최근 화두 중 하나인 로봇을 제조 현장에서 쉽게 만날 수 있는데요. 오늘은 제조업에서 새롭게 부각되고 있는 공장 내 생산 설비 자원들 중,’Cobots(Collaborative Service Robotics)’에 대해 상세히 알아보겠습니다. ‘Cobots’의 작동 원리 및 진화 과정, 그리고 적용 시스템까지 1편 ~ 3편으로 나누어 만나보시죠
전통적 로봇의 역할
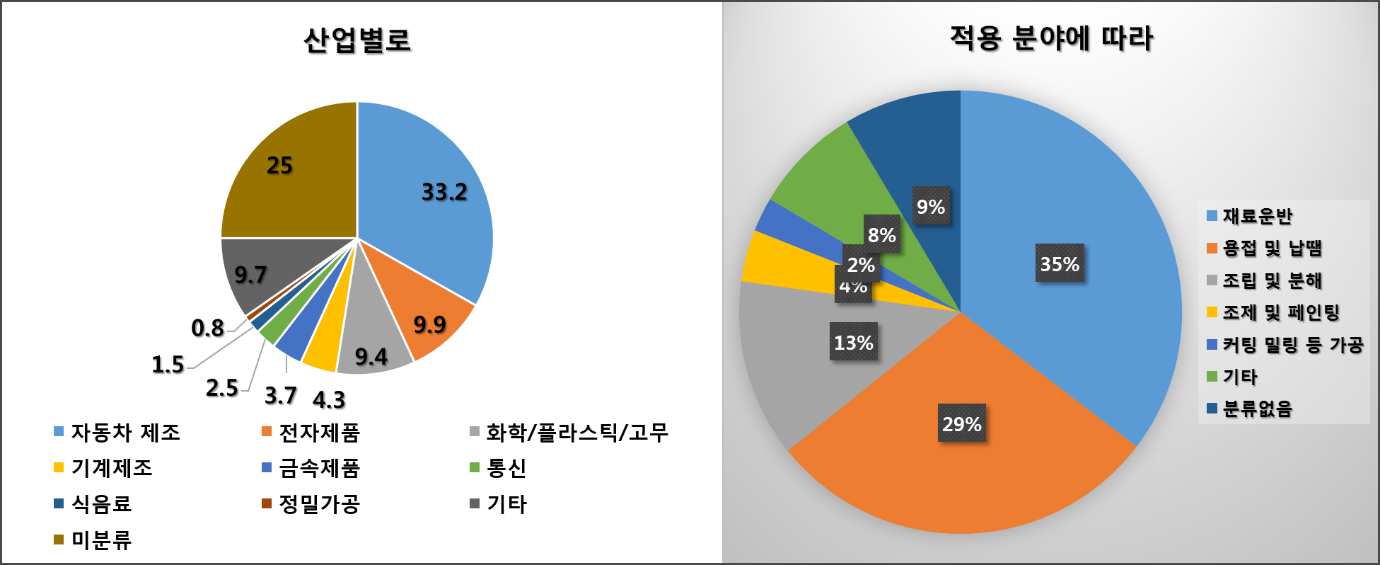
로봇은 위의 그림에서처럼 공장 현장에서 물류의 흐름을 좌우하는 설비 자원입니다. 기본적인 재료 운반의 역할뿐만 아니라, 사람이 하기 힘들거나 번거로운 일 혹은 위험한 작업에 로봇들이 투입되어 왔죠. 이렇듯 로봇은 공장 내 많은 작업들을 수행하지만, 한편으로는 안전 문제 등의 위험 요소와 다양한 제품을 생산할 때 유연성의 부족하다는 문제를 갖고 있었습니다.
