최근 들어 빅데이터가 사회의 큰 화두도 떠오르고 있는 가운데 빅데이터 분석에 있어서 가장 중요한 분석 도구로 알려져 있는 데이터마이닝(Data mining)에 대한 수요가 급증하고 있습니다. 데이터마이닝은 과거부터 다양하게 정의되고 있는데, 그 정의들을 살펴보면 데이터마이닝은 대용량 데이터에 대한 탐색적 분석 도구라는 관점을 공통적으로 언급하고 있습니다.
데이터마이닝에서 ‘Mining’은 ‘채굴하다’라는 사전적 의미를 가지고 있습니다. 즉, 거대한 데이터 더미 속에서 가치 있는 어떠한 것을 채굴하는 것이지요. 따라서 데이터마이닝은 방대한 양의 데이터 속에서 쉽게 드러나지 않는 유용한 정보를 찾아내는 과정이라고 할 수 있습니다.

데이터마이닝이 출현하게 된 배경은 정보통신기술(ICT)의 발전으로 인한 데이터 홍수 시대의 출현이라고 할 수 있습니다. 80년대 이후 급속한 성장을 이룬 ICT 발전에 기반을 두어 기업들은 방대한 양의 데이터를 저장하고 관리하기 위한 데이터베이스 구축에 많은 투자와 노력을 들여왔습니다.
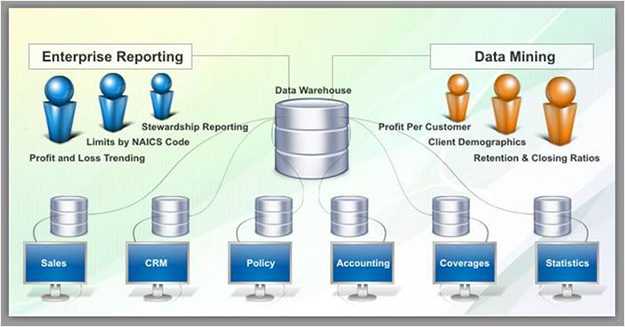
기업들은 이러한 대용량 데이터베이스의 활용도를 높이기 위한 수단으로 수집된 대용량의 데이터를 정제되고 통합된 형태로 저장할 수 있는 데이터 웨어하우스라는 데이터 저장창고의 구축에 관심을 가지게 되었습니다.
또한, 기업 간 경쟁이 점점 치열해지는 시장 환경에서 고객들의 요구에 대한 적절하고 빠른 대응이 기업 경쟁력의 측정지표가 되고, 경쟁우위를 확보하기 위한 합리적이고 신속한 의사결정이 중요한 이슈가 되었습니다. 이러한 환경 속에서 각 기업들은 최적의 의사결정을 뒷받침해 줄 수 있는 의미 있는 새로운 정보의 탐색에 집중하게 되었습니다.
이런 과정에서 구축된 데이터 웨어하우스로부터 이미 알려져 있는 정보뿐만 아니라 기존에 알려지지 않았던 정보까지 추출할 수 있는 효율적인 방법에 기업들은 집중하게 되었고, 이를 해결해 줄 수 있는 데이터마이닝 방법론이 자연스럽게 시장에서 각광을 받기 시작한 것이라고 할 수 있습니다.
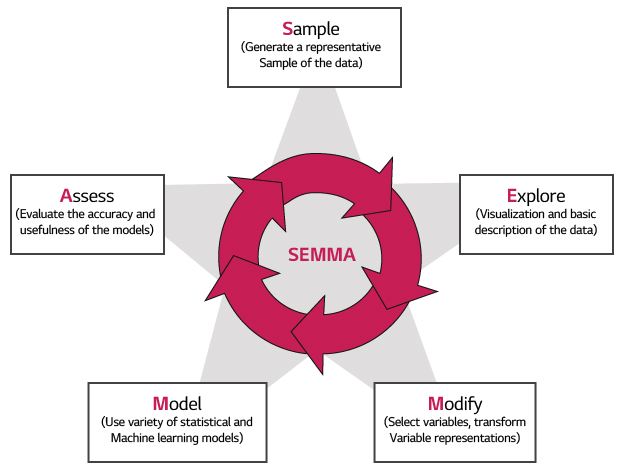
대용량 데이터베이스에서 유용한 정보를 추출하고, 추출된 정보로부터 다시 숨어있는 규칙이나 패턴 등 새로운 정보를 도출하는 데이터마이닝 과정은 일반적으로 다음과 같이 SEMMA 프로세스라는 5단계의 분석 과정을 거치게 됩니다.
