행동(Action)과 관련된 분야의 인공지능 기술은 인간 수준으로 구현되기 매우 어려운 분야로 생각되어 왔습니다. 인간 수준의 행동이란 단순히 현재 만을 고려해 행동하는 것이 아니라 현재의 행동이 미래에 미치는 영향을 고려하고 동시에 최종적인 목적을 달성하기 위해 매 순간 계획(Planning)과 결정(Decision)이 동반되어야 하기 때문입니다.
그렇기 때문에 때로는 현재 시점에서 최선의 선택이 아니더라도 장기적 관점에서 목적 달성에 도움이 된다면 차선책을 선택해 행동하는 것도 필요합니다. 이러한 모든 과정이 고려되어야 하므로 인간처럼 행동하는 인공지능을 구현하기는 쉽지 않았는데요.
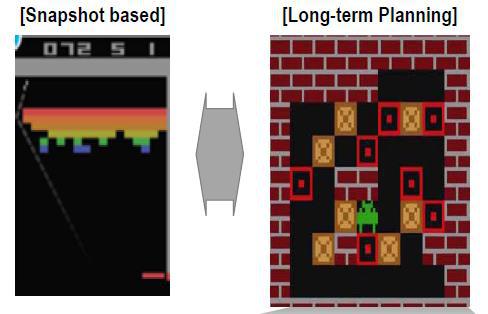
하지만 최근 발표된 연구는 이러한 인간과 같은 행동 방식을 인공지능으로 구현해 내고 있습니다. 딥마인드가 발표 한 인공지능은 인간처럼 미래를 예측하며 장기적 관점에서 계획하며 행동합니다. 완벽한 수준은 아니지만, 인간과 같은 행동과정의 구현 시작이라는 점에서 큰 의미가 있습니다. 앞서 연구된 강화학습의 경우 인공지능은 매 순간 최고의 보상(Reward)을 받을 수 있는 행동(Action)을 반복하며 목표를 달성해 갑니다.
물론 순간순간 최선의 선택을 반복하는 것이 최종 목적을 달성하기 위한 가장 이상적인 행동일 수도 있습니다. 딥마인드가 2년 전 구현한 게임환경(Atari Game)의 인공지능의 문제가 이에 해당할 것입니다.

반면, 딥마인드의 이번 연구는 인공지능이 매 순간의 행동에 대해 미래에 미치는 영향을 상상(Imagination)해 최적의 행동을 선택합니다. 이 과정에서 최종의 목적을 달성하기 위해 인공지능은 장기적 관점에서 계획(Long-term Planning)하고 행동합니다.
현재 시점에서 선택이 손해를 보더라도 이러한 행동이 최종 목적 달성을 위한 과정이라고 판단된다면 행동하는 것인데요. 이러한 점에서 기존 강화학습 등과 같은 연구들과는 큰 차이를 갖습니다.

딥마인드는 이러한 과정을 ‘Sokoban’이라는 게임에 적용해 증명했습니다. 위 그림과 같이 다수의 벽돌을 지정된 위치에 모두 옮기게 되면 해당 레벨을 완료하는 게임인데요. 이 게임은 벽돌을 옮길 때 한 번의 실수가 게임 전체에 영향을 미칠 수 있다는 점(벽돌을 모서리에 이동시키면 회복할 수 없음)과 최소한의 움직임으로 벽돌을 옮기는 것이 항상 옳은 선택은 아니라는 점에서 게임의 레벨이 상승할수록 매우 어려워집니다.
즉, 게임을 진행하면서 앞서 설명된 매 순간 앞으로 일어날 상황을 상상하고 계획에 기반을 둬야 하는 인간의 행동에 기반이 되는 특성을 모두 반영하고 있습니다. 게임을 진행하며 딥마인드의 인공지능은 현재의 행동이 향후 미치는 영향을 상상합니다.

상상한 결과에 따라서 현재의 선택이 최선은 아니더라도 최종 목적 달성에 도움이 된다고 판단되면 행동하는 것입니다. 예를 들어 벽돌을 바로 옆 칸으로 한 번 이동시키면 될 경우도 더 먼 거리에 있는 벽돌을 선택해 해당 칸으로 벽돌을 이동시키기도 하는 것입니다.
그동안 매우 어렵고 오랜 시간이 걸릴 것으로 예상했던 행동 분야의 인공지능 구현의 시작은 추론 분야의 지능 발달과 함께 향후 인공지능 분야 연구에 큰 혁신을 만들어 갈 것으로 전망됩니다. 최근 2년 동안 빠르게 발전한 인지학습 분야의 지능 발달에 힘입어 이러한 추론, 행동 분야의 지능 구현은 각 산업 영역에 적용되는 인공지능을 한층 더 고도화 시킬 수 있습니다.

그동안 인지•학습 기능이 적용된 인공지능만으로는 미래를 예측•추론해 행동하는 역할을 완벽히 구현할 수는 없어 인간의 개입이 요구됐습니다. 하지만 이러한 의사 결정, 판단의 전 과정에 인공지능이 구현된다면 장기적으로는 상당한 산업 분야에서 인간을 대체하는 인공지능이 구현될 가능성도 높을 것입니다.
글 | 이승훈 책임연구원(shlee@lgeri.com) | LG경제연구원


