지난 시간에는 더 나은 제조 시스템을 위해 분산되고 분리된 데이터 베이스들과 개별 마스터 데이터들의 통합을 위한 ‘MDM(Master Data Management)’의 역할을 함께 살펴보았는데요. 이어서 오늘 이 시간에는 빅데이터 시대에서의 MDM의 한계, 빅데이터와 MDM을 이어주는 새로운 형태의 MDM 방법, 실제 적용 사례 등을 알아보겠습니다.
● 빅데이터 시대의 기업 정보 관리(1편) : http://blog.lgcns.com/934

빅데이터 시대, MDM의 한계 그리고 우리가 추구해야 할 상호 보완성!
지난 시간에 우리는 일반적인 MDM에서 정형화된 마스터 데이터들의 정합성과 일원화된 관리를 위해서는 데이터의 ‘품질’, 데이터들 사이의 ‘관계’가 가장 중요한 요소라는 것을 확인했습니다.
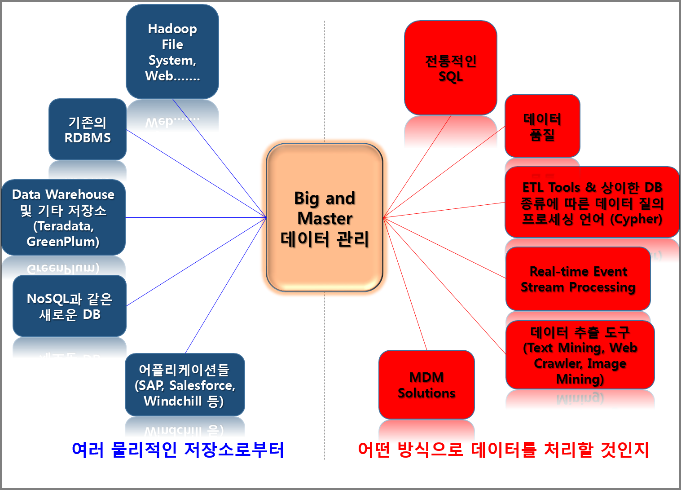
위의 그림과 같이 최근 기업이 관리해야 하는 데이터들은 기존의 관계형 데이터베이스 관리시스템(RDBMS)에 저장된 정형화•반정형화된 데이터뿐만이 아닙니다. 기업 내•외부의 다양한 소스(SNS, 기계들)를 통해 다양한 형태의 비정형화된 데이터들이 불규칙적인 간격으로 유입되기 때문이죠.
그 결과 기존의 RDBMS, Data Warehouse를 기반으로 한 SQL, ETL1등의 방법으로 처리했던 데이터 관리가 더욱 다양한 방법을 통해 복합적으로 수행되어야 한다는 필요성이 대두되고 있습니다.
즉 빅데이터에 대응하는 기존 시스템이 가진 한계를 보완하기 위해 새로운 데이터 질의 언어가 추가되고 있는 상황인데요. 그것은 바로 HDFS(Hadoop Data File System), NoSQL과 같은 다른 방식의 DB 시스템, 그리고 거기에 따른 처리 방식도 Hadoop을 기반으로 하는 ETL 배치 처리 및 In-Memory DB를 바탕으로 한 실시간 스트림 처리, NoSQL에서 사용되는 Cypher 등입니다.
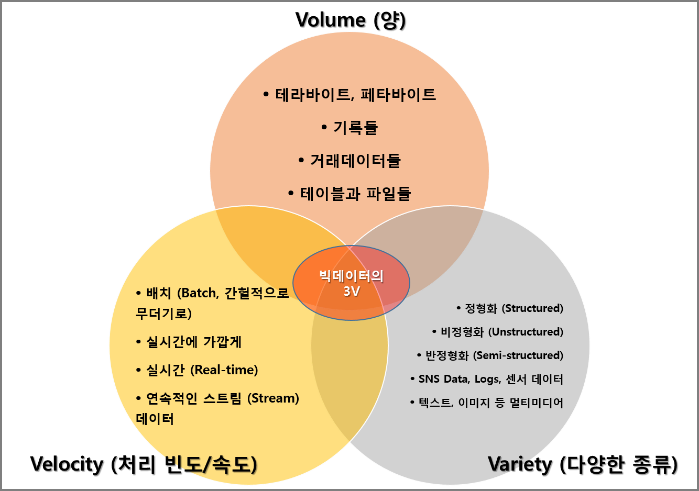
그래서 기존의 Data Warehouse에 축적된 데이터들에 대한 품질뿐만 아니라 새롭게 유입되는 여러 소스의 데이터들에 대한 품질을 높여 기존의 데이터들과 연계하고자 노력 중입니다. 서로에게 유의미한 파급 효과를 기대하고 있는 것이죠.
