기업 측면에서 수요의 예측은 생산, 자재 및 물류 등의 계획과 관리 측면에서 중요합니다. 수요를 잘 예측하면 창고에 제품별 재고 비축을 하는 것이 효율적인지 계획할 수 있고, 생산지에서 창고로 제품을 이동하는 물류에 대한 계획도 가능할 수 있습니다. 해당 제품을 생산 할 때 필요한 원재료의 구매부터 비축에 대한 계획도 가능합니다.
이렇게 생산된 제품에 대한 선적 계획도 가능하게 되므로 수요의 예측은 기업의 SCM(Supply Chain Management, 공급망 관리)에서 가장 중요한 부분을 차지할 것입니다. 수요 예측은 특히 과거의 수요 트렌드(Trend)를 학습해 미래 수요를 예측하는 시계열 모형이 많이 사용되었던 분야입니다.

전통적인 시계열 모형으로는 예측하고자 하는 값이 과거 시점에 영향을 받는 자기 회귀 모형(Autoregression model), 모형이 설명하지 못하는 오차 혹은 변동값을 이용해 현시점의 값을 예측하는 이동 평균 모형(Moving Average model), 차분, 자기 회귀 및 이동 평균을 고려하는 자동 회귀 누적 이동 평균(ARIMA: Autoregressive integrated moving average) 등이 존재합니다.
위와 같은 전통적인 시계열 모형들은 과거 데이터의 패턴과 오차만을 가지고 미래를 예측하려는 점에서 공통점을 가지고 있습니다. 최근에는 과거 데이터 외에도 해당 과거 시점별 수요에 영향을 미치는 독립 변수들을 학습하는 다양한 예측 모형이 만들어졌습니다.
대표적으로 ARIMAX 모형이 있습니다. 이 모형은 예측하려는 수요에 영향을 미치는 독립 변수를 발굴해 미래 시점의 독립 변수 바탕으로 미래 수요를 예측하는 모형입니다.
딥러닝을 이용한 RNN(Recurrent Neural Network, 순환 신경망)의 한 종류인 LSTM(Long Short-Term Memory)도 있으며, Facebook의 forecasting 라이브러리인 Prophet은 GAM(Generalized Additive Model, 일반화 가법 모형)에 시계열 예측으로 발전시킨 모형도 있습니다.
이처럼 다양한 시계열 모형들이 존재하며 모형별 장•단점, 그리고 우리가 가지고 있는 데이터의 특성을 파악하고 선별해 적용하는 것이 분석가가 하는 일 중 하나입니다. 이 글에서는 시점을 고려하는 예측 모형과 함께 머신러닝을 적용하는 방법을 중심으로 알아보기로 하겠습니다.

먼저, 다양한 머신러닝 모형을 사용해 학습 및 예측할 때 경쟁의 개념을 추가한 과정에 대해 알아보겠습니다.
● 학습 데이터 수집
학습 단계에서는 과거 해당 시점에 영향을 미칠 가능성이 큰 다양한 학습 데이터를 수집해야 합니다. 무엇보다도 중요한 점은 해당 데이터들은 미래에도 수집할 수 있어야 한다는 것 입니다. 미래에 수집할 수 없는 데이터로 학습한 모형은 결국 예측하는 데 사용할 수 없기 때문입니다.
● 변수 생성
이렇게 다양하게 수집된 학습 데이터들을 이용해 EDA(Exploratory Data Analysis, 탐색적 데이터 분석)와 상관 계수와 같은 검증 통계량을 통해 변수 간의 관계를 파악합니다. 또한 파생 변수들을 생성해 그 파생 변수와 예측하고자 하는 수요와의 관계를 파악하는 과정들을 통해 수요에 큰 영향을 미칠 수 있는 변수들을 생성합니다.
● 학습
생성한 다양한 변수들이 존재하는 과거 데이터로 시계열 모형(ARIMAX)과 Random Forest, XGBoost 및 LGBM regression 등의 머신러닝 모형을 학습시킵니다.
● 평가
학습된 모형들을 사용해 과거의 특정 기간을 평가 대상으로 예측하고 각 모형의 수요 예측값과 해당 시점의 실제 수요값을 비교해 최소 오차를 가지는 모형을 최적 모형으로 선정합니다. 정답지를 사용해 예측 정확도를 평가하는 것은 중요합니다.

