오늘날 신경망을 깊게 쌓아 올린 딥러닝 기반 알고리즘들은 다양한 분야에서 미증유의 퍼포먼스를 보여주고 있습니다. 심층 신경망 연구는 하드웨어의 눈부신 발전과 함께 두각을 나타내기 시작했으며, 더 좋은 성능의 알고리즘을 만들어내기 위해 각 기업 및 학계의 연구소에서는 더 강력한 최신의 GPU와 TPU를 사용한 연구를 진행하고 있습니다.

이렇게 강력한 하드웨어와 전력을 쏟아부어야 만들 수 있고 사용할 수 있는 딥러닝 알고리즘. 우리 손엔 자그마한 스마트폰 정도가 쥐어져 있는 것 같은데, 도대체 어떻게 해야 연구소에서 우리 삶 속으로 꺼내올 수 있을까요? 이 포스트를 통해 인공지능(AI) 경량화의 필요성과 그 흐름에 대해 짚어보는 시간을 갖고자 합니다.
경량화의 필요성
심층 신경망의 성능을 끌어올리기 위한 가장 단순한 방법의 하나는 네트워크를 더 깊고 넓게 쌓아 올리는 것입니다. 그러나 이는 더 강력한 프로세서, 더 많은 전력을 필요로 합니다. 이에 따라 모바일이나 스마트 디바이스, 센서 등에서는 기기 자체에서 연산을 수행하기 어려울뿐더러, 모델을 디바이스에 올리는 것에 성공한다고 해도 금방 배터리가 소진되고 맙니다.
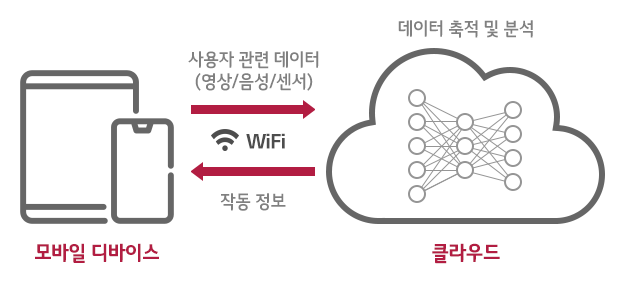
이러한 단점을 극복하기 위해 다양한 CSP(Cloud Service Provider)들은 클라우드 기반의 다양한 인공지능 서비스를 출시하고 있습니다. 큰 연산은 서버에서 수행하고 유저는 그 결과만을 받아보는 방식이지요. 그러나 이는 네트워크의 비용 및 상태에 따라 연산에 영향을 받을 수 있을 뿐 아니라, 민감한 개인 데이터를 서버에 올려야 하는 문제도 있습니다. 예를 들어, 내 사생활이 담긴 사진들을 자동으로 분류해 주는 모델은 분명 온 디바이스로 실행되어야 할 것입니다.
분명히 딥러닝 알고리즘은 더 빠르고 가벼워질 필요가 있으며, 이에 따라 크게 두 가지 갈래의 연구가 진행되고 있습니다. 첫 번째 갈래는 알고리즘 자체의 구조를 가볍게 디자인하는 경량 알고리즘 설계이고, 두 번째 갈래는 이미 설계된 알고리즘을 가볍게 만드는 알고리즘 경량화 방법입니다.
경량 알고리즘 설계
알고리즘 자체를 가볍게 디자인하는 경량 알고리즘 설계 기술은 기존 심층 신경망에 수학적인 방법을 활용해 더 적은 파라미터만으로 같은 양의 특징을 추출하는데 그 의의가 있습니다.
[모델 구조 및 필터 변경]
모델 구조 변경 방법은 초기 CNN의 연구 방향과도 일맥상통합니다. 이미지 데이터에서 거리가 먼 픽셀끼리는 서로 영향이 적을 것으로 가정해 근처에 모여있는 픽셀 정보만으로 필터를 구성해 특징을 추출하는 CNN의 방식은 FNN 대비 엄청난 양의 파라미터를 줄이는 것에 기여했습니다.
이미지 인공지능이 지금처럼 발전하는 토대가 되었습니다. 이후 필터 사이즈를 줄이는 VGGNet, 서로 다른 필터를 병렬로 처리하는 Inception 모듈, 학습을 더 쉽게 만드는 지름길을 내어주는 Residual 모듈을 거쳐 가며 점점 발전해 나아가고 있습니다.