예를 들어 어떤 제품이 있다고 가정해 봅시다. 이때 제품의 미래 수요와 관련하여 SNS 및 소비자들의 제품 평가 등의 비정형 데이터들을 저장된 기존의 합병 거래 데이터들(판매량, POS 데이터, VMI 데이터 등)과 연계하여 새로운 수요 데이터를 생성할 수도 있는 것이죠.
이렇듯 MDM에서도 빅데이터를 통합하여 그 활용 방안을 모색 중이며, 그것을 가능하게 하는 여러 기술들과 새로운 솔루션을 도입하고 있습니다.
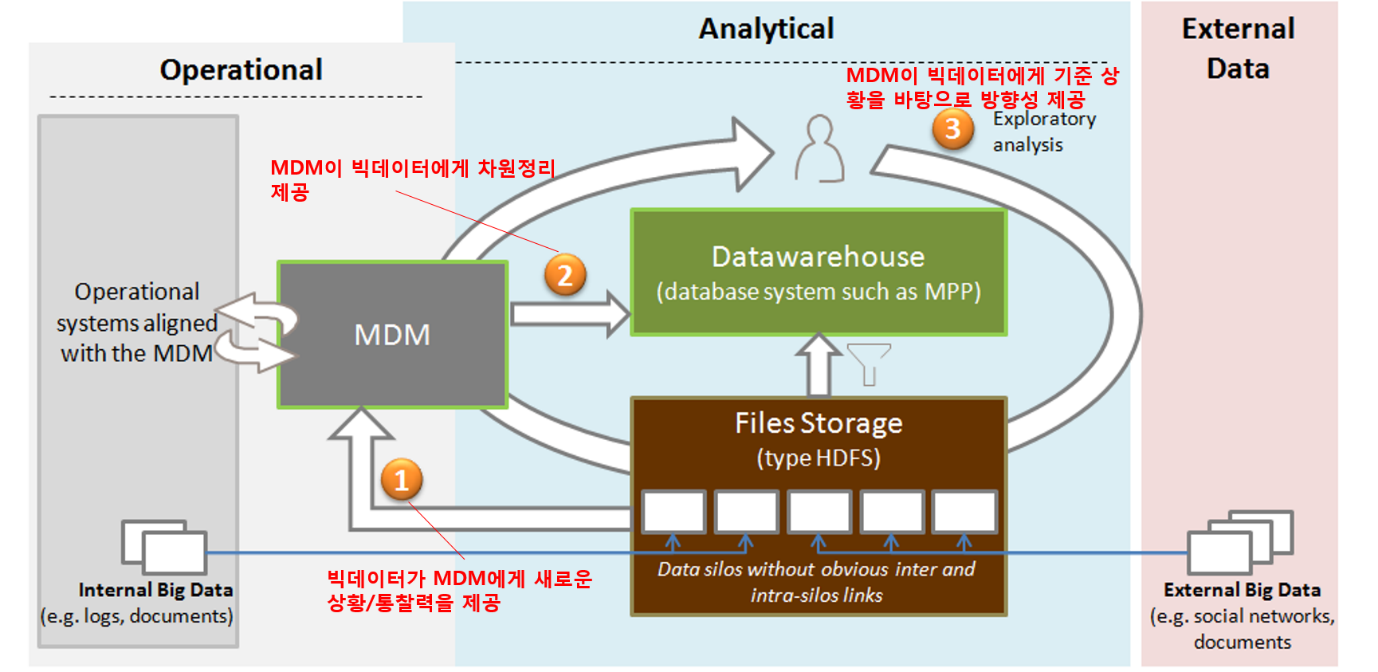
즉 위의 그림에서와 같이 MDM은 정의된 데이터 개체들의 구조와 관계를 바탕으로 빅데이터에게 일종의 처리 기준이 될 수 있는 상황(Context)을 제시합니다. 또한 데이터들의 복잡한 차원을 정리해서 일종의 빅데이터들의 방향성을 제공해 줄 수도 있습니다. 반대로 수집된 빅데이터는 분석을 통해, 기존의 MDM에서는 미처 파악하지 못한 새로운 상황과 데이터들에 대한 새로운 통찰을 제시하기도 합니다.