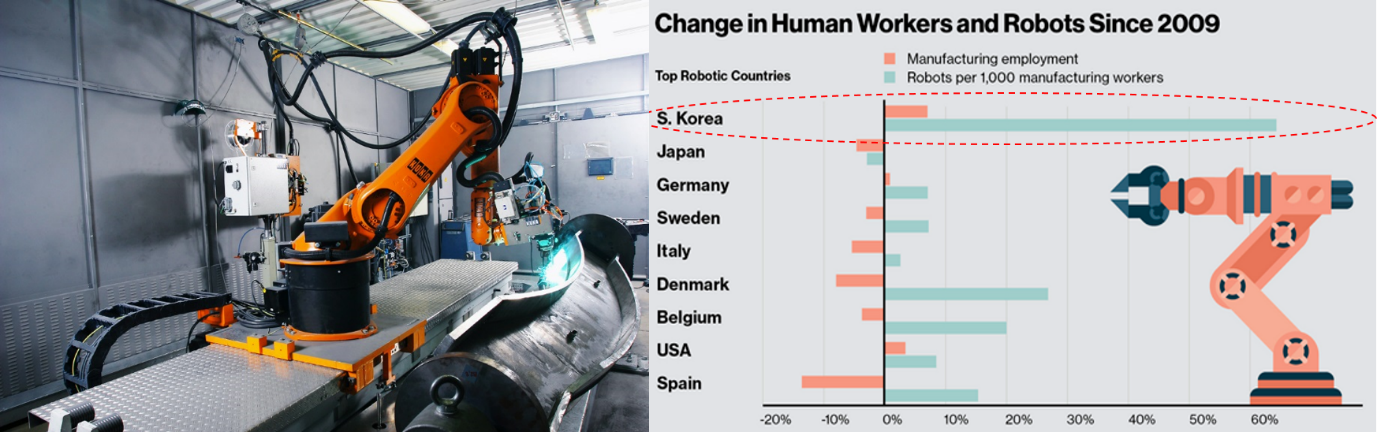
그런 이유로 위의 왼쪽 그림에서처럼 현재 공장 현장에서의 산업용 로봇은 다소 위협적인 외관을 지니고 작업자로부터 격리된 관리-제한된 환경 속에서 운영되고 있습니다. 또한 미리 약속된 로봇 프로그램의 루틴에 의해 주어진 역할을 반복적으로 수행하는 식으로 이용되고 있죠. 이러한 산업용 로봇은 현재 전 세계적으로 1,500만 대 정도로 다양한 산업 군에 보급되어 이용되고 있습니다.
위의 오른쪽 그래프에서 알 수 있듯이 자동차와 전자 산업 등이 발달한 우리나라의 경우, 2009년 이래 세계 최고의 ‘제조 업무 종사자 대 로봇 비율’을 확보하고 있는 것으로 알려져 있습니다. LG전자 역시 2006년부터 창원 2공장에 무인 운반차(Automated Guided Vehicle; AGV)와 포장 공정 로봇을 이용하는 생산 시스템을 구축했다고 하는데요. 포장 공정을 담당하는 로봇은 1대당 3명 이상의 작업자가 포장하는 것보다 빠르고 정확한 역할 수행이 가능하다고 합니다.
Artificial Muscled ‘Turing Machine’
인간을 모방하는 로봇

최근 들어 부쩍 인공 지능에 대한 영화들이 많이 등장하고 있습니다. 혹시 2015년 오스카 상을 수상한 ‘이미테이션 게임(Imitation Game)’이라는 영화를 보셨나요? 이 영화는 미래의 이야기가 아니라 오히려 과거로 돌아가 인공 지능의 기반이 되는 인간의 지능을 다룬 영화인데요. 영국의 천재 수학자이자 ‘튜링 머신’으로 널리 알려진 ‘앨런 튜링(Alan Turing, 1912~1954)’에 대한 이야기입니다.
