
스마트폰에서 학습하는 구글의 연합학습
이번 글에서 최근 구글에서 발표한 연합학습(Federated Learning)에 대해 알아보고 연합학습이 보안과 어떤 관련이 있는지 살펴보겠습니다.
구글은 연합학습을 ‘Collaborative Machine Learning without Centralized Training Data’로 정의하고 있습니다. 연합학습은 모든 데이터를 서버로 모아 인공지능(AI)을 학습하는 기존의 방식과는 다릅니다. 사용자의 스마트폰에서 데이터를 처리해 모델을 강화하고, 이 모델을 한곳에 모아 더 정교하게 만든 후 재배포하는 방식을 말합니다. 간단히 말하면 중앙 서버가 아닌 개별 스마트폰에서 학습하는 것입니다.
왜 이런 개념이 나왔을까요? 연합학습의 개념을 파악하기 위해서는 먼저 ‘학습’에 대한 이해가 필요합니다. 인공지능에게 학습이란, 인간과 같은 판단을 내리기 위해 미리 준비해야 하는 과정입니다. 인공지능 자체가 조건문을 통해 논리적으로 판단하는 게 아니라, 다양한 케이스의 데이터를 반복 학습한 후 판단 알고리즘을 정하기 때문입니다. 인공지능에게 학습은 필수 요소입니다. 학습이란 과정이 없이는 인공지능이라고 말하기가 어려울 정도입니다.
그런데 학습을 하기 위해서는 목적에 맞는 방대한 데이터를 가져야 합니다. 전 세계를 대상으로 서비스하는 구글이나 페이스북은 인공지능 연구가 앞서 있는데요. 이 기업들은 수많은 사용자들의 접점과 경험 데이터를 바탕으로 인공지능을 학습하고 있습니다.
인공지능 학습의 3가지 문제점
문제는 여기서 출발합니다. ▲방대한 데이터를 처리하기 위한 막대한 컴퓨팅 파워의 비용을 최소화할 수 없는가? ▲수집하는 데이터가 사용자 개인 맞춤형이 될 수 없는가? ▲방대한 데이터를 수집하는 데 개인정보보호 이슈는 없는가?
이런 고민 중 첫 번째는 인프라의 성능 이슈입니다. 학습을 위해서는 데이터를 처리하는 고성능 프로세스와 데이터를 저장하는 스토리지 용량이 필요할 수밖에 없습니다. 스토리지나 서버를 구매하고 운영하는 것은 비용이 부담이 됩니다. 더구나 최근 반도체 수급 차질로 비용이 더욱 증가할 우려도 있습니다.
두 번째는 비즈니스 이슈입니다. 그 많은 데이터가 나에게 맞는 데이터가 아니라는 점인데요. 이미지 데이터 셋만 하더라도 인종, 성별, 연령, 문화 등 다양한 차이를 반영하지 못하는 경우가 많습니다. 구매 패턴 데이터 셋도 마찬가지입니다. 시간대, 선호도 등 디테일한 차이를 반영하지 못합니다. 즉 나에게 꼭 맞는 데이터를 수집하기가 쉽지 않다는 얘기입니다. 이처럼 개인에게 맞는 데이터의 절대적인 수량이 적어지다 보니 학습 결과가 빈약해질 수밖에 없습니다.
세 번째는 보안 이슈입니다. 국내뿐만 아니라 전 세계적으로도 개인정보보호 관련 법과 제도 등이 강화되는 추세입니다. 때문에 데이터를 자유롭게 활용하기가 어려워졌습니다. 게다가, 특정 개인을 단번에 알아볼 수 없더라도 다른 정보와 쉽게 결합해 구별할 수 있는 정보도 개인정보로 분류됩니다. 이런 이유로 인터넷 등을 통해 필요한 데이터를 수집해 활용하기란 여간 힘든 게 아닙니다.
여러 이슈를 한 방에 해결하는 연합학습
연합학습은 이러한 여러 이슈를 한 방에 해결할 수 있는 대안으로 제기됐습니다. 연합학습은 스마트폰과 같이 개인 디바이스를 통해 각자 학습합니다. 이로써 컴퓨팅 자원을 분산 처리하며 해당 개인 자체의 데이터를 밀접하게 실시간으로 수집합니다. 수집된 데이터는 개인 디바이스에서 보호되므로 앞서 제시된 이슈를 해결할 수 있습니다. 스마트폰 사양이 데이터를 처리할 수 있을 만큼 좋아진 데다 기기 자체의 보안기능이 강화돼 개인정보보호가 가능하기 때문입니다.