최근 보고에 의하면, 현재 미국 내 기업 약 20% 정도는 기존의 RDBMS과 더불어 앞서 소개한 NoSQL과 같이 보다 빅데이터의 세가지 기본 특성(3V)과 그것들을 처리하기에 최적화된 데이터 베이스를 사용하고 있다고 합니다.2 그리고 이 비율은 점점 늘어날 추세라고 전망하고 있는데요. API 등을 이용한 자유로운 데이터 베이스들 사이의 상호 작용 또한 가능해지고 있습니다.
과거 데이터를 사용하는 애플리케이션에 따라 분산되었던 데이터 베이스는 이제 데이터의 사용 빈도나 형태에 따라 RDBMS, Data Mart, Data Warehouse, HDFS, 그리고 NoSQL 등의 다양한 데이터 저장소로 분산되어 저장•사용되고 있습니다. 이를 통해 보다 원활한 데이터 공급망의 관리가 이루어지고 있다고 볼 수 있는 것이죠.
빅데이터(Big Date)와 MDM을 이어 주는 새로운 ‘도구’가 등장하다!
최근 포레스터 리서치(Forrester Research)와 가트너(Gartner) 등에서 주목하고 있는 새로운 형태의 MDM 방법이 있는데요. 바로 ‘데이터 그래프’를 이용한 방법입니다.
이는 앞서 설명한 기존의 MDM 방법보다 더욱 직관적이고, 분석적이며, 지능적으로 마스터 데이터와 빅데이터를 동시에 관리하는 방법인데요. 기존의 RDBMS의 출발 또한 아시다시피 데이터들의 ‘관계’에 초점을 맞추어 관계형 자료 구조를 만드는 것에서부터 시작되었습니다. 그러나 문제는 그 ‘관계’라는 것이 너무 2차원적이어서 그 한계가 발생하게 되는 것입니다.
앞서 언급했지만 요즘의 데이터들은 정형화된 2차원적 ‘행렬 관계’에서 벗어나 보다 다차원적인 관계를 맺어 가고 있습니다.

또한 기업들이 추구하는 IT 전략이 점차 복합적으로 플랫폼화 되어 가고 있는데요. 이는 데이터 자체뿐만 아니라 수많은 애플리케이션들과 데이터 베이스들, 그리고 파트너 공급자, 소비자들이 플랫폼 안에서 다차원의 관계를 형성하고 있는 것을 의미합니다.
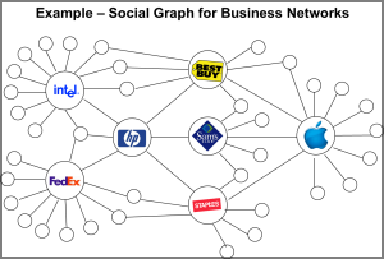
물론 기존의 RDBMS는 아직도 기업 DB의 많은 부분을 차지하고 있으며, 일반화를 통해 관계들을 보다 단순하게 규명해 준다는 장점을 갖고 있습니다.또한 요즘 화두가 되는 IoT(사물인터넷)가 궁극적으로 추구하는 것은 물리적인 사물들이 서로서로 연결되는 것인데요. 이것들이 연결되면, 그 형태는 어떻게 될까요? 왼쪽 그림과 같이 소셜 네트워크에처럼 ‘망형 구조’가 될 것입니다. 그리고 그러한 관계 구조 안에서 서로서로 정보를 주고받게 됩니다.
그리고 그러한 RDBMS들을 관리해 오던 기존의 MDM은 중앙 집중식으로 DB들 사이에 얽혀있는 마스터 데이터의 계층적인 관계와 처리를 기본으로 합니다. 그러므로 그림과 같이 중첩된 여러 네트워크에서 형성되는 각각의 분산된 관계(Edge)를 다루는데 성공적이지 못한 느낌이 있습니다.
그래서 이를 보완하기 위해 나온 방법이 바로 소셜 네트워크에서 사용되었던 NoSQL의 일종인 ‘Graph DB’를 벤치마킹하는 방법인데요. 이는 Graph Theory를 DB에 응용한 것으로, 그래프의 구조와 네트워크 데이터의 패턴 매칭, 추론을 포함하는 보다 지능적이고 의미론적인(Sematic) 쿼리를 포함하고 있습니다.
