인간의 오감은 시각, 청각, 후각, 미각, 촉각입니다. 현재 후각, 미각, 촉각은 인공지능을 통해 쉽게 접할 수 있는 영역은 아니지만, 시각과 청각에서는 인공지능이 큰 활약을 펼치고 있습니다. 특히, 눈은 이미지와 영상을 통해 인간이 가장 많은 정보를 얻을 수 있는 기관입니다.
인공지능은 이미지와 영상을 빠르게 인식하고 학습하는 능력을 갖추고 있습니다. 새로운 이미지를 스스로 만들거나 보정하는 등, 인간이 접할 수 있는 이미지의 세계에서 다양한 작업을 수행합니다. 이미지 세계에서 인공지능이 활약하는 영역은 크게 두 가지로 나눌 수 있습니다. 이미지를 인식하고 분류하는 영역과 이미지를 생성 및 변환하는 영역입니다.

사람보다 정확한 눈으로 보다
최근 인공지능 머신러닝 분야에서 가장 관심이 집중되는 기술은 바로 ‘이미지 인식(Image Recognition)’ 입니다. 이미지의 정보를 식별하는 기술로써 컴퓨터 비전 분야에서 오랫동안 연구된 기술 중 하나입니다. 이미지 인식은 단순히 사진 한 장을 인식하는 것이 아니라, 자율주행을 위한 무인 자동차 개발, 사람 얼굴을 인식하는 안면 인식, 의료 진단을 위한 엑스레이 사진 분석 등 다양한 산업에 적용됩니다.
이미지 인식을 위해서는 인식한 이미지가 어떤 종류인지 나누는 ‘분류(Classification)’를 가장 먼저 진행합니다. 이미지의 위치를 확인한 후, 이미지 내의 객체(사람, 동물, 장난감 등)를 대략 구분해 추출합니다. 마지막 단계에서 객체를 실제 모양에 따라 정확하게 추출하는 과정을 거칩니다. 이러한 단계는 이미지 인식 기술의 실행과 품질에 직접적인 영향을 미칩니다.
이미지 인식 기술이 자리 잡을 수 있었던 계기에는 합성곱 신경망(CNN, Convolutional Neural Network)과 이미지 빅데이터의 등장이 결정적입니다.
CNN은 이미지, 비디오, 오디오 등을 분류하는 딥러닝에서 주로 사용되는 알고리즘이며, 이미지에서 얼굴, 객체 등을 인식하는 패턴을 찾는 데 유용합니다. CNN은 자동으로 특징을 학습하거나 기존 네트워크를 기반으로 CNN을 재학습하고 새로운 이미지 인식하도록 만들 수 있는 장점이 있습니다. 여러 장점과 좋은 성능 때문에 컴퓨터 비전이 필요한 분야에 CNN이 널리 활용되고 있습니다.
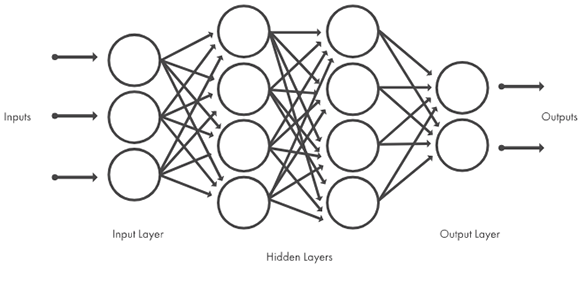
인간의 시각 피질 작동 원리에서 출발한 CNN은 시각 피질처럼 여러 중첩이 존재합니다. 복잡하게 얽혀 있는 각 계층은 데이터 특징을 학습하기 위해 샘플링, 계산, 출력 등의 과정을 진행합니다. 이러한 과정이 수십, 수백 개의 계층에서 반복되면서 여러 특징을 추출합니다. 이런 중첩과 복잡한 신경망 구조를 높은 컴퓨팅 성능으로 해결하면서 인간의 시각 인식과 비슷한 수준이 됐습니다.
이미지 인식을 위한 데이터도 빼놓을 수 없습니다. 이미지 학습을 위해서는 대량의 이미지 데이터가 필요합니다. 과거보다는 이미지 데이터를 확보하기 쉬워져서 이미지 인식 기술 발전이 더욱더 빨라졌습니다. 과거 스마트폰이나 클라우드가 없었던 이미지 데이터를 모으는 것도 벅찼지만, 지금은 대량의 이미지 데이터를 언제 어디서나 내려 받을 수 있고, 이미지 데이터를 직접 촬영 하는 방법도 쉽고 다양합니다.
수많은 이미지 데이터를 기반으로 이미지를 인식하는 대표적인 서비스로 구글의 ‘구글 포토’가 있습니다. 구글은 2015년 5월 구글 포토 서비스를 시작했는데, 이미지 인식을 통해 사진을 자동으로 정리해주거나 검색 결과를 사용자에게 보여줍니다.
구글은 딥러닝을 통해 이미지를 학습하며 자동으로 라벨링이 가능한 수준으로 발전했습니다. 또한, 구글 검색에서 이미지를 올리거나 이미지가 있는 URL을 넣으면 이미지를 인식해 같은 사진과 비슷한 사진을 추천해주는 기능도 제공합니다. 이러한 서비스는 모두 인공지능 기반 이미지 인식 기술의 결과물입니다.
인공지능 이미지 인식 기술은 구글, 엔비디아, 알리바바 등 글로벌 IT 기업을 비롯해 국내 기업들도 기술 개발에 투자하고 있습니다. LG CNS는 2018년 인공신경망 학회가 주최한 ‘이미지 인식 AI’ 대회에서 4위를 기록하며 이미지 인식 기술에 대한 기술력을 선보인 바 있습니다.
이미지 인식 기술의 응용 분야는 다양합니다. 이커머스에서는 이미지를 올리면 인공지능이 데이터베이스 내의 상품과 가장 유사한 상품을 추천해 소비자의 쇼핑을 돕는 기능을 제공합니다. 명품의 진위를 가려내는 감정에도 인공지능 기반 이미지 인식이 활용됩니다. 프로야구 하이라이트 영상을 인공지능이 편집해서 제공하거나, 엑스레이 사진을 보고 인공지능이 의료 진단을 하는 등 이미지 인식 기술의 발전과 활용 범위는 무궁무진합니다.
새로운 이미지를 만들어내는 딥러닝
인공지능은 이미지 인식은 물론 이미지를 생성하고 변환하는 능력까지 갖추었습니다. 한 웹사이트는 이미지를 무료로 사용할 수 있다며 여러 사람의 얼굴 이미지를 공개했습니다. 초상권과 관계없이 사용할 수 있는지 문의가 이어졌고, 알고 보니 인공지능이 만들어낸 이미지로 실제로 존재하지 않는 사람들이어서 충격을 줬습니다.
이미지 분류, 인식을 위해서는 주로 CNN을 활용해 주어진 데이터의 패턴을 학습하고 분류, 인식하는지에 집중하는데, 이미지 생성과 변환은 적대적 신경망(GAN, Generative Adversarial Network)을 활용합니다. GAN은 2014년 인공지능의 권위자인 이안 굿펠로우(Ian Goodfellow)가 소개한 이후 지속해서 발전해왔습니다.

