[ 머리말 ]
DR 또는 Data Migration에서 어떤 툴 / 어떤 서비스가 가장 안정적인가에 대한 이슈는 정말 오랜 기간 동안 IT 업계를 괴롭혀온 이슈입니다.
DR이라면 RTO / RPO 등 모든 요건이 괴롭히고, Migration 이면 지속성과 안정성이 핵심 이슈가 됩니다.
AWS에서도 Data migration에 쓸 수 있는 다양한 서비스가 존재합니다.
Endure 기반의 AWS Elastic Disater Recovery, Storage Gateway, Data Migration Service, Application Migration Service 등이 있습니다.
이번에는 그중, DataSync라는 서비스의 구현 방법을 알아보고 실 구현에 유용한 Tip을 나눠보겠습니다!
[ intro ]
Datasync는 On-prem 또는 EFS, 타 플랫폼의 스토리지 간 데이터를 이동시키고 모니터링할 수 있는 서비스입니다.
EBS 와 같이 특정 서버에 독점적으로 부여된 디스크가 아닌, NFS와 같이 공유 형태로 존재하는 디스크가 주 적용 대상이라고 판단해 주시면 됩니다.
핵심 매커니즘은 다음과 같습니다.
(1) 방화벽과 같은 사전 요건 설정 완료
(2) Source 영역이 존재하는 영역에 Agent 서버를 구성
(3) Datasync에 source와 destination을 지정
(4) 파일 이동을 위한 대상, 속도제한, 스케줄 및 각종 설정 지정
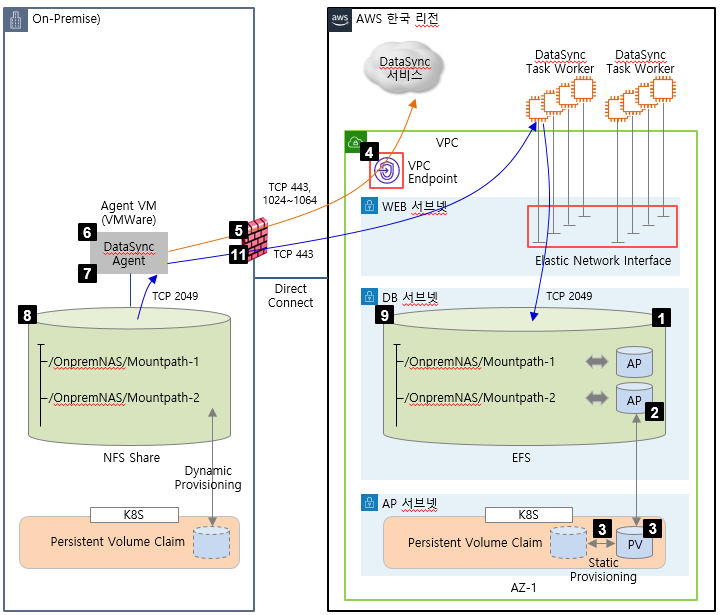
이번에는 On-prem의 NAS 스토리지를 AWS의 EFS로 이관하는 적용 예시를 기반으로 설명해 보겠습니다.
요구되는 architecture / Port는 아래와 같습니다.
[ 정의 ]
1. Agent
Datasync 좌측 메뉴에서 Agent를 선택합니다.
Create agent > 지원하는 Hypervisor는 다음 4개 입니다
VMWare ESXi , KVM , Microsoft Hyper-V, EC2 입니다.