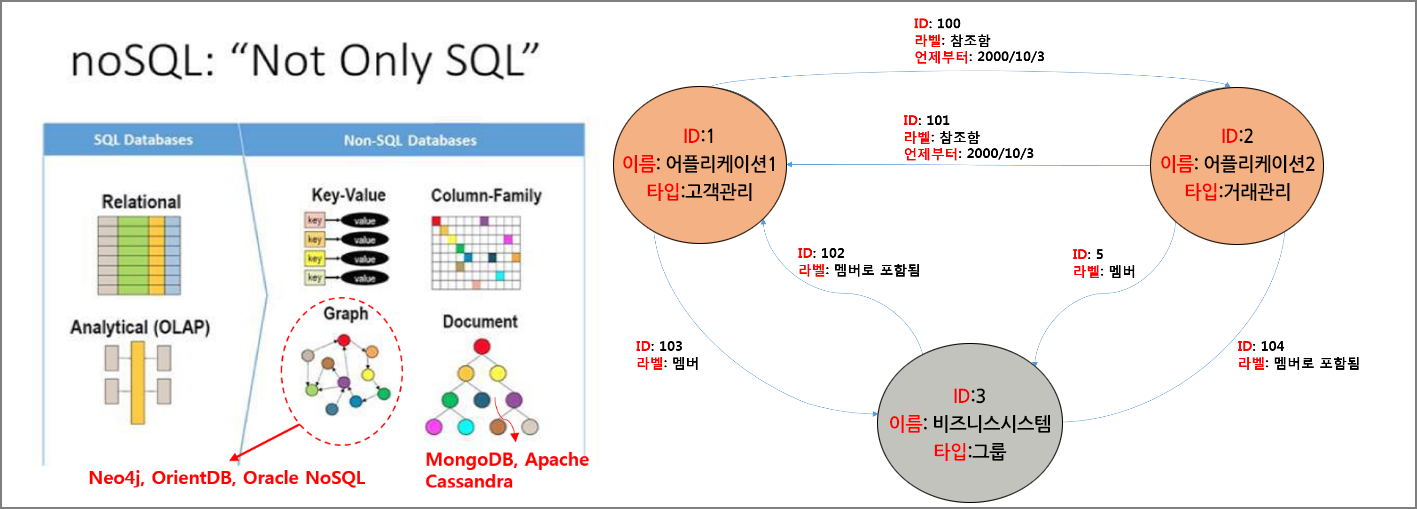
즉 위의 오른쪽 그림에서처럼 점(Node), 점들 그리고 그 점들이 가진 특질 사이를 잇는 연결선(Edge), 마지막으로 점에 대한 각각의 특질(Property)을 기본으로 구성되는데요. 이를 통해 RDBMS의 계층적인 인덱스를 통한 관계 구성을 인접한 노드들의 쌍을 가진 관계들로 대체합니다.
그리고 각각의 ‘점’은 사람, 비즈니스, 아이템, 조직, 계정, 애플리케이션 등으로 그 크기와 종류에 상관없이 추적하고 싶은 어떤 다양한 개체(Data Entity)를 포함할 수 있는데요. 특히 ‘특질’은 점•선과 관계한 적절한 정보들을 담고 있습니다. 즉 위의 그림과 같이 이름 및 타입, 역할 등 가질 수 있는 다양한 성질을 포함하고 있는 것이죠.
또한 점들을 잇는 선은 가장 중요한 것으로 이를 통해서 구체적인 관계와 패턴들을 규명해 줄 수 있는데요. 보다 구체적인 예는 다음에 제시한 표의 내용을 참고해 주시기 바랍니다.

