기업 간의 경쟁이 심화되면서 기업들이 소비자들의 다양한 욕구를 파악하고 이를 충족할 수 있는 제품이나 서비스를 지속적으로 개발할 필요성이 증가되고 있습니다. 2000년대 들어 여러 기업들이 전개한 고객관계관리(CRM: Customer Relationship Management)도 이러한 소비자 욕구 변화에 대응하기 위한 마케팅 패러다임이라고 할 수 있을 것입니다.

이를 위한 첫 번째 단추는 당연히 소비자의 욕구를 파악하는 일이 될 것입니다. 그러나 소비자의 욕구를 파악하는 일은 그리 쉬운 일이 아니라는 문제점이 있습니다.
SNS의 발달, 솔직한 고객의 이야기에 귀를 기울이다.
인터넷의 발달과 소셜 미디어의 등장으로, 사람들은 SNS에 그들의 일상적인 사건이나 감정들은 물론 선호하는 브랜드나 제품에 대한 다양한 의견들을 게시하고 있습니다. 페이스북이나 트위터와 같은 소셜미디어는 사람들의 의견들을 게시하고 공유하는 통로 역할을 하고 있는데, 기업들에게 이러한 소셜미디어에서 공유된 데이터들은 고객들의 제품 선호도 및 브랜드 이미지를 파악하는 중요한 수단이 될 수 있습니다.

SNS가 존재하지 않던 시절, 대부분의 기업 마케터들은 고객들의 선호도나 제품에 대한 평가를 파악하기 위해 인터뷰나 설문조사를 통해 그 데이터를 수집해 왔습니다. 그러나 인터뷰나 설문조사의 결과를 반영하여 시행된 대규모 프로모션이 안타깝게도 예상했던 결과를 얻지 못하는 경우가 발생했습니다. 이는 응답자들이 인터뷰나 설문조사에 임할 때 솔직한 응답보다는 대상을 후하게 평가하는 경향이 있기 때문으로 이해됩니다.

이에 대한 대안으로 사용할 수 있는 방법이 SNS 상의 게시된 글을 통해 고객의 소리를 듣는 것입니다. 고객들이 SNS 상에 글을 올릴 때는 솔직한 생각이나 느낌을 표현할 것이라고 판단하는 것이죠. 그래서 기업에서는 이를 브랜드에 대한 인지나 태도를 분석하는데 사용하기 시작했는데요, 점점 그 활용 사례가 늘어나고 있습니다.
SNS 데이터를 활용하여 고객 마음을 읽어보자: 화장품 브랜드
화장품 산업은 여러 브랜드가 시장에서 경쟁하고 있으며, 고객은 각자의 마음 속에 특정 브랜드에 대한 나름대로의 평가를 하고 있는데요. SNS에서 어떤 브랜드 이름이 어떻게 언급되는가를 분석해 보면 고객의 마음을 읽을 수 있는 유용한 방법이 될 수 있습니다.
예를 들어 A라는 브랜드가 B라는 브랜드 보다 더 자주 언급된다면, A 브랜드에 대한 고객의 인지도는 B 브랜드 보다 높다고 볼 수 있습니다. 이를 확장하여 고객이 게시한 하나의 글에 여러 개의 브랜드가 동시에 언급되어 있다면 이를 어떻게 해석해야 할까요? 동시에 언급된 브랜드가 있다면 글을 게시한 고객이 비슷하게 인지하는 브랜드라고 보는 것이 타당하지 않을까요? 그래서 다음과 같은 가정을 해 보았습니다.