GAN은 구글이 2016년 DCGAN (Deep Convolution Generative Adversarial Network)을 선보이며 학습의 안정성이 높아지며 비약적으로 발전하게 됩니다. DCGAN은 GAN에 이미지 분류에 탁월한 CNN을 넣어 만든 모델입니다. CNN이 이미지의 주요 특징과 중요한 값을 추출하는 성능이 뛰어나 학습이 잘되는 장점이 있어, 이를 GAN에 적용해 이미지 생성의 수준을 높일 수 있게 됐습니다.
GAN은 WGAN(Wasserstein GAN), 2017년 발표된 BEGAN(Boundary Equilibrium GAN) 등을 거치며 발전을 거듭하고 있습니다. GAN은 용도와 목적에 따라 다양한 알고리즘이 등장하며 GAN의 이미지 생성은 물론 변환도 함께 발전 중입니다. 최근에는 인공지능이 웹툰으로 유명한 이말년 작가의 화풍을 10시간 동안 학습해 사람 얼굴을 이말년 작가의 그림체처럼 만들어내 화제를 불러모았습니다.
해당 알고리즘은 StyleGAN을 사용해 약 500여 장의 캐릭터 그림을 학습했습니다. StyleGAN은 자연스러운 이미지를 만들기 위해 이미지를 스타일의 조합으로 여기고 GAN의 각 층에서 여러 스타일 정보를 입혀 이미지를 합성합니다. 각 스타일의 구성 요소(머리카락 색, 성별) 등을 조절할 수 있어 기존보다 훨씬 자연스러운 이미지를 생성합니다.

