될 수 있도록 알고리즘을 범용화했는데요. 알파제로는 2시간이 채 되지 않아 현존하는 가장 강한 쇼기 AI인 엘모(Elmo)를 앞지르고, 체스 역시 4시간 만에 가장 강한 체스 AI인 스톡피쉬(Stockfish)를 제압했습니다.
● 데브시스터즈: 알파런(AlphaRun)
강화학습을 이용해 사람 대신 쿠키런을 플레이하는 프로그램입니다. 구현하는데 딥러닝과 강화학습 기술 8가지가 사용되었는데요. 데브시스터즈는 이렇게 학습한 알파런을 밸런싱 자동화에 사용합니다.
게임 패치를 내놓을 때 항상 문제가 되는 것이 기존 패치와의 밸런스 차이입니다. QA에서도 밸런스 테스트를 하지만 쿠키런의 경우 쿠키 X 펫 X 보물 X 맵 = 30 X 30 X 9 X 7가지나 되는 경우의 수가 존재하며 평균 플레이 시간(4분)을 고려하면 테스트에 약 5,040일이 소요된다고 합니다. 사실상 사람이 모든 경우를 테스트하는 것은 불가능한데요. 하지만 알파런을 사용해 다수의 프로세스로 돌리고 플레이 시간을 빠르게 해서 테스트 시간(14일)을 획기적으로 줄일 수 있었습니다.
강화학습 기술의 적용사례 2. 지능형 로봇
강화학습은 로봇 분야와 가장 가까운 머신러닝 분야로 손꼽히는 이유는 로봇 스스로가 실제로 행동하고 이를 통해 배우는 에이전트이기 때문입니다.

보스턴 다이내믹스: 아틀라스(Atlas)
아틀라스는 소프트뱅크의 자회사 보스턴 다이내믹스가 제작한 휴머노이드 로봇입니다. 복잡한 지형에서도 자동으로 자세를 유지하며, 보행 경로를 설정하여 보행할 수 있고, 두 팔로 주위환경을 조작하는 것은 물론 넘어져도 직접 일어나고 물체까지 들어 올릴 수 있습니다.
2017년 11월 16일 공개한 영상에서는 징검다리형 구조물을 뛰어서 건너기도 하고 높은 구조물에 올라서서 백 텀블링에 성공해 사람들을 놀라게 했습니다.
강화학습 기술의 적용사례 3. 자율주행차
자율주행차에서 강화학습은 카메라로 입력된 이미지 및 센서 데이터를 이용해 최적의 행동을 찾는 데 사용되는데요. 여기서 최적의 행동이란 사람이 실제로 자동차를 운전할 때 하는 행동인 직진, 후진, 정지, 차선변경 등입니다. 운전할 때 발생하는 상황은 매우 방대하므로 컴퓨터에 일일이 운전하는 방법을 가르치는 것은 불가능한데요. 하지만 강화학습을 이용하면 계속 운전을 시도하면서 받은 보상을 통해 운전하는 방법을 스스로 배우게 됩니다.

처음 자율주행차를 학습할 때는 도로에서 바로 주행하는 것이 위험하므로 주로 자동차 게임과 같은 시뮬레이터를 이용하는데요. 시뮬레이터를 통해 충분히 학습되면 실제 도로에 나가서 추가 학습을 합니다. 학습이 어느 정도 되어있다고 해도 실제 도로에서 자율주행을 하는 것은 위험하므로 주로 사람이 함께 타는데 최근에는 사람 없이 주행하는 자율주행차도 테스트가 이루어지고 있습니다. 구글, NVIDIA, 테슬라 등의 회사가 자율주행차를 연구하고 있습니다.
강화학습 기술의 적용사례 4. 금융
P모건: LXOM
고객 주문을 최적의 가격으로 빠르게 실행하는 시스템입니다. 어떤 주식을 살 것인지를 결정하는 기능은 없지만, 강화학습을 이용하여 어떻게 사고팔지를 효과적으로 판단합니다. 대규모 지분 매각 시점을 찾는데 탁월하며 많은 지분을 한 번에 팔 때 투자자가 손실을 최소화하고 최적의 이익을 취할 수 있는 가격대를 찾아줍니다.