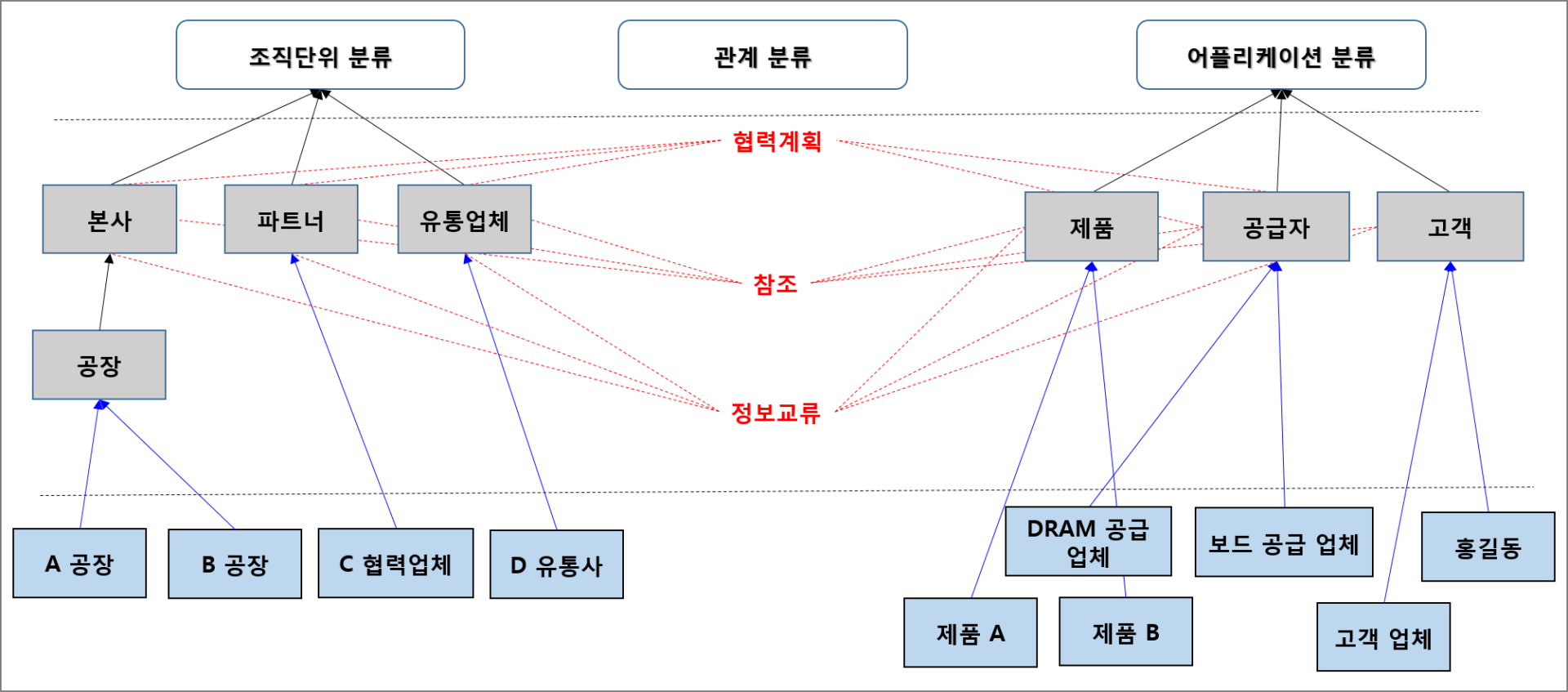
이미지를 클릭하시면 더 큰 이미지로 보실 수 있습니다.
위의 표를 보셨다면 이제는 이를 바탕으로 위의 그림과 같은 구조를 생각해 볼 수 있을 것 같습니다. 이는 기존의 중앙 집중식 구조를 사용했을 때를 묘사하고 있는데요. 그림을 살펴보면 여러 연계된 조직들과 마스터 데이터들 사이의 관계는 더 이상 직접적인 계층 구조로 형성되기 어렵다는 것을 알 수 있습니다. 즉 비즈니스와 IT가 뭔가 분리되어 있다는 느낌이 드는 것이죠.
여기에서 우리는 다양한 비즈니스들 사이의 정보 공유가 핵심이 되는 상황에서 계층 구조를 바탕으로 한 MDM이 가진 한계를 알 수 있습니다. 또한 그림에서는 나타나지 않은 비정형화된 빅데이터를 유입시키는 다양한 외부 애플리케이션들과 조직들, 그로 인해 추가될 수 있을 관계들 또한 정해진 것은 없으며 시간이 지나면 계속 변화합니다.
더 자세한 사항들이 있겠지만 결과적으로 Graph DB, 쿼리, REST/API를 이용하여 기존의 RDBMS 들을 서로 연결하고, 기존 MDM이 수행하던 데이터 매칭 과정을 관계 경향성을 내포한 엣지를 통해 원천적으로 정의할 수 있습니다. 또한 마스터 데이터가 되는 여러 각도와 단위들의 의미론적인 분류를 Graph DB에 각각 저장하고, 그 밖에 여러 규칙을 사용하여 기존 RDBMS와 그래프 사이의 상호 작용을 제어합니다.