앨런 튜링은 오늘날 IT가 있게 한 가장 주목할만한 인물 중 한 명이라고 생각하는데요. 애플의 로고인 ‘베어 문 사과 마크’가 튜링이 자살할 때 이용한 독이 든 사과에서 따왔다는 속설도 아주 그럴 듯하게 들리는 이유 중 하나이기도 합니다. 또한 작년에는 ‘유진’이라는 슈퍼 컴퓨터가 ‘튜링 테스트’라고 불리는 ‘이미테이션 게임’을 최초로 통과했다는 소식도 있었죠.
최근 등장한 시리(Siri)는 채팅 형태의 ‘인간-기계 상호 작용’을 통해 기계의 지적 능력이 얼마나 인간의 그것과 흡사한지 판별하는 것인데요. 이런 지적 능력에 실제적인 동작이 가능하게 해 주는 구동기(Actuator)가 더해진 것이 바로 ‘인공 근육 컴퓨터(Artificial Muscle Computer)’입니다.
사실 제가 앞부분에서 영화를 언급했던 이유는 이번 시간 다루고 있는 ‘Cobots’와 ‘앨런 튜링’에대한 연구들이 아주 밀접한 관계를 맺고 있기 때문입니다. 과거 정형화된 프로토콜과 약간의 ‘오류 처리 기능’을 가진 컨트롤러에 의해 반복적으로 제어되던 로봇은 오늘날 제조 환경에서 조금 더 능동적인 능력을 요구 받게 됩니다.
이제는 인간(작업자)과 보다 더 물리적인 상호 작용까지 포함시키는 이른바 ‘협업 로봇’에 대한 필요성이 증가하고 있는 상황인 것이죠. 단지 말상대가 아니라 실제 생산 활동에서 물리적으로 서로 조화롭게 작업하는 로봇이 그 목표입니다.
범용 튜링 기계와 인공 지능
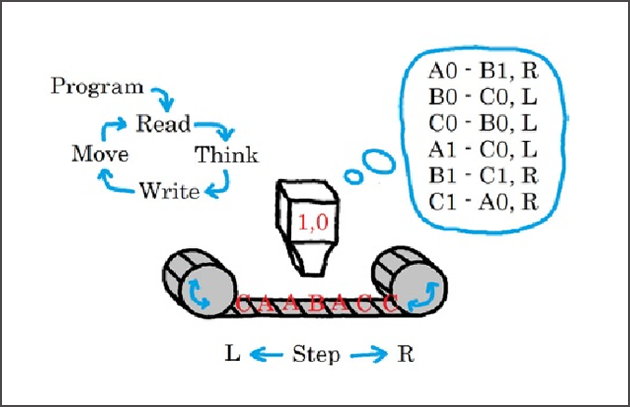
로봇이나 컴퓨터가 가지는 인공 지능의 개념은 위의 그림에서와 같은 ‘울프람(Wolfram)’의 기계 상태(0 또는 1, 정지 상태가 여기서는 배제됨) 및 세 가지 종류의 기호(입력값들)를 기반으로 한 간단한 ‘범용 튜링 머신’을 통해 설명이 가능합니다.
또한 튜링 머신 이후에 등장한 밀리 머신, 무어 머신과 같은 소위 ‘유한 상태 머신(Finite State Machine)’들과 워크플로우, 비즈니스 프로세스 모델들이 모두 이 튜링 머신의 범주에 포함된다는 사실이 그 범용성을 입증합니다.
이론적인 그의 기계는 입력 정보가 담긴 ‘무한의 테이프(오늘날의 메모리와 흡사)’와 오른쪽 왼쪽으로 움직이며 그 정보를 읽고 쓰는 ‘헤드’, 그림의 Think 부분을 담당하는 규칙 리스트(컴퓨팅의 내부 상태들)가 담긴 ‘논리 제어부’로 구성되어 있었습니다. 이런 구성에서 알 수 있듯이 그의 기발함은 바로 물리적 기계부와 가상의 컴퓨팅을 완벽하게 분리한 범용 기계를 고안해 냈다는 것에 있죠.
