
데이터 관리의 진화 단계
다른 산업들과 마찬가지로 2020년 데이터 산업에도 큰 변화가 나타났습니다. 지난해 코로나 팬데믹으로 기업들은 원격 근무라는 새로운 표준(new normal)에 빠르게 적응해야 했습니다. 기업 내 임직원들이 서로 다른 장소와 시스템에서 데이터에 액세스해야 함에 따라 클라우드가 절대적으로 필요하게 됐습니다. 이에 데이터 거버넌스와 보안이 최우선 순위로 부상하기 시작했고, 기업은 빠른 변화의 필요성을 체감하면서 데이터 관련 투자를 늘렸습니다. 또한 시스템을 업그레이드하며 보다 완벽한 데이터 스택을 만들고자 했습니다.
2021년에도 최신의 변화를 따라잡기 위해 데이터 인프라가 진화할 것으로 예상됩니다. 그 가운데, 데이터 웨어하우스(DW, Data Warehouse)와 데이터 레이크의 컨버징이 데이터 매니지먼트 트렌드 중 하나로 꼽히고 있습니다.
그동안 데이터 설계자들은 데이터 웨어하우스와 데이터 레이크 두 가지 주요 시스템으로 분리하여 데이터 운영을 설계해왔습니다. 여전히 다수의 기업들은 분석 및 리포팅 유즈케이스에 활용되는 특수 데이터를 위한 ‘데이터 웨어하우스’와 모든 데이터를 위한 ‘데이터 레이크’라는 두 개의 시스템을 모두 사용하고 있는데요. 하지만 점차 두 개의 시스템이 수렴하는 현상이 나타나고 있습니다. 이는 조직 내에서 데이터가 단절되는 데이터 사일로(the silos of disconnected data) 이슈를 해결하고자 하는 흐름인데요. 오늘은 대표 사업자인 스노우플레이크(Snowflake)와 데이터브릭스(Databricks)가 이러한 이슈를 어떻게 해결하는지 분석해보고자 합니다.
요약해서 설명하면 스노우플레이크와 같은 데이터 웨어하우스 플레이어는 데이터 저장과 컴퓨팅 비용을 분리합니다. 데이터 웨어하우스에 모든 데이터를 저장하는 비용을 크게 줄여주면서도, 반정형 데이터(semi-structured data)에 대한 지원에 나서고 있는 것이죠. 반면, 데이터브릭스와 같은 데이터 레이크 플레이어는 ‘레이크 하우스’라는 새로운 비전을 내세우며, 이를 실현할 제품군을 출시하고 있습니다.
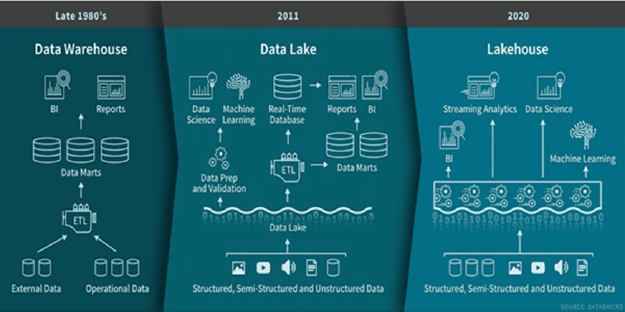
위 그림에서 ETL(Extraction, Transformation, Loading)은 데이터 웨어하우스 구축 시 데이터를 운영 시스템에서 추출하여 가공(변환, 정제)한 후 데이터 웨어하우스에 적재하는 모든 과정을 보여줍니다.
1980년대 이후 시작된 “데이터 웨어하우스”의 시대
데이터 웨어하우스는 기업의 의사 결정 지원 및 비즈니스 인텔리전스(BI) 애플리케이션에 있어 오랜 역사를 지니고 있습니다. 탄생한 1980년대 후반부터 데이터 웨어하우스의 기술은 계속해 발전했습니다. 그리고 MPP(Massive Parallel Processing) 아키텍처를 통해 더 큰 사이즈의 데이터를 처리할 수 있는 시스템으로 진화했습니다.