즉 개체(점)들 별로 다른 점에서 접근할 수 있는 데이터의 종류에 차등을 두고 ‘Gremlin’, ‘Cypher’ 등을 이용해 그래프 쿼리에 일종의 역할을 부여하는데요. 의미론적으로 적합한 데이터들의 그래프를 그룹별로 혹은 계층별로 묶어서 관리하는 방법으로 여러 데이터 베이스를 관리하는 것입니다.
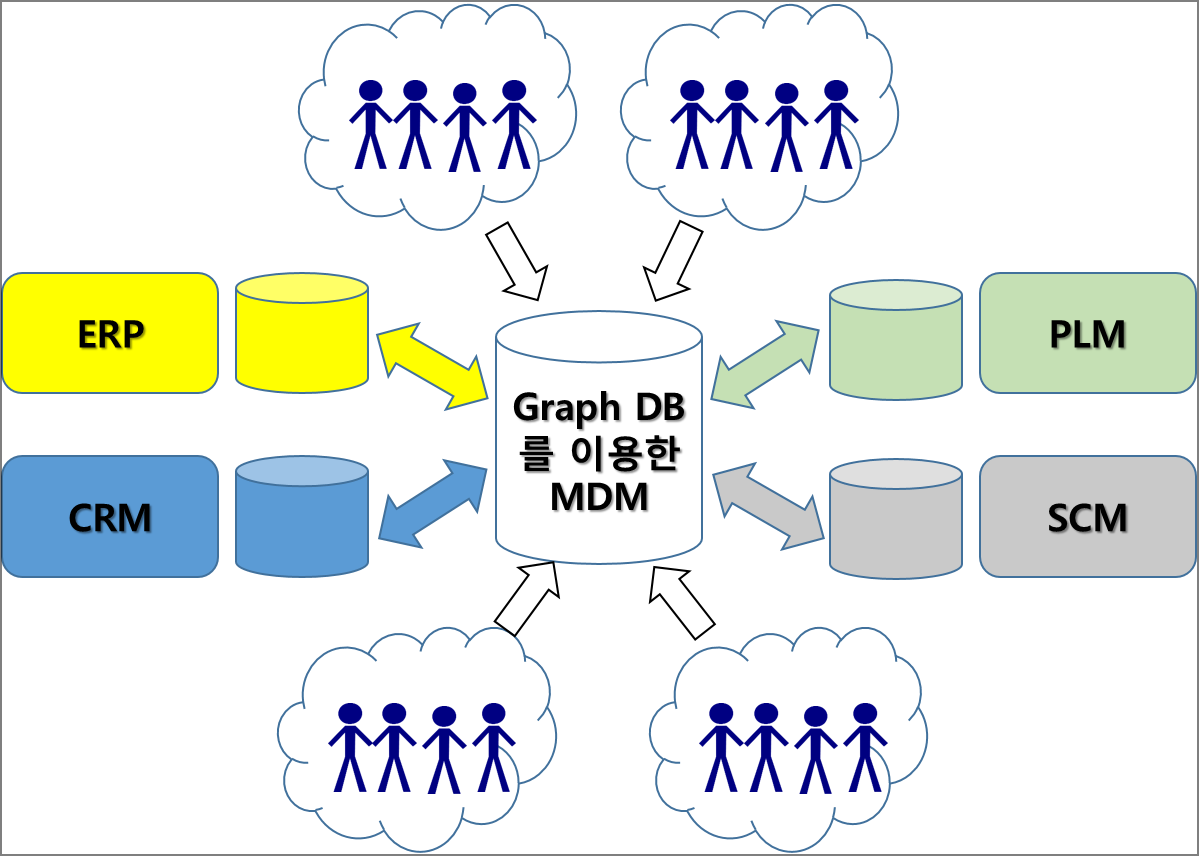
지금까지 설명한 내용은 위의 그림과 같이 구현될 수 있을 것 같은데요. 현재 ‘Pitney Bowes’, ‘Reltio’ 등의 회사에서 이러한 방법으로 MDM 솔루션을 구축하고 있고, 기존의 대형 DB 업체들인 ‘IBM’, ‘Oracle’ 등 또한 서서히 이런 흐름에 동참해 나가고 있는 상황입니다.