Endpoint type은 VPC endpoints using AWS Private Link를 선택하는 것이 좋습니다
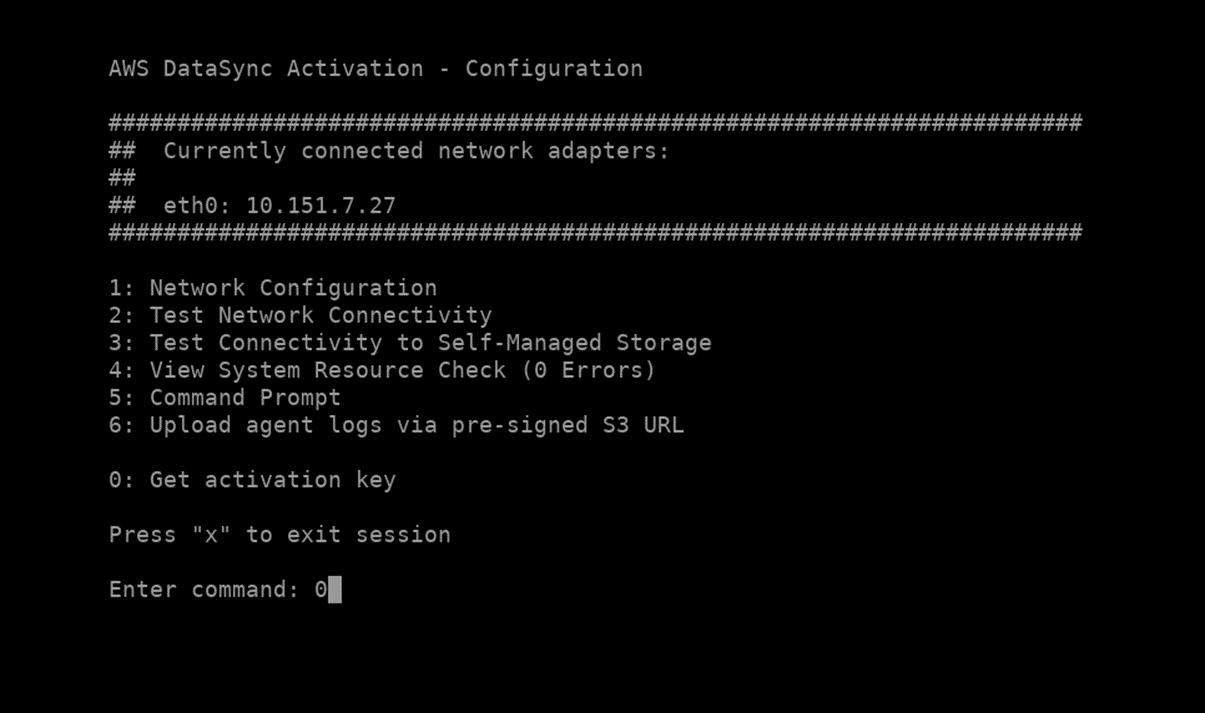
잊지마세요 보안!!!! Activation Key는 해당 문서가 참고용 문서이니 만큼, Automatically..로 이어지는 값을 선택하면 됩니다.
*Tips!!
Agent 및 AWS Datasync 간 Key 값이 오고가는 것은 별도의 방화벽 port 오픈이 필요합니다.
실제 적용시 방화벽 port 오픈의 여유가 있다면 Automaticaly를, port 관리가 타이트하다면 Manually를 추천합니다.
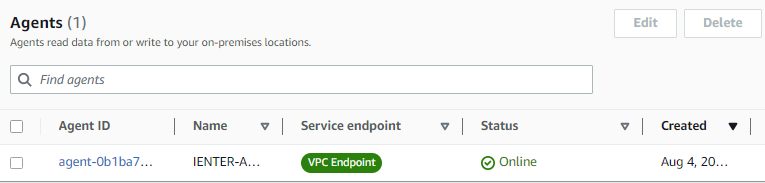
Key 등록까지 완료되면 다음과 같이 Online으로 상태가 변경됩니다.
2. Location
Source , Destination이 될 저장 매체를 정의하는 항목입니다.
지원하는 영역은 AWS EFS, AWS FSx, Amazon S3, HDFS, NFS (on-prem NAS 포함), Object Storage, SMB 입니다.
이번 시나리오 에서는 NFS를 선택해주십시오.
NFS server는 On-prem의 경우 NAS에 지정되어 있는 IP를 지정해야합니다.
Mount Path는 복제할 데이터가 저장된 NAS Mount 및 파일시스템 명을 지정해주시면 됩니다.
On-prem 에서 OS에서 NAS를 마운트 할때 사용하는 커맨드인
mount -t nfs IP:/Mountpath /OS-Filesystem 의 IP, Mountpath를 입력해주시면 됩니다.