유럽의 테스트에서는 LOXM에 의해 달성된 가격이 벤치마크보다 현저하게 우수함을 보여줬는데요. 또한, 고객이 동의한 경우 거래 방법을 결정할 때 고객 행동과 반응을 고려하는 부분까지 진화가 가능한 것으로 알려져 있습니다.
강화학습의 앞으로의 시장 동향은?
강화학습을 여러 분야에 적용하려는 시도는 많지만 아직은 연구 단계입니다. 그중에서 앞으로 큰 시장을 형성할 대표적인 분야는 지능형 로봇과 자율주행차입니다. 사실 지능형 로봇과 자율주행차는 강화학습만으로 이루어진 제품이 아니라 여러 기술의 복합체입니다.
하지만 강화학습 분야에서 이 두 가지를 꼽는 이유는 어떤 상황에서도 사람처럼 판단하고 행동하는 핵심 기술이 바로 강화학습이기 때문인데요. 따라서 지능형 로봇과 자율주행차 시장의 성공 여부는 곧 강화학습의 성공과 직결되기 때문에 여기서는 지능형 로봇과 자율주행차의 시장 동향에 대해 알아보겠습니다.
● 지능형 로봇
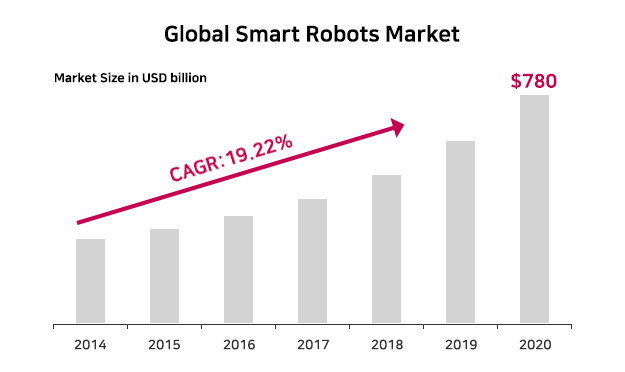
시장조사기관 Markets and Markets에 따르면, 전 세계 지능형 로봇 시장은 2020년까지 연평균 19.22%로 성장해 그 규모가 780억 달러에 이를 전망이라고 합니다. 자동차, 건설 등 제조업과 전문화된 산업 분야를 포함해 노인 지원, 엔터테인먼트, 청소 등 개인 서비스를 제공하는 등 다양한 분야에서 활용될 것으로 예상됩니다.
글로벌 IT 리서치기 기업 가트너(Gartner)는 인공지능이 비즈니스 전략과 인력 고용에 미치는 영향을 고려할 때, 2022년에 이르러서는 인공지능을 탑재한 지능형 로봇이 의료, 법률, IT 분야 고학력 전문직 업무를 대체하리라 전망했습니다.
● 자율주행차
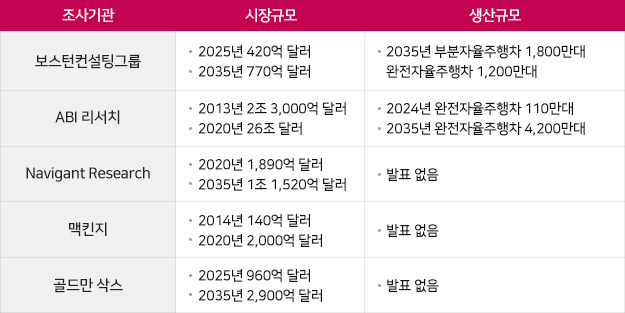
l 자율주행차 시장 및 생산 규모 전망
주요 글로벌 조사기관별 시장전망 관련 발표한 수치는 달라도, 공통으로 25년 전후 자율주행차 보급 및 시장, 생산 규모는 크기 증가할 것이라 전망했습니다.
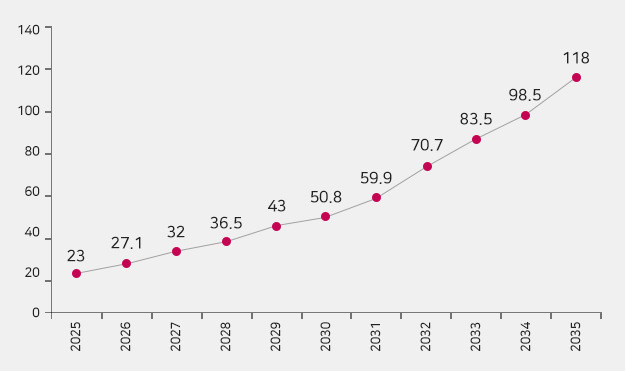
글로벌 조사기관 IHS Automotive는 25년부터 부분자율주행차 대신 완전자율주행차가 보급될 것이고 2025년 23만대에서 2035년 118만대로 연평균 18% 성장하리라 전망했습니다.
강화학습 벤더 동향
● 강화학습 관련 국내 벤더
네이버
네이버랩스를 연구법인으로 분사하여 생활환경지능을 연구하고 있습니다. 2017년 3월에 서울모터쇼에서 자율주행차를 처음으로 공개했고 10월에는 Deview 2017에서 생활 로봇 9종을 선보였습니다.
SK텔레콤
2017년 초에 차량기술연구소를 만들어 자율주행차의 기반기술을 연구하고 있습니다. 7월에 국내 통신사 중에서 처음으로 자율주행 임시운행허가를 받았고 9월에 경부고속도로 약 26km 구간에서 시험주행에 성공했습니다.
카이스트
심현철 항공우주공학과 교수팀에서 개발한 자율주행차 ‘유레카 터보’가 임시운행허가증을 획득해서 2017년 1월부터 실제 도로에서 운행이 가능해졌습니다. 연구팀은 2009년부터 자율주행차 연구를 시작해서 자율주행차 5대를 성공적으로 개발했고 현재까지 캠퍼스 내에서 자율주행 테스트를 진행하고 있습니다.
데브시스터즈
Deview 2016에서 ‘딥러닝과 강화 학습으로 나보다 잘하는 쿠키런 AI 구현하기’를 발표한 이후 국내 강화학습 벤더로써의 인지도가 높아졌습니다. 2017년 8월에는 네이버 D2에서 ‘알아두면 쓸 데 있는 신기한 강화학습’이라는 제목으로 강의를 하기도 했습니다.

