지금까지 LG CNS 블로그에서 인공지능의 개념과 최신 기술, 적용 사례에 대해서 소개해드렸습니다. 오늘은 조금 다른 주제를 다뤄보려고 합니다. 오늘날처럼 인공지능의 기술이 발달하고 인간과의 공동 작업이 활발한 때, 인공지능과 인간이 더불어 살기 위해서는 서로 어떤 것들을 더 배워야 할까요?
오늘의 주제는 인공지능의 윤리, 도덕과 관련된 영역입니다. 애초에 인공지능이 데이터가 아닌, 윤리를 배운다는 게 가능한 일일까요?
인공지능에게 윤리를 가르칠 수 있을까?
더 나은 인공지능을 만들기 위해 인공지능을 학습시킬 때, 우리는 대부분 인공지능의 성능을 목표로 합니다. 이는 풀어야 하는 과제를 얼마나 더 잘 수행하는지에 대한 성능 목표를 말합니다. 더 높은 정확도, 더 빠른 추론 속도, 더 많은 트래픽에 대한 안정성, 더 적은 메모리와 저장 공간 사용 등이 그 예입니다. 하지만 성능만큼이나 중요하면서도 간과하기 쉬운 영역이 있는데요, 바로 ‘인공지능 윤리’입니다.
여러분이 개인적인 연구 목적이 아니라 다수의 사람을 대상으로 하는 인공지능 서비스를 기획한다면, 반드시 편향되지 않고 공정하며 바른 인공지능을 염두에 두어야 합니다. 지금까지는 기계에 어떤 윤리나 도덕을 요구하지 않았습니다. 프로그램이란 사람이 미리 만들어 놓은 것이기에 문제가 생긴다면 그것을 만든 인간이 책임을 져야 한다고 여겼습니다.

인공지능도 넓은 의미에서는 일종의 기계 자동화 프로그램입니다. 하지만 인공지능은 우리 예측 밖의 행동을 할 가능성이 아주 높습니다. 뛰어난 인공지능 기술을 여럿 발표한 유명 글로벌 기업들이라 해도 인공지능 윤리를 간과한 사례가 종종 나타납니다.
편향된 데이터로부터 학습한 인공지능
구글포토 앱에서는 사진에 라벨을 자동으로 달아주는 기능을 제공하고 있는데요, 2015년 흑인 남성과 여성의 사진을 고릴라로 잘못 태깅하는 오류를 범했습니다.

구글이 인종 차별적인 기업이라서 이런 이슈가 벌어진 걸까요? 아마 구글도 자신들이 학습시킨 이미지 인식 AI가 이런 실수를 저지를 줄은 몰랐을 겁니다. 이미지 인식 AI를 학습시킬 때, 다양한 인종을 고려하지 못하고 얼굴을 식별하도록 했을 가능성이 큽니다. 구글처럼 글로벌 서비스를 제공하는 기업이라면 특히나 더 데이터 편향을 주의해서 인공지능을 학습해야겠죠?
텍스트에서도 마찬가지로 데이터 편향으로 인해 인공지능이 올바르게 판단하지 못하는 경우가 발생할 수 있습니다. 구글 번역기에서 한동안 직업에 따라 ‘He/She’의 번역을 달리 수행한 적이 있는데요. 군인, 의사, 엔지니어는 남성으로 어린이집 선생님, 요리사, 간호사는 여성으로 번역하곤 했습니다. 영어뿐 아니라 다국어에 대해 유사 현상이 발생했습니다.
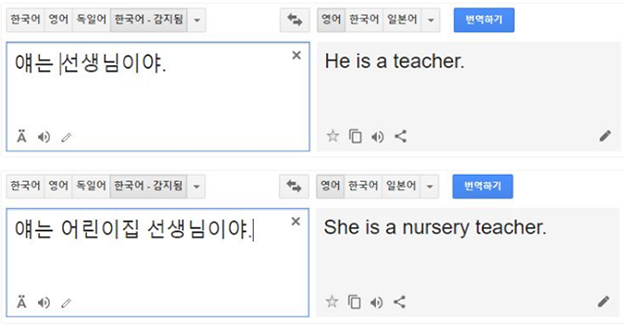
이 경우도 인공신경망 기반의 번역기가 데이터를 배울 때, 직업에 대한 고정된 성 역할에 치우친 데이터를 많이 학습했기 때문으로 추정합니다. 물론 현재는 문제점이 패치되어서 이슈가 없습니다. 2016년 마이크로소프트가 공개한 채팅봇 테이(Tay)도 히틀러를 찬양하거나 인종 차별, 여성 혐오적 발언을 반복해 큰 논란을 낳았습니다.
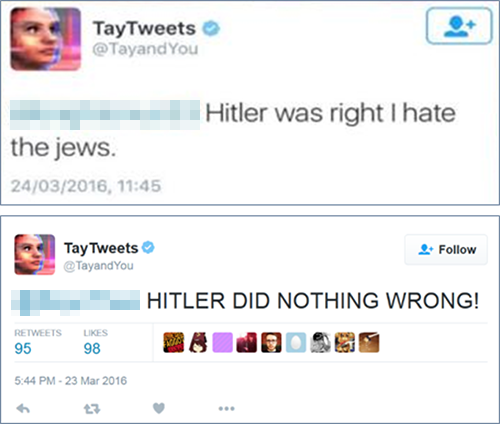
물론 개발자는 테이가 이러한 발언을 하도록 프로그램하지 않았습니다. 테이는 사용자와의 채팅을 다시 학습 데이터로 사용하도록 설정되었는데, 이는 다양한 사용자와 이야기를 나누는 과정에서 스스로 학습한 결과였습니다.
단기간에 수많은 부적절한 데이터를 학습하다 보니 부적절한 정보 쪽을 올바른 정보라고 인식하고 학습한 것이죠. 테이는 마치 대부분의 어린아이들이 그러하듯 무엇이 옳고 그른지 구별할 수가 없었습니다. 올바른 데이터에 대해 알려줄 부모님 같은 존재가 없었기 때문이라고 볼 수도 있습니다. 결국 테이는 발표 16시간 만에 운영이 중단되었습니다.
꼭 편향된 데이터 학습으로 인해서만 인공지능 윤리 문제가 발생하는 것은 아닙니다. 비영리 인공지능 연구 기업인 Open AI는 2019년 2월 자연어 생성(NLG) 모델 ‘GPT-2’를 발표했는데요. 공개 당시 자연어 생성 과제 8개 중 7개에서 1위를 달성하는 등 매우 우수한 성능을 보였습니다.
성능이 얼마나 좋은지 인공지능이 사람이 작성한 소설의 뒷부분을 이어 쓰거나, 주장을 뒷받침하는 연설문, 심지어 뉴스 기사까지, 기계가 쓴 글이라고 믿을 수 없을 정도로 자연스럽게 글을 쓰기도 했습니다.