오늘날의 ‘Sensing – Computing/Control – Actuating’의 물리-가상 시스템의 기본 시퀀스는 모두 이것을 토대로 시작한 것이나 다름없습니다. 또한 인공 지능의 개념 또한 그의 연구를 통해 이미 60~70년 전에 시도되고 있었죠.
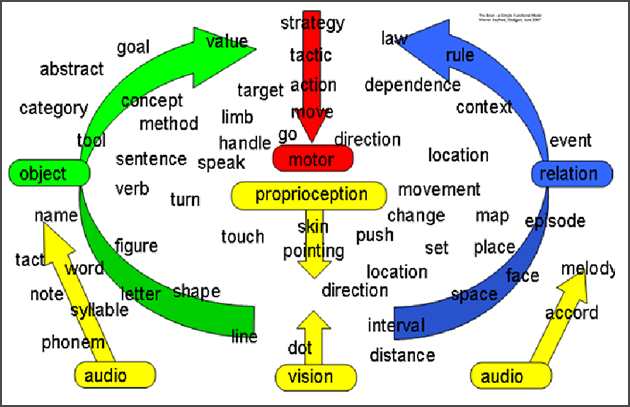
하지만 인간의 뇌가 어떻게 사고하는지에 대해서는 아직도 연구가 진행 중인데요. 타당성을 지닌 이론 중의 하나는 우리의 뇌는 관찰할 대상에 대해 끊임없는 예측(가설)을 토대로 실제 관찰과 예측의 차이를 기반해 새로운 규칙(가설)들을 만들어 나간다는 것입니다. 그리고 이것은 튜링의 인공 지능에 대한 견해와 거의 일치합니다.
이를 토대로 지능화란 결국 다양성에 대한 수용 및 프로토콜에 규정되지 않은 외부 대상의 입력에 대한 대처 능력을 키워 나가는 것이라고도 정의 내릴 수 있습니다.
오늘날의 인공 지능과 컴퓨터는 어떤 부분(정확한 규칙들이 존재하는)에 있어서는 오히려 인간을 능가하는 점도 있습니다. 기존의 로봇은 위의 그림에서처럼 미리 약속된 코드(A,B,C)나 다른 기계의 신호를 읽고 그 코드에 맞는 약속된 규칙을 찾아 저장된 어떤 출력을 통해 ‘반응’을 하는 식이었습니다.
즉 반응에 대한 똑똑함과 속도에 있어서 인간을 능가하는 것인데요. 하지만, 때로는 실수를 자주 범하는 인간도 쉽게 인지하고 판단할 수 있는 것들을 오히려 기계가 놓치는 현상도 종종 목격할 수 있습니다.
학습을 통해 ‘불확실성’을 ‘확실성’으로 바꿔 가기
그렇다면 오늘날 인간과 직접적인 상호 작용을 요구 받은 기계 입장에서 입력 도구 등의 매개체를 거치지 않고, ‘인간’이라는 외부 대상의 신호에 직접 응대하기 위해서는 무엇이 달라져야 할까요? 그리고 전체 제어 시스템의 관점에서 ‘인간’이나 기타 외부 환경으로부터 직접 전달되는 신호가 기계의 그것과의 가장 큰 차이점은 무엇일까요? 바로 기계 스스로 가늠하기 무척 까다로운 ‘표현 방식의 다양성’과 ‘자율성-혼돈’ 그로 인한 ‘(기계 입장에서의)입력값의 불확실성’입니다.
사람은 쉽게 인식하지만 기계에게는 마치 암호와도 같은 CAPTCHA(우)>
이것은 사실 기계뿐만 아니라 인간들끼리도 마찬가지일 듯 한데요. 의도와는 다른 모호한 표현으로 혼란을 겪곤 하기 때문이죠. 아무튼 위의 오른쪽 그림의 CAPTCHA 튜링 테스트처럼 기계 입장에서 무척 어려운 문제들이 그것의 한 예입니다.