● 강화학습 관련 글로벌 벤더
딥마인드
알파고를 탄생시킨 강화학습의 선구자입니다. 2017년 7월에는 에이전트가 스스로 걷는 법을 학습할 수 있는 가상의 환경을 만들어 공개했습니다. 에이전트는 걷는 방법에 대한 지식이 전혀 없는 상황에서 다양한 지형에 대응해서 걷는 방법을 만들어냈는데요. 2017년 8월에는 블리자드와 협업하여 스타크래프트2 API를 공개했고 바둑 다음으로 스타크래프트를 정복하기 위해 연구를 진행하고 있습니다.
구글
구글 내부에서 자율주행 프로젝트가 시작되었지만, 현재는 알파벳의 자회사인 웨이모로 분리되어 연구를 계속하고 있습니다. 웨이모의 자율주행 자동차는 2017년 11월 공공 도로 주행 400만 마일(643만 7,376km)을 돌파했는데요. 실제 도로 주행과 더불어 더 많은 상황을 만들어 테스트하기 위해 가상의 자율 주행 공간인 ‘카크래프트(Carcraft)’를 제작해 사용하고 있습니다.
주행 거리나 누적된 데이터는 다른 자율주행차 벤더들이 따라올 수 없는 수준이며 이러한 기술력을 바탕으로 애리조나 피닉스에서는 운전자가 없는 완전 자율 택시 서비스를 시범 운영하기 시작했습니다.
오픈AI
오픈AI는 비영리 인공지능 연구 기업입니다. 강화학습 연구자들에게는 ‘오픈AI 짐(OpenAI Gym)’으로 유명합니다. 오픈AI 짐은 2016년 4월에 퍼블릭 베타를 출시했으며 그 후로 강화학습 연구를 위한 환경이 계속 추가되고 있습니다.
보스턴 다이내믹스
보행 로봇 개발에 주력하고 있는 회사입니다. 2005년 개발한 군사용 4족 로봇 ‘빅 독(Big dog)’으로 유명한데요. 2017년 11월 아틀라스가 징검다리 형태의 구조물을 건너고 백 텀블링에 성공한 영상을 공개하여 세상을 놀라게 했습니다. 그 후 4족 보행로봇 ‘스팟(Spot)’을 개량한 ‘스팟미니(SpotMini)’, 2족 로봇에 바퀴를 단 로봇인 ‘핸들(HANDEL)’을 공개했습니다.

강화학습은 흥미로운 분야이지만 아직 수익을 창출할 분야가 명확하지 않습니다. 시장 전망이 밝은 지능형 로봇이나 자율주행차도 아직 상용화하기까지는 갈 길이 멀고 큰 벤더들이 선점하고 있는 분야라 뛰어들기도 쉽지 않습니다. 하지만 강화학습은 점점 중요해지고 있으며 강화학습을 이용한 연구 성과들을 보면 그 영향력을 무시할 수 없게 되었습니다.
앞서 언급한 것처럼 목표로 하는 시장이 아직 명확하지 않기 때문에 적용 분야나 인력 투입이 어려운 상황입니다. 그래서 연구를 시작할 수 있는 적용 분야를 찾는 것이 중요합니다.
글 l LG CNS 정보기술연구소