잔차(Residual)의 크기를 예측 정확도의 평가로 사용하는 것은 적절하지 않습니다. 예측치의 정확도는 모형이 학습할 때 사용하지 않은 새로운 데이터를 얼마나 잘 맞추는지 여부로 결정하는 것이 적절합니다. 오차를 사용해 예측의 정확도를 평가하는 지표들은 다양합니다.
평가 지표 중 특정 지표를 사용하거나 모든 지표를 사용해 지표별 랭킹 합산을 최적 모형의 선정 기준으로 사용할 수도 있습니다. 전통적인 평가 방식보다 다양한 기간을 Validation-set으로 사용해 모형을 평가하는 것이 특정 기간에만 영향을 받지 않는 평가 방법입니다.
● 예측
제품별로 평가 기간에 가장 오차가 작은 모형을 선정하여 학습에 사용한 변수들의 미래 데이터로 미래 수요를 예측하는 것입니다. 이렇게 다양한 기간을 Validation-set으로 사용해 모형을 평가하는 방식과 달리 Ensemble을 적용하고 예측하는 방법도 있습니다. 일반적으로 특정 평가 기간에만 잘 예측하는 모형을 찾는 방법보다Ensemble learning이 예측 분산을 줄이는 효과를 기대할 수 있습니다.
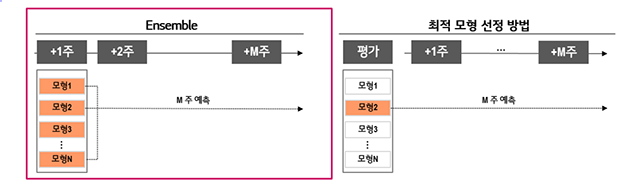
이러한 Ensemble 기법에는 Stacking, Voting, Bagging, Boosting이 있습니다. 대표적으로Stacking Ensemble 이란 학습 데이터로 학습된 개별 모형들이 생성한 예측 데이터를 기반으로 최종 모형이 학습할 별도의 학습 데이터를 생성하고 학습하는 기법입니다.
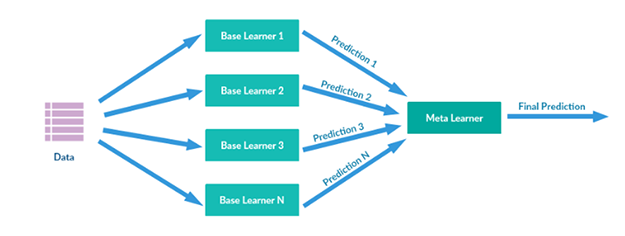
위 그림과 같이 각 Base Learner(Level-0 Models, Base-Models)는 과거 데이터를 학습한 개별 모형입니다. 다양한 Base Learner가 예측한 수요값과 해당 기간의 실제 수요값으로 새로운 학습 데이터로 구성하고 학습하는 최종 모형이 Meta Learner(Level-1 Model, Meta-Model)입니다. 이렇게 학습한 Meta Learner로 수요 예측을 하는 방법도 가능합니다.
● 수요 예측 시 고려사항
마지막으로 수요 예측 시 고려해야 할 사항으로 첫째, 미래 수요 트렌드는 다양한 요인들로 과거와는 다르게 변화할 수 있습니다. 한 예로 최근 코로나19로 인해 우리의 생활 패턴과 함께 소비 트렌드도 변화하고 있습니다. 이처럼 새로운 요인으로 소비 경향이 바뀐다면 새로운 수요 트렌드를 반영할 수 있는 데이터들을 발굴하고 모형이 학습할 수 있도록 데이터를 구성해야 합니다.
둘째, 새로운 영역 또는 기존 제품을 대체하는 신제품과 같이 과거 데이터가 부재해 학습이 어려운 상황도 발생할 수 있습니다. 특히 기존 제품을 대체하는 신제품 수요 예측의 경우에는 먼저 과거 데이터를 통해 기존 제품의 수요를 신제품이 대체하는지 확인하고 미래 예측은 Rule에 의해 모형을 보완하면 예측 정확도를 높일 수 있습니다.
지금까지 머신러닝을 이용한 수요 예측에 대해 알아보았습니다. 수요 예측뿐만 아니라 다양한 모형의 장•단점, 그리고 우리가 가지고 있는 데이터의 특성을 파악하고 모형을 선별해 적용하는 것이 분석가가 하는 일 중 하나입니다
무엇보다도 분석가의 가장 매력적인 부분은 문제점(여기서는 수요 예측)을 해결하기 위해 어떻게 학습과 추론 데이터를 구성해야 하는지 고민하고 만들어가는 과정이라고 생각하며 이 글을 마칩니다.
글 l LG CNS Enterprise분석2팀
[참고 문헌]
- AFIT Data Science Lab R Programming Guide: https://afit-r.github.io/ts_benchmarking
- Fine-Grained Time Series Forecasting At Scale With Facebook Prophet And Apache Spark: https://databricks.com/blog/2020/01/27/time-series-forecasting-prophet-spark.html