상호 보완적 빅데이터의 제조업 공급망 관리 적용 사례
작년 9월 중국의 한 공장에서 발생했던 화재는 전세계 DRAM 메모리 칩 가격의 폭등을 불러 일으켰습니다. 위의 그림과 같이 살펴보면, DRAM 부품을 필요로 하는 전자제품 제조업자들과 Contract 제조업체, 서브 콘트랙터, OEM들, 유통업자들은 하나의 거대한 공급망 그래프를 형성합니다. 소셜 네트워크와 크게 다를 바가 없는 것이죠.
이처럼 그래프로 연결된 관계 속에서 각각의 기업 입장에서는 이러한 상호 정보를 누가 먼저 신속하게 획득하느냐가 무척 중요합니다. 제품 단가가 달려 있기 때문인데요. 앞서 하나의 기업 내에서 신속히 이런 정보를 파악한 업체들은 부품값이 폭등하기 전, 경쟁사 보다 한발 앞서 대체 공급자를 물색해 기존 가격에 물량을 확보하는 등의 대응책을 마련합니다.
또한 연결된 어떤 비즈니스라도 망 내에 포함되면, 개별 비즈니스 노드들의 어떠한 정보라도 그들의 이익과 직결되겠죠. 이런 정보는 사실 기업이 자체적으로 보유한 내부 데이터들만으로는 파악이 불가능한데요.
다시 말해 실시간으로 변하는 공급자 및 외부 환경에서 비롯되는 변동 정보를 얼마나 빨리 획득해서 보유하고 있는 정형화된 정보와 연계하고, 덧붙여 신속한 의사 결정이 필요한지 보여 주는 좋은 예라고 할 수 있습니다.
SAP Hana Platform 등에서도 이런 것을 가능하게 하는 기능을 도입했는데요. 그리고, 2014년 가트너(Gartner)가 발표한 제품 공급망 관리 IT 서비스 부분에서 주목할만한 업체로 선정된 ‘Elementum’이란 스타트업 업체가 제시하는 솔루션에도 주목해 보면 좋을 것 같습니다.
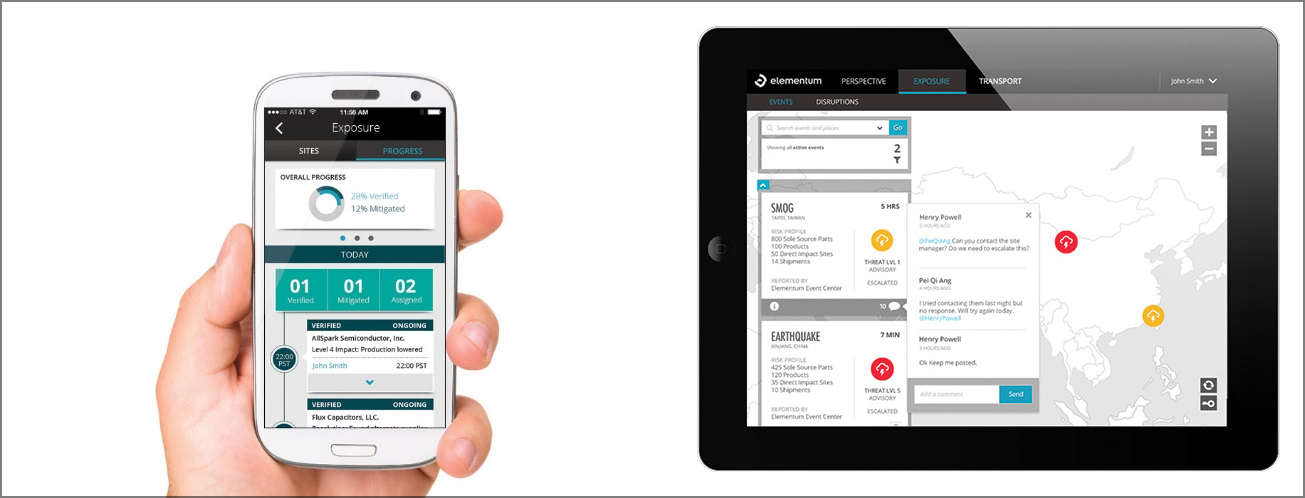
이 업체는 앞서 설명한 MDM과 빅데이터의 상호 보완성을, 완벽하지는 않지만 하나의 애플리케이션으로 구현해 내서 실제로 사용하기 편리하게 제공하고 있습니다. NoSQL 기반의 Document DB의 일종인 ‘Mong DB’와 Graph DB인 ‘Neo4j’를 이용해 공급망 관리를 소셜 네트워크의 그것처럼 다룰 수 있는 플랫폼을 구축하였습니다.
