
‘내가 가장 좋아하는 레스토랑은 내 이름을 알고 있는 곳’이라는 말 들어본 적 있나요? 내가 무엇을 좋아하고 싫어하는지 알고 거기에 맞게 음식을 제공해 주는 곳이라면 당연히 자주 가게 되겠죠. 꼭 음식점에 국한된 얘기는 아닙니다. 이렇게 나를 알고 내가 좋아할 만한 서비스나 상품을 알아서 제공해 주는 것이 바로 『개인화 서비스』입니다.

개인화 서비스, 성공의 주요 요소
전세계적으로 개인화 서비스로 유명한 두 곳이 있는데요. 바로 아마존과 넷플릭스 입니다.

아마존은 이미 10여년 전부터 ‘도서 추천’을 시작으로 개인화 서비스를 제공하고 있는데요. 이것이 지금의 아마존의 성공을 이끈 중요한 요소 중의 하나라고 합니다.
현재 개인화 서비스를 통해 아마존 전체 매출의 약 35% 이상을 얻고 있다고 하니 엄청난 규모라고 할 수 있습니다. 이러한 아마존 성공 사례를 통해 많은 기업들이 개인화에 대한 관심을 가지기 시작했다고 하는데요.
또 다른 성공 사례는 미국 최대 온라인 스트리밍 서비스 기업인 넷플릭스를 들 수 있습니다. 넷플릭스는 우편으로 DVD를 대여하는 사업으로 시작해 2009년도에 온라인 스트리밍 서비스에 뛰어 들어 현재는 연 매출이 4조원에 달할 정도로 성장했습니다.
이러한 성장의 중요한 역할을 한 것이 바로 영화, 드라마와 같은 ‘콘텐츠에 대한 개인화 추천’ 서비스인데요. 넷플릭스는 콘텐츠 장르를 76,800개 이상으로 세밀하게 분류하고 이를 개인화 추천에 활용해서 80% 이상의 놀라운 추천 적중률을 자랑하고 있습니다.
위 2가지 대표적 사례 외에도 개인화 서비스 사례는 무수히 많은데요. 아마 여러분도 이미 알게 모르게 개인화 서비스를 경험해 보셨을 것입니다.
고품질 개인화 서비스 조건! 분석과 메타(Meta)정보
그러면 고품질의 개인화 서비스를 제공하기 위해 필요한 것은 무엇일까요? 바로 『분석』과 『메타(Meta)정보』입니다.
1. 분석
개인화 서비스는 고객에게 ‘무엇을 좋아하시나요?’라고 명시적으로 묻지 않습니다. 대신 고객이 그동안 구매하거나 사용해 왔던, 또는 관심을 보였던 상품, 서비스 등의 이력을 분석해서 개개인의 선호 성향을 파악하고 좋아할 만한 상품을 추천해 줍니다.
따라서 개인화 서비스에서 분석은 매우 중요한 요소입니다. 그렇기 때문에 아마존과 넷플릭스도 분석의 품질을 높이기 위해서 많은 금액을 지속적으로 투자하고 있는 것이죠.
2. 메타(Meta)정보
또 한가지는 분석의 근간이 되는 상품이나 서비스의 특징, 속성 등을 정의한 메타(Meta) 정보인데요. 분석 알고리즘이 아무리 뛰어나도 메타 정보가 허술하면 제대로 된 개인화 서비스를 제공할 수 없을 것입니다.
넷플릭스는 세밀한 메타 생성을 위해 한 편의 영화마다 영화의 특징을 정리한 36페이지의 문서를 작성한다고 하는데요. 이것은 자동화가 불가능하여 사람이 할 수 밖에 없는 작업입니다.
이렇듯 메타 정보는 정확성과 세밀함, 그리고 꾸준한 품질 유지가 필요한데요. 각 기업들이 메타 정보의 중요성을 인식하여 지속적인 투자와 노력을 해야 할 것입니다.
개인화 서비스 분석 방법, 협업 필터링(Collaborative Filtering)
그렇다면 개인화 서비스를 위한 분석에는 어떤 방법이 사용될까요? 여러 방법이 있을 수 있겠지만 여기서는 아마존이 사용해서 유명해진 『협업 필터링』에 대해서 간단하게 살펴볼까 합니다.
협업 필터링은 많은 사용자들로부터 얻은 아이템, 즉 상품에 대한 선호도를 이용하여 사용자들의 관심사를 예측하는 기법입니다. 주로 도서, 영화, VOD, 음악 추천 등에 사용되고 있습니다.
상품에 대한 선호도는 사용자의 구매나 조회 이력, 별점 정보 등을 근간으로 해서 산출할 수 있는데요. 산업 도메인, 기업의 비즈니스 특성 등을 고려해서 선호도 모델은 달라져야 합니다.
협업 필터링에는 크게 사용자 기반(User-based)과 아이템 기반(Item-based)이 있습니다.