Additional settings 을 누르시고 NFS 버전을 선택하셔야 합니다
Automatic , NFS3, NFS 4.0 ,4.1이 존재합니다.
*Tips!
On-prem에 설치된 Agent 서버와 NFS 서버의 IP, Mountpath는 상호 통신 및 마운트가 모두 가능한 상태여야 합니다!
NFS 버전의 경우 On-prem의 스토리지 설정값을 반드시 확인해야합니다. 스토리지에서 4.0 이상을 지원하는지 확인해야하며,
4.0 이상을 지원하더라도, 특정 스토리지(Ontap)은 Datasync 사용시 이슈가 생길 수 있습니다. Automatic으로 해도
에러가 발생될 수 있으며 이 때는 3.0으로 하향 조정하는 것이 가장 확실한 방법입니다!!
질문입니다! 이 에러를 어떻게 확인하고 어떻게 트러블 슈팅할 수 있을까요??
3. Task
* Tips!
Task에선 그 무엇보다도 중요한, sync를 진행할 시간 간격 및 sync 대상을 정의하게 됩니다.
반드시 요구조건 또는 시스템 요구사항을 사전 정의하여 입력 값을 정의해두는 것을 추천드립니다.
Create > Source , Destination Location 지정 > Task Execution configuration 이하
주요 설정값은 아래와 같습니다.
(1) Verify data
– Destination으로 데이터 전송 후 데이터 정상여부 검증
(2) bandwidth limit
– 전송 속도 제한
(3) Keep deleted files / Overwrite files
– source에서 삭제된 파일의 유지 여부 및 기존 파일 overwrite file 여부
* Tips!
이런 설정값은 설정시엔 큰 고민없이 선택될 수 있으나, 향후 데이터의 안정성에 큰 영향을 줄 수 있으니 반드시 잘 선택하셔야 합니다.
(4) Include / Exclude pattern
* Tips!
NAS 영역 Mountpath 하위에도 데이터 이동을 해야하는 영역과, 제외해도 되는 영역이 존재합니다 Incloud는 포함, Exclude는 제외 입니다. 디렉토리 명을 명시하면 됩니다
(5) Copy ownership , permissions , timestamps
(6) Schedule
– 스케줄은 Daily, Weekly 처럼 표준화된 항목을 등록할 수 있으나, Custom을 통해 좀더 상세한 조정이 가능합니다.
Custom은 OS의 crontab 과 구조가 동일합니다.
예를 들어, 5분 간격으로 파일의 복제가 필요한 경우, 1시간 기준으로 12개의 task가 필요해지고
이 경우 각 task별 custom은 아래와 같은 값을 가지게 됩니다.
cron(5 * * * ? *) , cron(10 * * * ? *) , cron(15 * * * ? *) …
(7) Task logging – log level / Cloudwatch Log group
* Tips!
Log level – Log basic information such as transfer errors : 에러 발생 시에만 로그 저장 Cloudwatch log 는 반드시 설정해주십시오. Task를 실행시 execution에도 로그가 어느 정도 보이지만 트러블 슈팅이 가능한 수준이 아닙니다. 반드시 log를 지정하시고 해당 log를 통해 정보를 확인해주십시오.
4. Execution 결과
아래와 같이 수행 결과가 저장되며, 해당 내용은 몇 개의 파일이, 어떤 속도로, 어떻게 전송되었는지 디테일한 정보를 확인할 수 있습니다.
[ 결론 ]
대용량의 데이터 , 빠르게 발생하는 I/O, 짧은 RTO/RPO 등 파일 이관의 요구조건이 매우 타이트할 경우 Datasync를 선택하기는 조금 어려울 수 있습니다. 하지만 cut-over를 대비한 데이터 마이그레이션이 필요하고, OS내 파일 전송 커맨드보다 좀 더 안정성 및 신빙성이 있고 모니터링이 가능한 조건을 원하는 경우 솔루션의 구매보다 비용적으로도 아주 훌륭한 대안이 될 수 있습니다.