이미지 변환에는 CycleGAN을 활용합니다. CycleGAN은 두 개의 다른 이미지가 매칭되지 않아도 이미지 변환을 가능하게 만듭니다. 예를 들어 구두와 가방의 이미지가 있으면 두 이미지 사이의 공통점을 찾아내 다른 이미지에 스타일을 입혀 변환할 수 있습니다. CycleGAN이 이미지의 스타일에 집중한다면 DiscoGAN은 형태의 변화에 특화된 알고리즘입니다. 두 GAN 알고리즘은 원리는 유사하고, 완벽히 쌍(Pair)을 이루는 데이터 세트가 없어도 이미지를 변환할 수 있는 특징이 있습니다.

이 밖에도 다양한 이름의 GAN이 계속 등장하고 있습니다. ProGAN과 SRGAN은 이미지의 해상도를 높이고, StarGAN은 원하는 부분에 대해서만 이미지 변환이 가능한 알고리즘입니다. 만약 이미지에서 사람의 머리색만 다른 색으로 바꾸고 싶다면 StarGAN을 사용할 수 있습니다.
인공지능이 만드는 이미지의 품질이 좋아지고 활용성이 높아지면서, 많은 기업이 GAN 알고리즘 연구에 더욱더 몰두하고 있습니다. 세계적인 IT 기업인 엔비디아는 자체적으로 개발한 다양한 GAN을 공개하고 있습니다. 엔비디아는 후기 인상파 대표 화가인 고갱의 이름을 딴 GauGAN을 공개했습니다. 캔버스 위에 그림을 그리면 실제 사진과 같은 이미지를 만들어 냅니다.
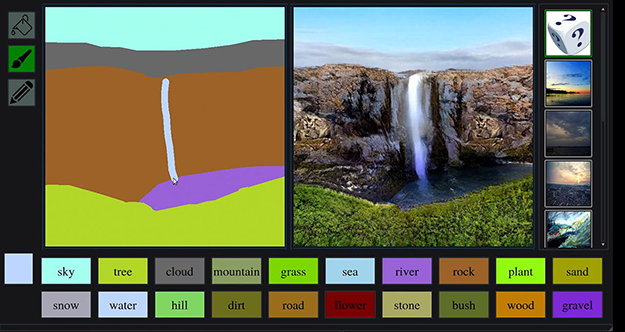
GAN은 현실에 존재하지 않는 사람의 이미지를 새로 만들기도 하며, 손으로 그린 그림에 색을 입혀줍니다. 고흐나 피카소와 같은 유명 미술가의 화풍을 학습해 취향에 맞춘 다른 그림으로 변환하고, 낮은 화질의 사진을 고화질로 만듭니다. 심지어 과거에는 손으로 일일이 작업이 필요했던 특정 이미지의 배경을 제거하는 작업을 이제는 클릭 한 번으로 할 수 있습니다. 인간이 많은 시간을 들여야 하는 일을 인공지능이 하고 있습니다.
인공지능 이미지 세계
인공지능은 이미지 세계에서 이미 많은 일을 하고 있습니다. GAN을 활용해 초상권이나 저작권 문제가 없는 이미지를 만들 수도 있고, CNN 기반의 이미지 인식으로는 상한 식품을 감지하거나 범죄자의 안면 인식도 가능합니다.

디자이너의 스타일과 패턴을 익힌 GAN이 새로운 디자인이나 이미지를 만들어내거나, 인간이 스케치 일부분만 그리면 나머지는 인공지능이 완성하는 작업도 가능합니다. 중국의 IT 기업 알리바바는 2017년 행사 기간에 웹사이트에서 사용할 광고 배너를 무려 4억 개를 만들었습니다. 1초에 8,000개의 각기 다른 디자인을 만들어낼 수 있었던 원동력은 바로 인공지능이었습니다.
끊임없이 제공되는 이미지 데이터와 학습을 통해 인공지능은 새로운 이미지 세계를 만들어가고 있습니다. 인공지능이 만드는 이미지 세계의 발전은 다양한 알고리즘의 등장과 더불어 앞으로도 계속될 전망입니다.
글 l 윤준탁 l IT 저널리스트