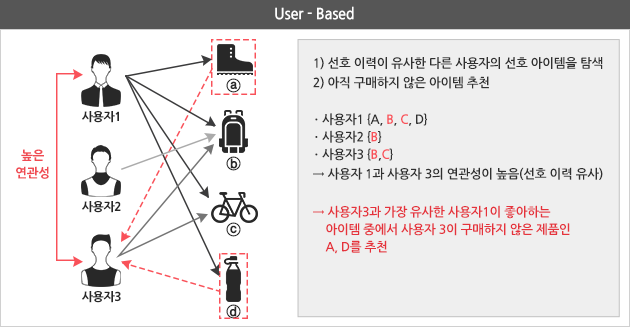
위 그림에서 보여주듯이 ‘사용자 기반 협업 필터링’은 나와 선호성향이 비슷한 다른 사용자들을 찾아 같은 사용자 그룹으로 묶은 후 동일 그룹에 있는 다른 사용자들이 많이 선호하는 상품을 추천해 주는 방식입니다
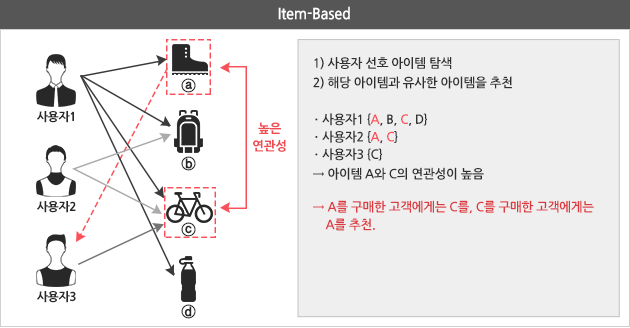
반면 ‘아이템 기반 협업 필터링’은 사용자가 선호하는 과거 구매 혹은 조회 아이템을 기반으로 그 아이템과 선호 연관성이 높은 다른 아이템을 추천하는 방식이죠. 아마존도 아이템 기반 협업 필터링을 사용하고 있습니다.
선호성향이 비슷한 다른 사용자 또는 과거 구매 아이템과 연관성이 높은 아이템은 사용자들의 개별 아이템에 대한 선호도를 기반으로 다양한 거리계산법(Cosine, Euclidean 등)을 통해 찾을 수 있는데요. 이것을 유사도(Similarity)라고 부릅니다.
즉, 사용자 기반 협업 필터링은 사용자간의 유사도를 기반으로 아이템을 추천하는 방식이고, 아이템 기반 협업 필터링은 아이템간의 유사도를 기반으로 추천하는 방식이라고 할 수 있습니다.
개인화 서비스의 지향점, 세렌디피티(Serendipity)
지금까지 개인화 서비스의 대표적 사례와 중요한 요소, 그리고 사용되는 알고리즘에 대해 설명드렸는데요. 마지막으로 개인화 서비스의 지향점에 대해 말씀 드리겠습니다.
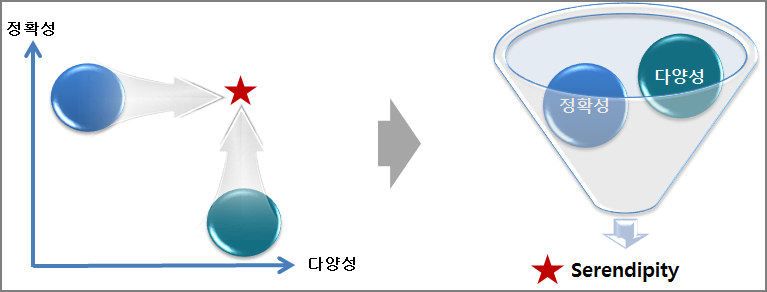
개인화 서비스의 추천 모델은 추천의 다양성과 정확성을 높이는 방향으로 발전하고 있습니다. 하지만 정확성을 향상시키면 다양성이 감소하고, 다양성을 향상시키면 정확성이 감소하는 경향이 나타납니다.
즉, 고객에게 잘 팔리는 인기 상품군 만을 추천한다면 정확성은 높아질지는 모르나 다양성은 감소하게 되고, 다양성을 높이기 위해 롱테일(long tail) 상품을 추천하게 되면 그만큼 정확성이 떨어지게 되는 거죠.
따라서 현재 학계나 기업에서는 정확성과 다양성이라는 두 마리 토끼를 잡기 위해 개인화 추천 모델 향상에 관한 연구를 계속하고 있습니다. 그렇다면 이러한 정확성과 다양성이 향상된 추천 모델의 최종 지향점은 무엇일까요? 그것은 바로 세렌디피티(Serendipity)라고 할 수 있습니다.
즉, 고객이 생각지도 못했던, 하지만 원하고 있던 새로운 상품을 추천함으로써 고객에게 뜻밖의 기쁨을 선사하여 고객에게는 만족을, 기업에게는 매출 증대를 이루는 것입니다.
이렇듯 빅데이터는 점점 더 세분화된 분석을 제공하며 발전해 나가고 있습니다. 나도 몰랐던, 하지만 내가 원하고 있었던 상품이나 서비스가 무엇인지 여러분도 잘 고민해 보십시오. 여기서 빅데이터 분석의 새로운 아이디어가 생겨날 수 있을 것입니다.
글 ㅣ LG CNS 빅데이터사업부문
[‘빅데이터 분석, 그것이 알고싶다’ 연재 현황 및 향후 계획]
● 1편 IT 인프라 장애, 미리 예측할 수 있다 : http://blog.lgcns.com/797
● 2편 보안로그, 통합하면 패턴이 보인다 : http://blog.lgcns.com/823
● 3편 안전한 결제를 보장하는 FDS(Fraud Detection System) : http://blog.lgcns.com/846
● 4편 소셜 분석으로 고객의 삶을 이해하다 : http://blog.lgcns.com/890
● 5편 DW(Data Warehouse)의 미래, Hybrid : http://blog.lgcns.com/929
● 6편 구매 심리를 예측해 매출을 올려주는 개인화 추천 : http://blog.lgcns.com/940
● 7편 스마트그린, 에너지 그리고 빅데이터 : http://blog.lgcns.com/983
● 8편 좋거나 나쁘거나 이상하거나..(빅데이터 분석 A to Z) : http://blog.lgcns.com/988