<가정>
SNS 상에서 두 개의 브랜드가 함께 언급되는 빈도가 많을수록,
소비자들이 두 브랜드를 더 유사하게 인식할 것이다.
이러한 가정이 맞는지 보기 위해 사례 연구를 해 보았습니다. 고객의 인지를 SNS 데이터를 통해 파악하고 이를 2차원이나 3차원 공간에 표시하고, 동시에 비슷하게 인지되는 브랜드를 군집분석(유사집단으로 구분하는 분석기법)으로 파악해 보는 것입니다.
브랜드의 개수가 너무 적다면 군집들이 너무 적게 생성되고 브랜드가 너무 많으면 결과에 대한 직관적인 이해가 어려워지기 때문에 화장품 브랜드들 중 가장 선호되는 30개의 브랜드를 선별하였고, 블로그와 트위터에서 얻어진 SNS 데이터를 60일간 수집한 후 특정 브랜드가 다른 브랜드와 함께 언급된 빈도를 계산했습니다. 이를 정리하면 [표1]과 같은 결과를 얻을 수 있었습니다.
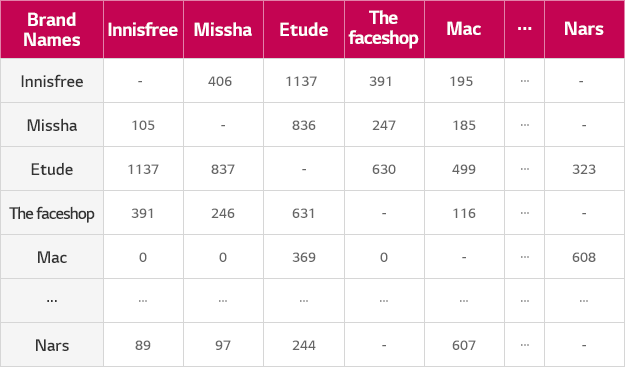
[표1]을 기준으로 언급된 빈도가 높은 브랜드들은 브랜드 사이의 거리를 가깝게 변환하고, 반대로 언급된 빈도가 낮으면 거리를 크게 변환하는 방법을 통해 브랜드들 사이의 거리를 계산했습니다. 통계적 분석방법인 다차원 척도법(MDS: Multi-Dimensional Scaling)를 사용하여 모든 브랜드들을 직관적인 해석이 가능하도록 2차원 및 3차원 공간에 나타내 보았습니다.
브랜드들의 좌표를 계산한 후 브랜드들의 군집(클러스터)들을 식별하는 단계를 거쳤습니다. 본 연구에서는 군집들을 파악하기 위해 k-means 클러스터링을 사용하였는데, k-means 클러스터링은 n 개의 대상물을 k 개의 클러스터로 분할하는 기법입니다. [표2]과 [표3]은 각각 2차원과 3차원 공간에 브랜드들을 나타낸 것이며, 같은 군집에 속하는 브랜드들은 동일한 모양의 기호로 나타내 보았습니다.
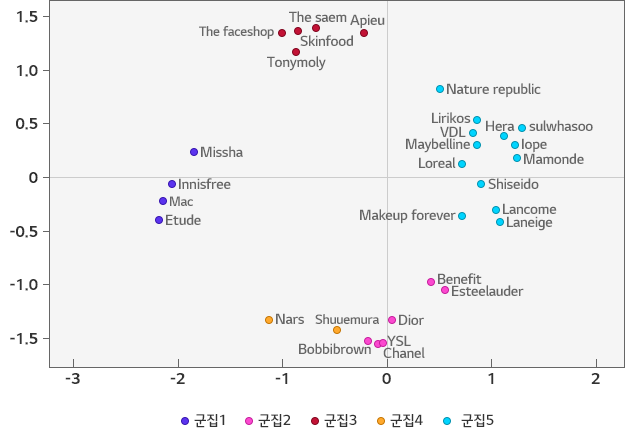
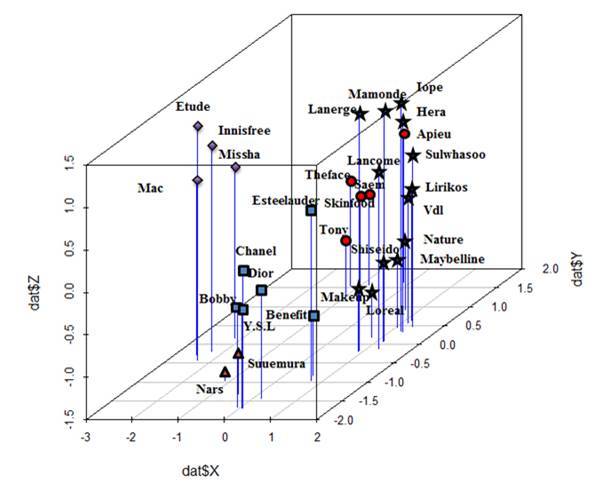
클러스터링 결과 30개의 브랜드는 총 5개의 군집으로 나타났는데, 각각의 군집의 특성을 간략하게 설명하자면 다음과 같았습니다. 군집 1과 3은 대표적인 저가 브랜드이며, 10대 후반에서 20대 초반의 여성들이 주된 고객으로 볼 수 있습니다.