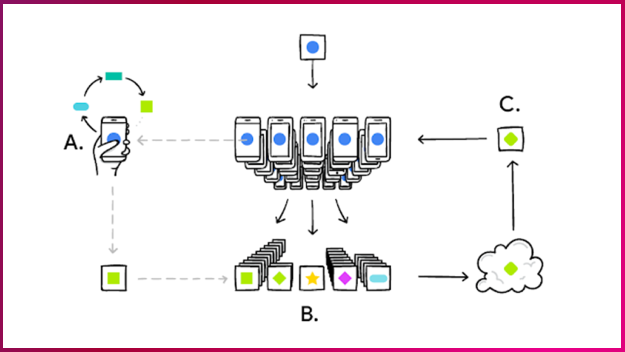
그럼, 연합학습은 어떻게 하는지 구글의 연합학습 흐름도를 통해 알아보겠습니다.
A. 초기 인공지능 학습 모델이 사용자의 로컬 스마트폰에 배포돼 개인에게 맞게 자체 학습됩니다. 여기서 인공지능 학습 모델은 인공지능을 가르치는 방식을 말합니다.
B. 학습된 결과는 계속 사용자의 스마트폰에 쌓입니다.
C. 사용자 스마트폰에 쌓인 학습 결과는 새로운 모델이 돼 글로벌 서버로 전송됩니다.
이러한 과정이 주기적으로 반복됩니다. 그런데 연합학습은 장점만 있고 단점은 없을까요? 연합학습 역시 몇 가지 단점이 존재합니다. 연합학습의 이슈와 해결과제를 알아보겠습니다.
연합학습의 이슈 해결방안과 활용 분야
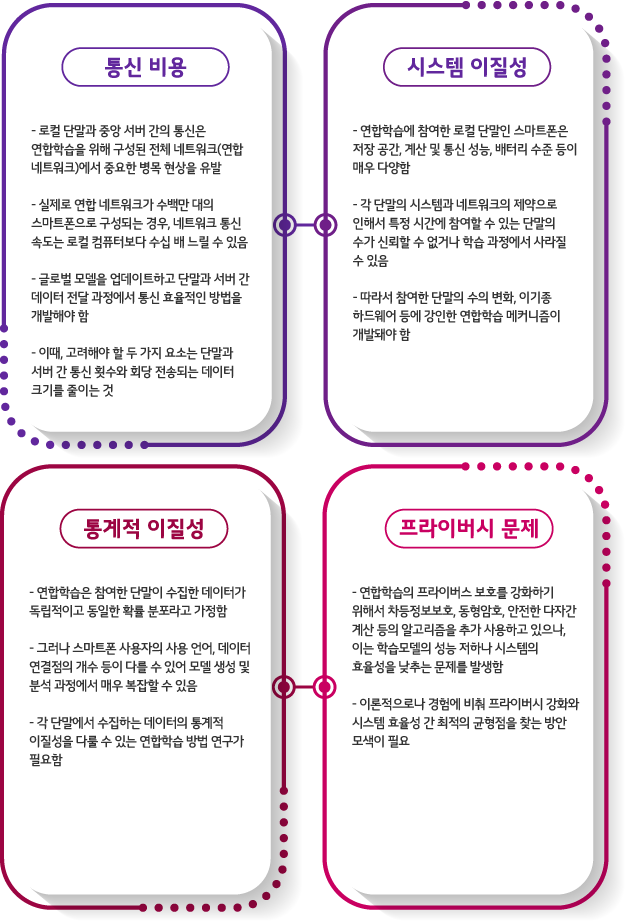
이렇듯 연합학습도 여러 단점과 해결 과제가 존재합니다. 하지만 여러 분야에서 연합학습을 적용하려는 시도가 존재하는데요. 그 중에서 가장 활발히 진행되고 있는 분야는 의료 도메인입니다.