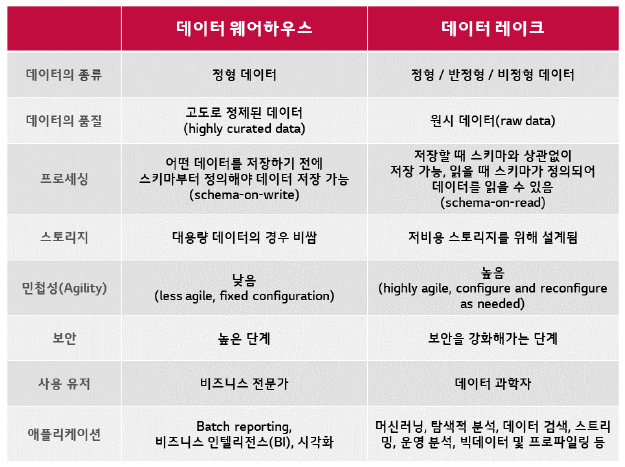
그러나 다수의 현대 기업들은 시계열, 로그, 이미지, 도큐먼트 등의 비정형 및 반정형 데이터를 비롯하여, 다양성/속도/볼륨이 높은 데이터를 처리해야만 하는 이슈에 직면해 있었죠. 따라서 정형 데이터에 적합했던 데이터 웨어하우스는 데이터 사이언스나 머신러닝 등의 유즈 케이스에 적합하지 않게 됐습니다. 뿐만 아니라 데이터 웨어하우스는 대량의 데이터셋을 저장하기에도 비용적인 면에서 효율적이지 않다는 한계점에 봉착했습니다.
2010년 이후 ‘데이터 레이크’의 등장
기업들이 다양한 소스원에서 많은 양의 데이터를 수집하기 시작하면서, 설계자들은 다양한 분석 제품과 워크로드에 대한 데이터를 수용할 수 있는 단일 시스템을 구상하기 시작했습니다. 약 10년 전, 기업들은 다양한 포맷의 원시 데이터 저장소인 ‘데이터 레이크’를 구축하기 시작했습니다. 참고로 데이터 레이크는 정형, 비정형 구분없이 모든 원시 데이터(raw data)를 저장할 수 있는 저장소와 같은 개념입니다.
하지만 데이터 레이크 역시 몇 가지 중요한 기능이 부족했는데요. 트랜잭션을 지원하지 않고, 데이터 품질을 보장할 수 없다는 단점을 지니고 있었습니다. 이 외에도 일관성/고립성(consistency/isolation) 부족 이슈로 인해 appends/reads/batch/streaming 작업을 혼합하는 것이 거의 불가능했습니다. 이러한 이유로 데이터 레이크의 강점은 실현되지 못했고, 오히려 많은 이점을 상실하게 됐죠.
결국, 데이터 레이크와 여러 개의 데이터 웨어하우스, 스트리밍/시계열/그래프/이미지 데이터베이스와 같은 다른 전용 시스템 등 복수의 시스템을 사용하는 것이 가장 일반적인 접근 방식이 되었습니다. 하지만, 복수의 시스템을 사용하는 것 역시 복잡성의 증가를 야기시켰습니다. 데이터 전문가가 항상 서로 다른 시스템 간의 데이터를 이동하거나 복사해야 했기 때문에 지연이 발생할 수밖에 없었던 것인데요. 이는 치명적인 한계점으로 작용했습니다.
데이터 레이크와 데이터 웨어하우스의 장점을 결합한 ‘레이크하우스’의 등장
데이터 레이크의 한계를 해결하려는 새로운 시스템이 등장하기 시작했습니다. 데이터 레이크와 데이터 웨어하우스의 장점을 결합한 새로운 아키텍처, ‘레이크하우스(lakehouse)’가 그 주인공입니다.
S&P Global는 레이크 하우스라는 용어가 최근 몇 년 동안 데이터 및 분석 영역에서 주목받고 있다고 진단하고 있습니다. 레이크 하우스라는 용어의 등장을 살펴보면, 2020년 초 데이터브릭스라는 기업이 데이터 웨어하우스의 데이터 구조 및 관리 기능과 데이터 레이크에 사용되는 저비용 스토리지를 결합하는 자사의 접근 방식을 설명하고자 ‘레이크하우스(lakehouse)’라는 용어를 채택하면서 널리 퍼진 것으로 알려지고 있습니다.