군집 3은 군집 1보다는 상대적으로 가격대가 높다는 점에서 두 군집 간의 차이가 있었으며 군집 2는 대표적인 해외 명품 브랜드이며, 가격대가 매우 높고, 기능성 제품보다는 색조 화장품과 향수제품에 특화된 브랜드로 해석됩니다.
그리고 군집 4는 한 가지 제품군에 특화된 브랜드인데, 예를 들어 나스는 립스틱이, 슈에무라는 아이브로우 제품이 주력상품이었습니다. 마지막으로 군집 5는 대체적으로 고가의 브랜드이며, 기능성 제품을 포함한 다양한 제품군들을 보유하고 있다는 특징이 있었습니다.
각각의 군집들의 특징들을 살펴본 다음, 군집들이 적합하게 나눠졌는지 보기 위해 각 군집들 간의 거리를 계산했습니다. 같은 군집 내에 속하는 브랜드들 간의 거리는 가까워야 하지만, 각각의 군집간 거리는 멀어야 군집들이 적합하게 나누어졌다고 볼 수 있습니다.
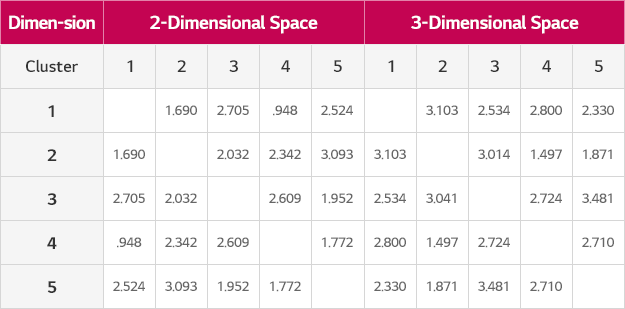
이처럼 소셜미디어 데이터를 활용한다면 마케팅 담당자가 고객의 선호도와 브랜드 인지를 이해하는데 통찰력을 제공할 수 있을 것으로 기대됩니다. 다만 이를 위해 많은 데이터를 수집 분석해야 하는 어려움이 있을 수 있으나, 고객의 솔직한 마음을 읽을 수만 있다면 기업 입장에서는 충분히 투자해 볼 만한 영역으로 생각됩니다.

향후 추가 연구로 SNS 상에 나타난 사람들의 감정을 나타내는 감정단어(Sentiment Words)를 고려하여 브랜드 클러스터링 분석에 추가한다면 더 정교한 결과를 얻을 수 있을 것으로 기대됩니다.
우리 제품에 대한 고객의 마음이 궁금하시다면 앞으로 고객의 감춰진 마음을 읽어주는 SNS 상의 빅데이터 분석을 적극 활용해 보시길 추천합니다.
글 ㅣ 황현석 교수 ㅣ 한림대학교 경영학과
POSTECH 산업경영공학을 전공하여 학사를 마쳤으며, 동 대학원 산업경영공학과에서 경영정보시스템 전공으로 석박사학위를 취득하였다. 현재 한림대학교 경영학과에 교수로 재직 중이다. 주요 관심분야는 Expert System, 데이터 마이닝, 인터랙션 디자인, IoT를 활용한 융복합 연구 등이다. 인터랙션 디자인 관련 연구프로젝트를 수행하고 있다.
[ 관련 글 보기 ]
● 소셜 빅데이터 분석을 통해 신(新)소비 트렌드를 읽다


