딥러닝으로 인한 인공지능의 발전은 인지, 학습, 추론, 행동과 같은 인간 지능 영역의 전 과정에 걸쳐 혁신적인 진화를 만들어 내고 있습니다. 특히 시각, 청각과 같은 감각기관에 해당하는 인지 지능은 2012년을 기점으로 본격적으로 발전하였으며, 시각 인지 분야의 지능은 인간 수준을 초월하는 수준으로 구현되고 있습니다.

이미지•영상의 인식과 이해
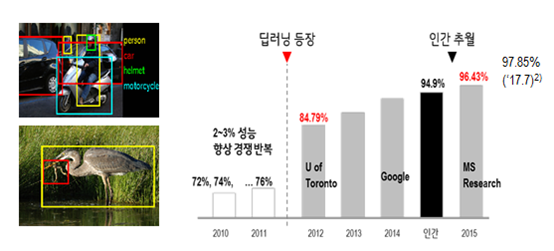
앞서 언급했듯이 인간의 시각 지능에 해당하는 이미지 인식 분야에는 이미 인간 수준을 초월하는 인공지능이 구현되고 있습니다. 2012년 유튜브 영상 속의 고양이를 스스로 구분해 낸 구글의 인공지능1과 이미지 속의 사물 인식 정확도를 혁신적으로 향상시킨 토론토 대학의 인공지능2이 구현 된 지 약 3년 만에 인간의 수준을 뛰어넘은 것입니다.
매년 다양한 연구기관이 참여해 이미지 내 사물 인식의 정확도를 경쟁하는 ImageNet3 경진대회에서는 2015년 마이크로소프트가 96.43%의 정확도를 달성하며 인간의 인식률(94.90%)을 초월하였습니다. (‘17년 정확도: 97.85%4)
인공지능은 단순히 이미지 속의 사물의 종류를 인식하는 것을 뛰어넘어, 영상•이미지 속의 상황을 이해하기 시작했습니다. 사람 얼굴의 사진을 보면 남성, 여성 등과 같은 외형적 특성을 인식하는 것은 물론이고 눈, 코, 입 모양의 상관 관계를 분석해 표정을 인지하거나 감정을 추측5하는데요. 게다가 2015년 구글이 발표한 논문에서는 이미지 속 상황을 정확히 이해해 인간의 언어로 표현6하기도 합니다.

시각 지능을 통해 이미지를 인식하고 이해하게 된 인공지능은 이미지 속 상황에 대한 인간의 물음에 대해 정확히 답을 하기도 합니다.7 아래 <그림>과 같이 인공지능은 인간의 질문을 정확히 이해하고 답을 해내는데요. ‘Attention’이라고 불리는 방법을 통해 인공지능은 이미지 내 다양한 사물 중 질문의 답에 해당하는 부분에 스스로 집중8하며 답을 찾아냅니다.