튜링의 영특함은 여기서 발휘되는데요. 영화에서 독일군의 암호를 정보(사람이 인지할 수 있는 원해 입력값)로 해독하는 과정에서 위의 왼쪽 그림과 같은 1,590억의 10억 배 경우의 수의 ‘기계 세팅’과 맞닥뜨려야만 했습니다. 그 당시의 기술 수준으로는 이 경우의 수를 전부 다 어떤 서치 알고리즘으로 시도해 보기는 불가능했죠.
그래서, 그는 내재된 규칙을 더 빨리 역으로 추론하는 방법을 고민하게 됩니다. 물론 이미 획득한 이니그마 기계와 그 기계에서 발견되는 일종의 결함(입력값이 절대 같은 문자로 맵핑되지 않음), 그리고 ‘Heil Hitler’와 같은 반복되는 메시지를 통한 힌트들이 있었죠.
그리고 이러한 힌트들과 통계적 방법을 이용해 암호 출력값들과 진짜 메시지와의 관계를 추론하기에 이릅니다. 이렇게 되면 문제는 간단해지는데요. 앞서 소개했던 튜링 기계의 원리를 그대로 적용할 수 있게 되는 것이죠.
오늘날 ‘머신러닝’이 추구하는 추론을 통한 입력값과 규칙(기계가 감당할 수 있는 형태)의 단순화/부호화와 거의 일치합니다. 어찌 보면 인공지능의 원리를 거의 최초로 적용한 기계 그리고 가시적인 성과를 거둔(1000만 명 이상의 목숨을 살렸다니 이보다 가시적일 수는 없음) 사례인 것만은 분명합니다.
아마도 ‘로봇-인간 상호작용’ 환경에서 로봇이 인지해야만 하는 외부 입력값의 경우의 수는 암호문에 사용된 알파벳 조합이 가지는 수 이상일 듯 합니다. 아니 딱히 정해진 수가 없는 무작위(Random)에 가깝다고 보는 것이 맞겠군요. 그와 더불어 거기에 맞춰 고려해야 하는 출력값의 수도 당연히 더 많아지겠죠.
그 결과는 앞선 그림의 ‘Think’ 단계에서 조합을 통해 고려해야 할 내부 상태(규칙: 위의 그림에서는 6개의 조합에 불과하지만)의 수가 아마 1,590억의 10억 배의 이상이거나 말 그대로 가늠하기 어려운 정도일 것입니다.
그래서 경우의 수를 일일이 처리하는 것이 아니라 미리 약속/분류된 상황들과 그 상황에서 발생 가능한 입력값들의 변수 정보를 필터링을 통해 기계가 인식 가능한 입력으로 처리하게 된 것입니다. 또한 일반적인 컴퓨터와 다른 점은 로봇의 경우 ‘제한된 행동’이란 출력값을 통해 이 방대한 경우의 수가 어느 정도 추려질 수도 있다는 것이죠.
60년 전에 나왔던 튜링 머신의 기본 원리가 그대로 제어에 적용되면서도, 약속된 입력이 아닌 ‘센서’ 및 ‘머신비전’을 이용한 다양한 입력값들을 수용합니다. 그리고 약속된 규칙이 아닌 ‘머신러닝’을 통해 다양한 입력값들과 상황에 맞게 능동적으로 대처 및 예측하고, ‘생체공학적•운동학적 움직임’이란 유연한 출력으로 나타낼 수 있게 되었습니다.
독일군의 암호를 해독하기 위해 고민했던 튜링의 모습이 오늘날 인간이라는 불확실성투성이의 대상이 전달하는 암호와도 같은 메시지를 흡사한 방식으로 풀어가고 있는 Cobots의 모습과 묘하게 겹쳐져 있습니다.
다음 편에서는 Cobots이 어떻게 진화해 왔고, 어떤 시스템과 플랫폼이 적용되는지 알아보도록 하겠습니다.
글 ㅣ 이승엽 연구원