[SEMMA 프로세스]
- Sampling: 분석에 사용할 데이터 선정 및 추출
- Exploration: 추출된 데이터의 전반적인 형태를 조사하고 기초통계량 산출을 통하여 데이터셋에 대한 insight를 제공
- Modification: 데이터마이닝을 위한 데이터 변환 (중복 데이터 제거, 데이터 정규화, 차원 축소 등)
- Modeling: 주어진 문제에 적합한 분석 방법 결정 및 적용 (연관성 분석, 군집 분석, 분류 분석 등)
- Assessment: 분석 모델의 결과를 평가하고 시각화 도구 등을 이용하여 도출된 결과를 의사결정에 효율적으로 적용
이 다섯 단계 중 가장 핵심이 되는 단계는 문제 해결에 적합한 데이터마이닝 방법론을 적용하여 분석 결과를 이끌어내는 Modeling 단계가 아닐까 생각합니다. 그렇다면 구체적인 데이터마이닝 방법론에는 어떠한 것들이 있으며 어떠한 알고리즘을 가지고 데이터들을 분석할까요?
실제로 가장 널리 이용되는 데이터마이닝 기법들은 대표적으로 연관성 분석, 군집 분석, 의사결정 나무 이렇게 세 가지 방법론들을 꼽을 수 있습니다. 그럼 이 세가지 방법론에 대해서 간단히 알아보겠습니다.
연관성 분석(Association Analysis)
장바구니 분석(Market Basket Analysis) 혹은 친화성 분석(Affinity Analysis)이라고도 잘 알려져 있는 방법론으로 맥주와 기저귀의 연관성을 밝혀낸 분석 방법으로 널리 알려져 있습니다.
연관성 분석을 통해 대형 마트의 구매 데이터로부터 아기용 기저귀와 맥주가 함께 팔리는 사실을 알아내었고, 이는 주말에 아기용 기저귀를 사러 온 아기 아빠들이 맥주를 같이 사기 때문이라는 것을 알게 되었습니다. 실제로 월마트는 이 같은 분석 결과를 토대로 아기용 기저귀와 맥주를 패키지로 묶어 판매하여 기존보다 약 3배 증가된 매출을 달성할 수 있었다고 합니다.

연관성 분석은 거래나 사건을 포함하는 일련의 데이터로부터 연관 규칙을 발견하고 둘 이상의 품목들 간 상호 연관성을 밝히는 것입니다. 즉, “어떤 항목이 어떤 항목을 동반하는가”에 대한 연구입니다. 거래 데이터베이스로부터 구매 항목들 사이의 연관성에 대한 규칙을 추론하여 “만약 X가 구매되었다면, Y 또한 구매 될 것이다”라는 간단하고 명확한 규칙 생성하는 것입니다.
위 규칙을 연관성 규칙이라고 하며, 데이터로부터 생성된 수많은 연관성 규칙 중 지지도(support), 신뢰도(confidence), 그리고 향상도(lift)라는 세 가지 측정지표를 토대로 규칙의 중요도를 산출하게 됩니다. 즉, 사용자는 좋은 측정지표들의 값을 가지는 규칙들을 의사결정을 위해 사용하게 되는 것입니다.
연관성 분석은 실제로 다양한 분야에서 활용될 수 있습니다. 앞서 언급했던 것처럼 구매 데이터 분석에 적용되어 대형 마트의 마케팅 전략에 사용될 수 있으며, 신용카드 구매 기록을 통하여 해당 고객이 다음에 어떤 상품이나 서비스를 이용할 가능성이 높은지에 대한 예측을 할 수 있습니다.
아마존 같은 전자상거래 기업에서는 이러한 분석을 토대로 온라인 추천 시스템을 구축하여 접속 고객들에게 구매할 가능성이 있는 항목들을 자동으로 추천해주고 있습니다. 또한, 병원에서 환자의 의무 기록으로부터 여러 치료가 같이 이루어진 경우 합병증 발생의 징후를 알 수 있게 해줄 수도 있습니다.
군집 분석(Clustering Analysis)
군집 분석은 여러 집단의 데이터들이 섞여 있고 각 데이터의 소속 집단을 모르는 경우 유사한 속성을 갖는 데이터의 군집을 찾는 분석 방법입니다. 주어진 개체 중에서 유사한 것들을 몇몇의 집단으로 그룹화하여, 각 집단의 성격을 파악함으로써 데이터 전체의 구조에 대한 이해를 돕고자 하는 탐색적 데이터마이닝 방법론입니다. 군집 분석의 목표는 주어진 데이터를 통해 군집을 잘 구분하는 것입니다.