[CNN 필터 변경]
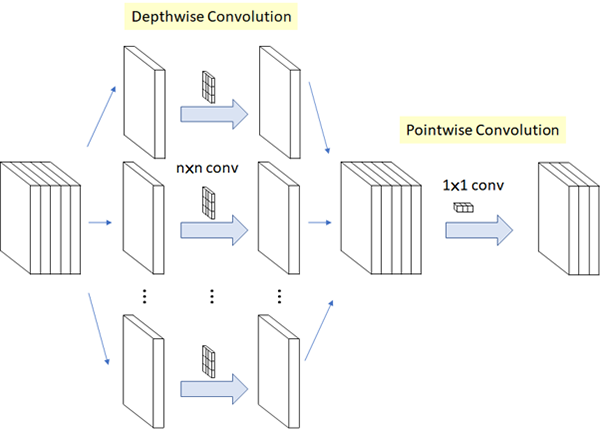
CNN 연산에서 가장 큰 계산량을 필요로 하는 CNN 필터의 연산을 효율적으로 줄이기 위한 연구로 채널 별(Depthwise)로 합성곱을 수행한 뒤 다시 점별(Pointwise)로 연산을 수행하도록 나누는 것이 핵심입니다. 대표적으로 MobileNet과 ShuffleNet이 있습니다.
[AutoML – 구조 탐색]
AutoML은 간단히 기계학습으로 설계하는 인공지능을 의미합니다.
구조 탐색(Architecture Searching)이란 심층 신경망의 구조 자체를 사람이 하나하나 설계하는 대신 학습을 통해 최적의 구조를 탐색해 학습하는 방법입니다.
유전 알고리즘이나 강화 학습을 이용한 연구들이 주류이며, 실행 속도를 명시적으로 포함해 정확도와 속도 간의 균형을 찾는 방식인 MNasNet, 이를 특정 태스크에 맞게 스케일링하도록 구조를 탐색하는 EfficientNet 등이 있습니다.
알고리즘 경량화
알고리즘 경량화는 신경망이 가지는 구조적 특성을 활용해 만들어진 모델의 다양한 파라미터를 줄여 압축하는 것에 그 목적이 있습니다.
[가지치기(Pruning)]
딥러닝 모델은 최종적으로 얼마나 많은 파라미터가 필요한지 알 수 없기 때문에 일반적으로 필요한 표현력에 비해 더 많은 파라미터를 부여해 학습시킵니다. 학습 후 파라미터의 상태를 확인하면 결과에 그다지 영향을 주지 않는 파라미터가 많이 존재한다는 것을 확인할 수 있습니다.
가지치기 방법은 심층 신경망의 파라미터에서 중요도가 떨어지는 값들을 모두 0으로 해 마치 가지를 치는 것 같이 모델의 크기를 줄이는 기술입니다.
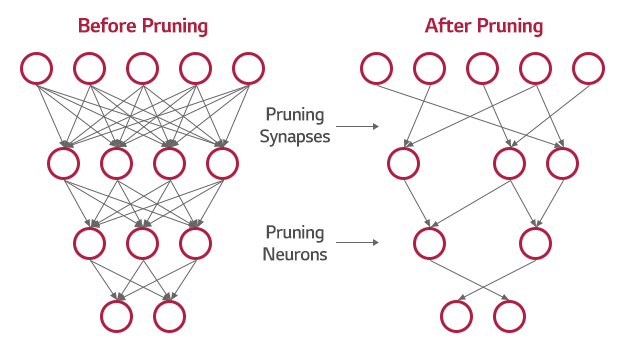
아무리 중요도가 떨어지는 값들이라도 결과적으로는 정확도에 손실을 줄 수 있는데, 이를 위해 추가적인 학습을 시도하기도 합니다.
[양자화(Quantization)]
심층 신경망을 학습 및 추론을 진행하면 32bit 부동 소수점 수준의 정밀도(Precision)가 필요하지 않은 경우가 많이 있습니다. 양자화는 파라미터의 정밀도를 적절히 줄여서 연산 효율성을 높입니다.
이 방법의 경우 하드웨어에서 지원이 필요한 경우가 대다수이므로, 수행 전 미리 하드웨어 스펙을 확인해보는 것이 좋습니다. 16bit 및 8bit Precision 연산의 경우 많은 경우 비교적 적은 정확도 손실로 고속 연산이 가능합니다. 4bit, 2bit, 1bit Precision 양자화에 대한 시도도 있는데, 이 경우 정확도 손실이 크기 때문에 학습부터 이를 최소화하는 방향의 연구도 함께 진행되고 있습니다.