그럼에도 데이터브릭스는 레이크 하우스라는 용어를 사용한 최초의 기업은 아닌데요. 그 시작은 2019년 말경 AWS에서 비롯됐습니다. AWS는 Amazon Redshift Spectrum과 관련하여 레이크 하우스라는 용어를 사용했다고 합니다. 이때 Amazon Redshift Spectrum은 Amazon Redshift 데이터 웨어하우스 사용자가 Amazon S3 클라우드 서비스에 저장된 데이터에 쿼리를 적용할 수 있도록 하는 서비스를 의미합니다.
한편, 레이크 하우스라는 용어를 사용하지 않더라도, 레이크 하우스를 제공한다고 말할 수 있는 업체들이 다수 있습니다. 예를 들어 스노우플레이크의 마케팅은 레이크 하우스라는 용어를 사용하지 않고 ‘데이터 클라우드’라는 용어를 선호하는데요. 데이터 클라우드 역시 복수의 데이터 처리 및 분석 워크로드를 지원하는 기능을 지니고 있습니다.
요약하면, 레이크 하우스는 데이터 웨어하우스의 데이터 구조 및 데이터 관리 기능을 데이터 레이크의 저렴한 스토리지와 결합하도록 설계된 환경이라고 할 수 있습니다. 레이크 하우스는 클라우드 스토리지에 데이터를 유지하는 비용과 유연성이라는 이점을 누리게 함으로써 데이터 레이크와 데이터 웨어하우스 간의 경계를 모호하게 합니다.
이번에는 데이터 매니지먼트 영역을 혁신하고 있는 라이징 스타로 주목되는 스노우플레이크와 데이터브릭스를 상세히 분석해보겠습니다.
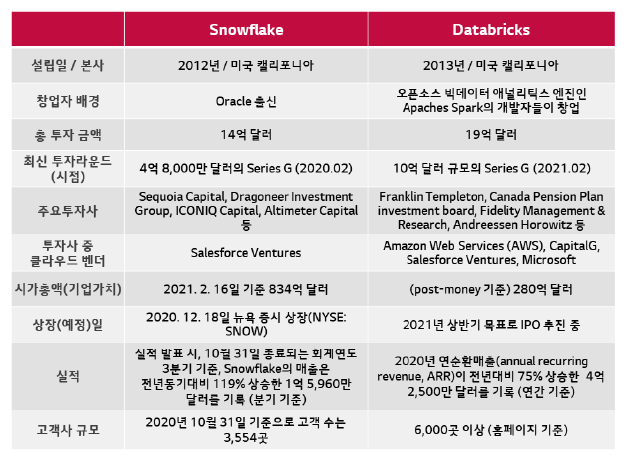
지난해 시장에서는 가장 주목받은 테크 IPO 사례로서 스노우플레이크가 이목을 끈 바 있습니다. 그리고 데이터브릭스는 제2의 스노우플레이크로 기대 받고 있는 상황입니다.
[출처]
towardsdatascience(https://towardsdatascience.com/the-top-5-data-trends-for-cdos-to-watch-out-for-in-2021-e230817bcb16)
siliconangle(https://siliconangle.com/2021/02/01/massive-1b-infusion-databricks-takes-aim-ipo-rival-snowflake/)
databricks blog (https://databricks.com/blog/2020/01/30/what-is-a-data-lakehouse.html)
Amazon AWS (https://aws.amazon.com/data-warehouse/?nc1=h_ls)
intersong(https://intersog.com/blog/what-is-the-difference-between-data-lakes-data-marts-data-swamps-and-data-cubes/)
spglobal(https://www.spglobal.com/marketintelligence/en/news-insights/blog/so-the-data-lakehouse-is-now-officially-a-thing-what-is-it-and-why-should-you-care)
Crunchbase (https://www.crunchbase.com/organization/snowflake-computing)
Crunchbase (https://www.crunchbase.com/organization/databricks)
글ㅣ LG CNS 정보기술연구소 기술전략팀 (*Collaborated with ROA Intelligence)