지금까지 의료기관은 개인 의료 정보가 풍부하게 있어도 법적 규제로 인해 인공지능의 활용이 제한됐습니다. 환자 한 명 한 명의 의료 데이터는 여러 병원에 분산돼 저장돼 있는데요. 프라이버시와 의료법 등으로 병원 간의 데이터 공유 및 협업이 어려웠습니다. 그러나 연합학습은 여러 병원에 분산돼 있는 특정 질환의 데이터를 공유하지 않고도 모든 데이터를 한곳에 모아 분석한 것과 같은 효과를 기대할 수 있습니다.
그래서 인텔이나 엔비디아에서는 글로벌 의료기관과 협력해 연합학습을 실증하고 있는데요. 인텔 랩과 펜 메디슨, 엔비디아와 킹스 칼리지 런던이 그 사례입니다.
인텔 랩은 펜실베이니아 대학교 페럴만 의대와 협력하고 있습니다. 29개 국제 보건의료 및 연구 기관 연합체는 각자 보유한 의료 데이터를 공유하지 않고 프라이버시 보장형 인공지능 학습모델을 개발했습니다. 이를 통해 현재 뇌종양 조기 식별을 목표로 추진하고 있습니다.
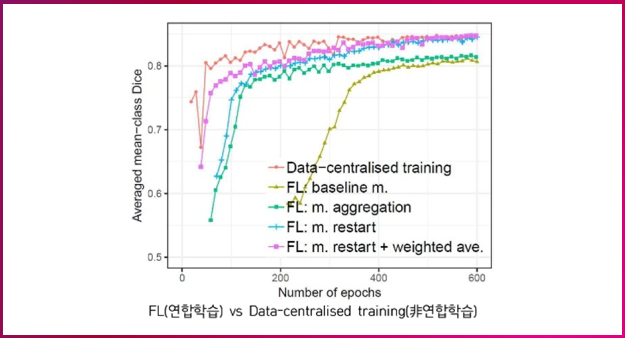
그 과정에서 인텔 랩은 2018년에 의료 영상 기술 학회(MICCAI)에서 한 논문을 발표했는데요. 이 논문은 연합학습 기반의 뇌종양 식별이 기존 인공지능 학습 방법과 비교해 정확도99% 이상에 근접하다는 것을 입증하고 있습니다. 2020년에도 국제 뇌종양 분할 시험 데이터 셋을 이용해 개선된 알고리즘을 개발하고 있습니다.
엔비디아도 2019년에 북미방사선의학회(RSNA)에서 인공지능 의료 시스템인 ‘클라라 연합학습’을 발표했습니다. 미국영상의학회(ACR), UCLA 방사선학과, 뉴잉글랜드 파트너스 헬스케어, 캘리포니아대에서 ‘클라라 연합학습’을 시범 운용하고 있습니다. 또한 영국의 킹스 칼리지 런던, 오우킨 등과 제휴해서 국가보건서비스를 위해 연합학습 플랫폼을 구축하고 있습니다. 2020년에도 미국 의료계와 협업해 유방조양 및 조직밀도 평가와 성능을 개선한 연구 결과를 발표한 바 있습니다.
이 밖에도 연합학습은 제조 분야, 금융 분야, 교육 분야 등 다양한 분야에서 활용될 수 있습니다. 마이데이터 사업에서의 활용 역시 기대됩니다. 또한 다양한 분야의 프라이버시 강화뿐만 아니라 보안 기술 자체에도 적용될 수 있는데요. 그 중 하나가 안면 인증입니다. 개인 스마트폰에 저장된 자신의 이미지를 학습하고 그 결과를 중앙서버에 전송합니다. 이렇게 다시 업그레이드된 알고리즘을 통해 자신에게 특화되고, 더욱 정확한 안면 인증을 할 수 있다는 것입니다.
지금까지 최근 연구 및 실증이 활발한 연합학습에 대해 알아봤습니다. 연합학습은 인프라 비용적인 측면에도 장점을 지니지만, 특히 보안에 강점이 있습니다. 앞으로 연합학습이 더욱 다양한 분야와 기술에 적용돼 ‘저비용 고보안’이라는 두 마리 토끼를 잡는 인공지능 시대가 오기를 바랍니다.
[출처]
Google AI Blog(https://ai.googleblog.com/2017/04/federated-learning-collaborative.html)
IT동아(https://it.donga.com/29420)
Tian Li et al.(2019) Federated Learning: Challenges, Methods, and Future Directions, arXiv:1908.07873v1.
한국전자통신연구원 기술정책 트렌드2020-6
글ㅣ LG CNS 사이버시큐리티팀