[지식 증류(Knowledge Distilation)]
지식 증류는 이미 학습된 선생 모델(Teacher Network)의 파라미터 값을 활용해 새로운 학생 모델(Student Network)의 학습 시간을 줄이고 퍼포먼스 향상을 꾀하는 연구로, Teacher-Student Network로 불리기도 합니다.
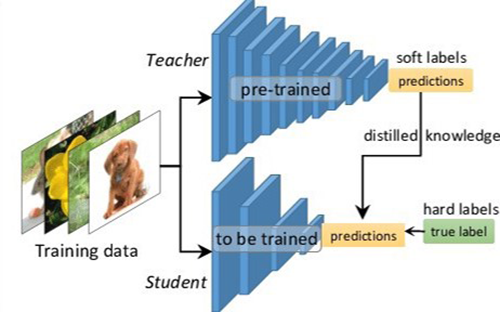
학습한 선생 모델의 지식(Knowledge)을 학생 모델에 전달하는 것을 증류(Distillation) 한다고 표현합니다. 선생 모델을 학습에 반영하는 방법은 다음과 같습니다. 선생 모델의 출력은 보통 특정 클래스에 대한 하나의 확률 값을 나타내는데, 이를 확률 값들의 분포 형태로 변환해 학생 모델 학습 시 두 신경망의 Loss를 동시에 반영합니다.
[AutoML – 모델 압축 탐색]
앞서 살펴본 AutoML의 모델 구조 탐색과 마찬가지로 태스크에 맞는 적절한 모델 압축 방법을 탐색하는 기법들이 다양하게 연구 중입니다. MobileNet에 하이퍼 파라미터 최적화를 통해 모델 압축 기법을 적용한 PocketFlow가 대표적입니다.
인공지능, 일상 속으로
인공지능 경량화 기술은 우리 삶의 다양한 분야에 이미 들어와 있습니다. 문장 번역 및 이미지 분류 서비스, 음악 태깅, 키보드 문자열 예측은 스마트폰을 통해 많이 접해본 인공지능입니다. 실시간 영상통화나 동영상 녹화 시 자연스럽게 얼굴을 보정해 주거나 동물 귀를 달아주곤 하는 인공지능 또한 익숙합니다.
헬스케어 분야의 인공지능은 온 디바이스 카메라를 통한 안과 질환 검증, 피부암 진단을 가능하게 하고 있습니다. 더 나아가 자율 주행 연구 분야에서는 딥러닝 기반 알고리즘을 통해 실시간으로 주변 물체를 인식해 더 나은 운행을 위해 활용하고 있습니다.

아직도 물리적, 비용적 제약으로 인해 실현되지 못한 다양한 인공지능 기술들이 있습니다. 그러나 하드웨어 기술이 발전하고 우리에게 필요한 인공지능 기술이 다양하게 연구되며, 인공지능은 조금씩 그러나 꾸준히 우리 일상 속으로 다가오고 있습니다.
글 l LG CNS AI빅데이터연구소
참고 자료
<논문>
- Very Deep Convolutional Networks for Large-Scale Image Recognition (https://arxiv.org/abs/1409.1556)
- Going Deeper with Convolutions (https://arxiv.org/abs/1409.4842)
- Deep Residual Learning for Image Recognition (https://arxiv.org/abs/1512.03385)
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications (https://arxiv.org/abs/1704.04861)
- ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices (https://arxiv.org/abs/1707.01083)
- MnasNet: Platform-Aware Neural Architecture Search for Mobile (https://arxiv.org/abs/1807.11626)
- EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (https://arxiv.org/abs/1905.11946)
- Distilling the Knowledge in a Neural Network (https://arxiv.org/abs/1503.02531)
- AMC: AutoML for Model Compression and Acceleration on Mobile Devices (https://arxiv.org/abs/1802.03494)
- PocketFlow: An Automated Framework for Compressing and Accelerating Deep Neural Networks (https://openreview.net/forum?id=H1fWoYhdim)
- 경량 딥러닝 기술 동향 Recent R&D Trends for Lightweight Deep Learning (http://dx.doi.org/10.22648/ETRI.2019.J.340205)
<사이트>
- 구글 한국 블로그 – https://korea.googleblog.com/2017/05/google-cloud-offer-tpus-machine-learning.html
- Review: Xception – (https://towardsdatascience.com/review-xception-with-depthwise-separable-convolution-better-than-inception-v3-image-dc967dd42568)
- Neural Network Distiller – https://nervanasystems.github.io/distiller/knowledge_distillation.html
- Knowledge Distillation: Simplified – https://towardsdatascience.com/knowledge-distillation-simplified-dd4973dbc764