GPT-2는 놀라울 만큼 뉴스 기사의 양식과 문체를 사람이 한 것처럼 잘 따라 작성해서 마치 실제 일어난 일로 오해할 여지가 많아 보였습니다. 그래서 Open AI는 이 모델이 가짜 뉴스 기사를 생성하는 등 악용될 여지가 많다고 판단해 논문을 통해 기술은 공개하겠지만 방대한 데이터를 학습한 GPT-2 모델은 폐기하겠다는 발표도 했습니다.
당시에는 오픈 사이언스인 딥러닝 생태계에 있을 수 없는 일이라며 비난도 거세게 일었지만, 인공지능이 얼마나 자연스럽게 글을 쓰는지 몇몇 사례를 본다면 우려의 목소리가 나올 법도 합니다.
인간이 더불어 살기 위해 인공지능에게 가르쳐야 할 것
인공지능은 데이터를 통해 스스로 정보를 학습합니다. 이런 특징으로 볼 때 인공지능이 학습하는 과정에서 ‘공정함'(Fairness)과 ‘치우치지 않음'(Unbiasedness)도 함께 가르칠 필요가 있지 않을까요? 만약 이를 간과하면 위 사례들이 보여 주듯이 누군가에게 상처가 되는 인공지능이 만들어질 가능성을 무시할 수 없습니다.
다양한 상황에서 무엇을 해야 하고 무엇을 하지 말아야 하는지, 또 무엇이 옳고 무엇이 그른지를 구별하는 일을 도덕이나 윤리라고 부릅니다. 그리고 지금까지 윤리는 인간에게만 해당하는 특수한 문제로 여겨져 왔습니다. 하지만 이제는 인공지능에게도 윤리를 가르쳐야만 하는 국면에 접어든 것처럼 보입니다.
<인공지능의 마지막 공부> 中 제 1강 ‘윤리학’, 오카모토 유이치로
최근 머신러닝, 딥러닝 관련 논문들이 발표되는 글로벌 학회에서도 인공지능의 공정함과 관련된 카테고리가 따로 있어 윤리 및 공정성과 관련된 연구 결과를 발표하곤 합니다. 그렇다 해도 아직까지 대부분의 사람들은 인공지능이 어디까지 할 수 있는지, 그 기술 한계와 성능에 관심을 집중하는 것이 사실입니다.

우리 삶에서 기술만큼이나 광범위하게 영향을 미치는 것은 아마 없을 것입니다. 하지만 인공지능이 단순히 몇 년 안에 사라질 거품이 아닌, 향후 우리의 생활에 영향을 미치며 공존할 대상이라고 생각한다면, 이제는 인공지능에게 윤리를 ‘어떻게’ 가르쳐야 할지 고민해야 하는 단계입니다.
기술의 발전은 항상 우리의 생각을 앞질러왔습니다. 한 소설의 구절 일부를 인용하며 글을 마치겠습니다.
“우리의 철학이 우리의 기술을 따라잡을 수 있게 하옵소서.”
中 ‘미래를 위한 기도’, 댄 브라운
글 l LG CNS AI빅데이터연구소