여기서 잘 구분한다는 것의 의미는 동일한 군집의 개체들은 유사한 성격을 갖도록, 서로 다른 군집에 속한 개체들 사이에는 상대적으로 서로 다른 성격을 갖도록 구분한다는 것입니다. 그렇다면 개체들 간의 유사성은 어떻게 측정할 수 있을까요?

군집 분석에서 유사성이란 일반적으로 개체들 간의 거리를 기준으로 측정하게 됩니다. 만약 키를 기준으로 군집을 구분한다고 할 때 A라는 개체의 키가 175cm이고 B라는 개체의 키가 180cm라면, A와 B의 유사성은 5cm라고 정의됩니다. 따라서 군집 분석을 위한 데이터의 속성은 키, 몸무게 등과 같은 연속형 데이터가 적절하며 성별, 나라, 색깔 등과 같은 범주형 데이터는 적절하지 않습니다.
군집 분석은 마케팅 분야에서 활발하게 사용되고 있습니다. 전체 시장을 비슷한 구조를 가지는 세부 시장으로 구분 짓기 위한 시장 구조 분석이나 수요층 별로 시장을 분할화 또는 단편화하여 각 층에 대해 집중적으로 마케팅 전략을 펴는 시장세분화 전략에 유용하게 적용되고 있습니다. 또한 최근에는 금융 분야에서 균형 포트폴리오 구성이나 산업 분석 시 사용되고 있습니다.
의사결정 나무(Decision Tree)
의사결정 나무는 우리가 관심을 가지는 분류 문제를 해결하기 위해 매우 강력하고 유용한 데이터마이닝 알고리즘입니다. 이 알고리즘은 분류를 하기 위한 목표 변수에 영향을 줄 수 있는 입력 변수들을 이용해 최적의 분류를 위한 의사결정 규칙을 생성하게 되는데, 의사결정 규칙을 트리 구조로 나타내주기 때문에 의사결정 나무라고 불리고 있습니다.
예를 들어, 매출액과 차입금이라는 입력 변수 자료를 이용하여 어떤 기업의 부도 혹은 비부도라는 목표 변수를 분류하는 문제에 의사결정 나무를 적용시킨다면 “매출액이 100 이하고 차입금이 150 이상이면 부도로 분류, 아니면 비부도로 분류”와 같은 의사결정 규칙을 생성해 줄 수 있습니다. 여기서 “매출액 100 이하”, “차입금 150 이상”과 같은 하나 하나의 규칙을 분리 규칙이라고 합니다.
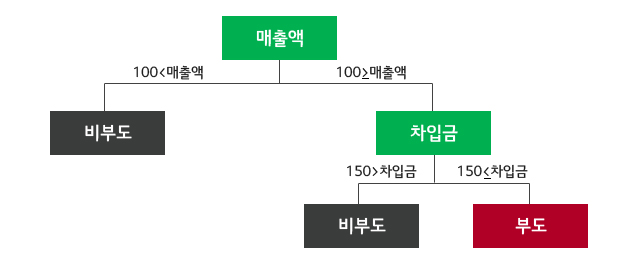
의사결정 나무 방법론은 앞서 예를 들었던 부도 예측이나 신용평가 분야에서 널리 사용되고 있습니다. 고객들의 성향을 파악하여 우리 기업의 충성도가 높은 고객, 혹은 더 이상 우리의 제품이나 서비스를 이용하지 않는 고객들의 분류를 통해 고객 유지율을 향상시키고, 이탈한 고객들을 다시 우리의 고객으로 되돌릴 수 있는 방안을 모색함으로써 고객과의 지속적인 관계를 유지해 나가는데 이용하기도 합니다.

지금까지 대표적인 데이터마이닝 방법론들의 분석 방법과 적용 사례들을 간단하게 살펴보았습니다. 빅데이터 시대에 필수적인 분석 도구로서 인정받고 있는 데이터마이닝은 대용량의 데이터로부터 유용한 새로운 정보들을 제공해줄 수 있습니다. 하지만 이렇게 도출된 새로운 정보들은 불확실성을 가지고 있습니다. 지금까지 수집된 방대한 데이터에 의해 분석된 결과이기 때문에 정답이 아닐 가능성을 가지고 있다는 것이지요.
따라서 추후 지속적인 검증과 피드백이 매우 중요합니다. 결국엔 데이터마이닝 분석, 검증, 피드백이라는 선순환 구조를 통해 지금까지 알려지지 않았던 많은 정보들이 생성될 것이며, 이를 바탕으로 새로운 시장이 개척되고 새로운 산업들이 시장에 등장하게 될 것입니다.
글 | 안재준 교수 | 연세대학교 정보통계학과