이처럼 진화하고 있는 시각 지능을 기반으로 한 인공지능은 연구 단계를 넘어서 실제 생활에 적용되며 다양한 혁신을 만들어 갈 것으로 전망됩니다. Microsoft는 고도화된 시각 지능을 활용한 ‘Seeing AI’라는 시각 장애인용 인공지능을 발표했습니다. 앞을 볼 수 없는 시각 장애인의 시각 지능을 인공지능이 대신하는 것입니다.
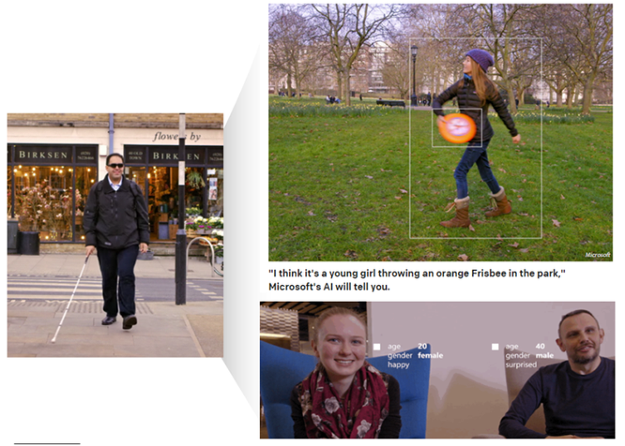
시각 장애인에게 눈앞의 상황을 인간의 언어로 설명해 주거나, 앞에 앉아 있는 상대방의 성별, 나이, 표정 등의 정보를 제공해 줍니다. 즉 시각 장애를 갖는 사람들의 시각 인지 기능을 인공지능이 대신 제공해 장애인들의 일상생활을 혁신적으로 변화시킬 수 있을 것으로 전망됩니다.
이미지•영상의 합성과 생성
인간 수준 이상의 시각 지능을 갖게 된 인공지능은 이제 시각 정보를 자유롭게 변형하거나 전혀 새로운 이미지를 생성해 내기도 합니다. 인간의 인식 수준을 초월한 시각 지능에 기반해 만들어지고 있는 이러한 가상의 이미지는 인간이 쉽게 구분해 낼 수 없을 정도의 높은 완성도를 갖고 있습니다. UC버클리대 연구팀은 딥러닝을 활용해 이미지를 다양하게 변형하는 논문9을 발표하였습니다.
아래<그림>의 왼쪽과 같이 풍경 사진의 계절적 특성을 이해한 인공지능은 하나의 풍경 사진을 여름, 겨울 사진으로 변경하거나 동물•식물의 특성을 정확히 이해해 동물의 외형을 자유롭게 변형하기도 합니다. 또한 모네, 고흐 등 특정 유명 화가의 화풍을 학습해 일반 풍경 사진을 특정 화가의 화풍이 접목된 그림으로 변환10하기도 합니다.
이는 수많은 학습 과정을 통해 각 이미지가 갖는 특성을 정확히 이해하고, 지식화해 새로운 이미지의 생성 과정에 적용해 내는 것입니다. 인공지능이 생성했다는 사전 정보가 없다면, 인위적으로 생성된 가상의 이미지라는 것을 인간의 시각 지능으로 구분하기 어려울 정도의 높은 완성도로 구현됩니다.

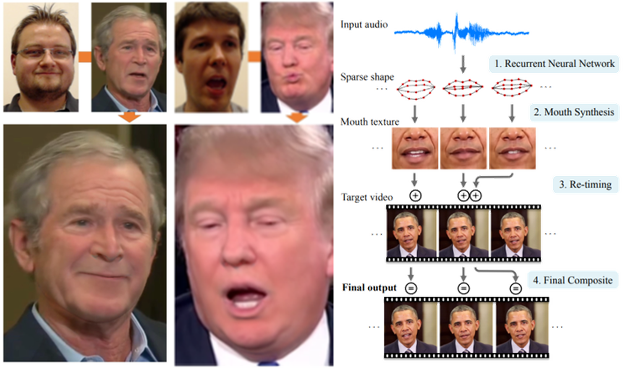
단순히 정지된 이미지를 합성하는데 그치지 않고 실시간으로 동영상을 합성하기도 합니다. 스탠퍼드대의 연구팀은 유명인의 영상에 전혀 다른 사람의 표정을 합성하는데요. 실시간으로 바뀌는 표정이 그대로 유명인의 얼굴에 반영12됩니다.
워싱턴대에서 발표한 ‘Synthesizing Obama’라는 논문13에서는 오바마 대통령의 목소리만을 가지고 입 모양을 생성해 오바마 대통령의 전혀 다른 연설 영상에 합성했습니다. 단순히 정지된 이미지 정보를 합성하는 수준을 넘어 실시간의 영상 변형, 합성까지 가능한 것입니다.
더 나아가 인공지능은 이제 세상에 존재하지 않는 전혀 새로운 사물을 생성해 내기도 합니다. GAN(Generative Adversarial Networks)14라 불리는 이 방법은 새로운 사물을 생성하는 인공지능과 생성된 사물이 진짜인지 가짜인지를 판별하는 두 인공지능이 서로 경쟁하며 진짜와 같은 가상의 이미지를 생성해 냅니다.
구글의 Ian Goodfellow에 의해 제안된 GAN은 2016년 이후 매우 빠르게 성능이 향상되고 있으며 2017년 4월 발표된 논문15에 나타난 이미지들은 가상으로 생성된 이미지라는 것을 구분할 수 없을 정도로 높은 완성도를 보여주고 있습니다.