그리고, 세계 2위의 제조 업체인 ‘Flextronics’의 지원을 받고 있는데요. 그 업체의 지원 하에 계약으로 맺어진 다른 업체들을 플랫폼으로 연결할 수 있었고, 이것을 기반으로 자발적인 기업들의 참여를 유도해서 더 확장해 나가려는 계획을 갖고 있다고 합니다.
또한 플랫폼을 통해 다양한 종류의 데이터 소스들을 연계하고, URI(Uniform resource identifier)를 통해 소스들을 식별하며, 분산된 여러 데이터 베이스들에서 역시 다양한 종류의 쿼리를 통해 데이터를 수집하는데요. 몇몇 업체들과는 직접 그들의 공장이나 시스템과 연결된 실시간 스트리밍 프로세싱으로 데이터를 얻기도 합니다.
그리고 수집된 다양한 형식의 데이터들은 Mongo DB와 같은 NoSQL을 통해 저장하고, 저장된 데이터들의 관계를 Graph DB를 통해 미리 정의한 노드들에 맵핑하는 식으로 관리하는 것이죠.
이것은 비단 이 업체에만 해당하는 것은 아닐 것입니다. 이렇게 흡사한 기술을 적용할 수 있는 분야는 무궁무진할 것이라고 생각되는데요. 왜냐하면 현재 우리가 살아가고 있는 이 세상 자체가 이미 수없이 많은 ‘중첩된 그래프’의 형태로 이어져 있기 때문입니다.
그러나 이어져 있는 모든 개체들이 완벽한 정보를 공유하지 않는 이상, 개체들 및 환경의 변화에서 주어지는 조그마한 힌트들로 우리는 어떤 경향성을 ‘유추’해 의사 결정에 이용할 수 밖에 없을 것 같은데요. 지금보다 시간이 지난다고 해도 사람들은 많은 정보를 쉽게 공유하려고 하지는 않을 것 같습니다.
그리고 아직까지는 회사들이 어떻게 공급망 내에서 상류 및 하류에 연결된 다른 회사들과 상호 작용하는지에 대해 제대로 모델링을 제시한 사례가 아주 드뭅니다. 심지어 대기업들 조차도 부품 공급자들 리스트에 대한 정확한 마스터 데이터를 확보하지 못한 경우가 많은데요. 설령 그러한 데이터를 보유한 소수의 기업들이 있다고 해도 공급자들에 대해서는 거의 정보가 없는 경우가 허다합니다.
그 이유는 일반적인 회사들은 결코 그들의 고객 및 공급자들에 대한 정보를 쉽게 드러내지 않기 때문이겠죠. 소셜 네트워크와는 또 다른 제약이라고 볼 수 있습니다.
지금까지 생산과 서비스 융합을 위한 제조 정보 및 시스템 통합을 위한 방안을 함께 생각해 보았습니다. 지금 이 순간에도 수많은 정보가 쏟아져 나오고 있는 빅데이터 시대에 살아가고 있는 우리는 이제 혼자만 정보를 소유해서는 안될 것 같습니다. 대신 상호 보완적으로 함께 정보를 공유하고, 그 정보를 어떻게 잘 통합하여 활용하느냐 하는 것이 중요한 시기가 된 것 같다는 생각이 듭니다.
지금 이 글을 읽고 계신 분들의 생각은 어떠신가요? 열린 마음, 공유, 그리고 지혜로운 통합이 필요한 때입니다.
글 l 이승엽 연구원
- ETL이란 Data Warehouse 구축 시 데이터를 운영시스템에서 추출하여 가공한 후 Data Warehouse에 적재하는 모든 과정을 말한다. ETL은 데이터 추출(Extraction), 변환(Transformation), 적재(Loading)의 약자이다. [본문으로]
- 출처: ‘The Steadily Growing Database Market Is Increasing Enterprises’ Choices,’ Forrester Research, 2013 [본문으로]