2016년 발표된 StackGAN16은 인간의 언어로 기술된 텍스트를 이해해 특정 사물을 생성하기도 합니다. 아래 <그림>과 같이 특정한 모양, 색깔을 갖는 꽃 사진을 생성해 내거나 새를 만들어 내기도 합니다. 물론, 이러한 사물은 GAN과 마찬가지로 기존 세상에 존재하지 않는 전혀 새로운 가상의 형상들이며 생성된 결과만으로는 인간의 시각 지능으로 판별이 매우 어렵습니다.

이런 시각 인지 지능의 산업적 영향력은 매우 클 것으로 전망됩니다. 단기간에 직접적으로는 엔터테인먼트, VR•AR과 같은 영상 콘텐츠와 관련된 주요 산업에 핵심 역량으로 작용할 가능성이 큽니다. 인공지능이 애니메이션의 영상뿐만 아닌 음성까지도 스스로 생성해 내는 것이 가능할 것이며, 유명 배우의 외형을 학습한 인공지능은 다양한 모습으로 배우의 영상을 변형하거나 새롭게 생성하는 것도 가능할 것입니다.
단순한 콘텐츠 산업을 넘어 인간의 시각과 관련된 거의 모든 산업에 직•간접적으로 영향을 미칠 수도 있습니다. 앞으로 시각인지 지능은 교육, 쇼핑, 교통 등 모든 영역에서 산업의 핵심 요소 기술로 작용해 기존 산업의 경쟁 방식을 혁신시킬 것으로 예상됩니다.
글 | 이승훈 책임연구원(shlee@lgeri.com) | LG경제연구원
- Q. Le, et al., Building High-level Features Using Large Scale Unsupervised Learning, ICML 2012 [본문으로]
- A. Krizhevsky, et al., ImageNet Classification with Deep Convolutional Neural Networks, NIPS 2012 [본문으로]
- 스탠퍼드대에서 주관하는 영상인식 분야 경진대회… 1,000가지 종류의 사물로 구성된 100만 장의 이미지가 주어지며 각 이미지 속에 존재하는 사물의 종류를 알아 맞히는 경쟁 [본문으로]
- http://image-net.org/challenges/LSVRC/2017/ [본문으로]
- Microsoft Emotion API [본문으로]
- O. Vinyals, et al., Show and Tell: A Neural Image Caption Generator, CVPR 2015 [본문으로]
- Yuke Zhu, et al. Visual7W: Grounded Question Answering in Image, CVPR 2016(우) [본문으로]
- Z Yang, et al, Stacked Attention Networks for Image Question Answering , CVPR 2016 [본문으로]
- J. Zhu, et al. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks ICCV 2017 [본문으로]
- L. Gatys, et al., Image Style Transfer Using Convolutional Neural Networks, CVPR 2016 [본문으로]
- (좌) J. Zhu, et al., Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks ICCV 2017 (우) L. Gatys, et al., Image Style Transfer Using Convolutional Neural Networks, CVPR 2016 [본문으로]
- J. Thies, et al. Face2Face: Real-time Face Capture and Reenactment of RGB Videos, SIGGRAPH 2016 [본문으로]
- S. Suwajanakorn, et al., Synthesizing Obama: Learning Lip Sync from Audio, SIGGRAPH 2017 [본문으로]
- Ian Goodfellow, et al., Generative Adversarial Networks, 2012 [본문으로]
- D. Berhelot, et al., BEGAN: Boundary Equilibrium Generative Adversarial Networks, 2017 [본문으로]
- H. Zhang, et al., StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks , 2016 [본문으로]


