안녕하세요. 오늘은 빅데이터를 활용한 다양한 사례들을 소개해드리려고 합니다.

올해 아카데미 시상식에서는 봉준호 감독의 ‘기생충’이 4관왕을 차지해, 국민들에게 큰 기쁨을 주었죠? 그런데 봉준호 감독만큼이나 화제가 된 의외의 인물이 한 명 있었어요. 바로 봉준호 감독의 통역을 맡은 ‘샤론 최’인데요. 그녀의 완벽한 통역과 영어 실력은 시상식이 끝난 뒤에도 오랫동안 회자 되었죠.
샤론 최를 보면서 부러운 마음이 가득했다가, ‘어떻게 저렇게 영어를 잘하게 되었을까?’ 하는 궁금증이 생겼다가, 마지막에는 ‘왜 기술이 이렇게 발전했는데, 아직도 완벽한 동시통역 기계는 나오지 않는 거야!’라는 생각까지 들었습니다.

사실 번역 서비스는 꾸준히 발전해 오고 있었는데요. 대표적인 기계 번역 서비스인 구글 번역(Google Translate)은 2006년 시작된 이래로, 100개가 넘는 언어를 다양한 수준에서 지원하며, 날마다 5억 명 이상의 요청을 처리하고 있습니다. 또한, 구글 번역은 웹페이지를 통째로 번역해, 장대한 웹페이지도 원하는 언어로 바꿔 주고 있죠.

하지만 아직 번역의 수준이 만족스럽지 않은 경우가 있는데요.
“옛날에, 백조 한마리가 살았습니다.”라는 문장을 한국어 ▶ 영어로 번역해 보겠습니다.
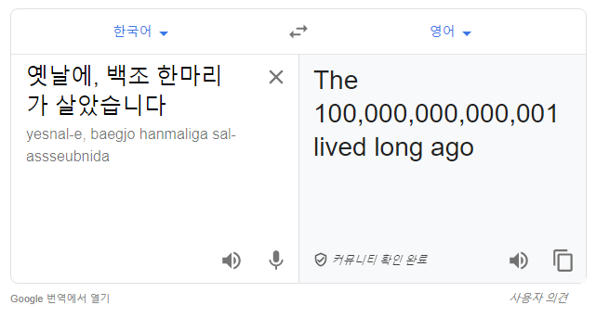
동물 ‘백조(白鳥)’를 숫자 ‘백조(百兆)’로 해석해 버렸네요. 같은 문장을 한국어 ▶ 일본어로 번역해 보겠습니다.
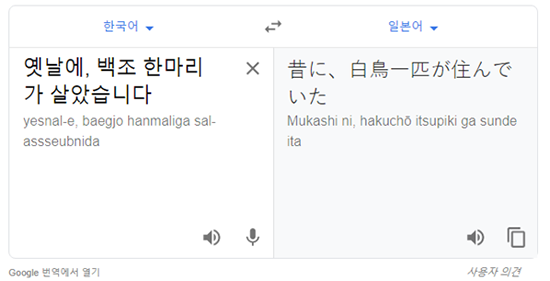
일본어의 번역 결과를 가지고, 바로 일본어 ▶ 영어로 번역해 보겠습니다.
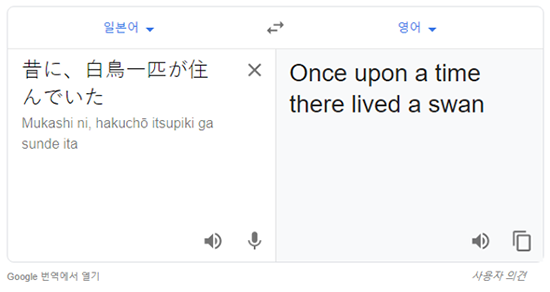
이번에는 ’백조’가 ‘swan’으로 잘 번역이 되었네요!
왜 일본어를 통해서 번역하면 그 내용이 더 자연스러울까요?
이는 구글 언어 번역 데이터베이스에 일본어와 영어 사이의 데이터가 훨씬 많기 때문입니다. 일본어는 동인지 등 문화 폭탄의 산물들을 번역하는 과정에서 수많은 사람에게 교정이 되어, 그 데이터가 압도적으로 많이 쌓였다고 하네요.
2016년 구글은 번역을 구글 신경 기계 번역(GNMT)으로 전환한다고 발표했습니다. 가장 적절한 번역을 찾아내기 위해 단어 조각 단위가 아니라, 더 넓은 문맥을 사용한 후, 이를 재정렬해 적절한 문법으로 인간이 구사하는 것과 같이 해석해 주는 것이죠.
이러한 딥러닝 기술이 제대로 적용되기 위해서는 한국어-외국어 관련 빅데이터가 많이 쌓이는 것이 필수 조건이겠죠? 모국어를 배우는 어린아이와 같이, 인공지능은 아무것도 없는 상태에서 데이터를 모으고 학습하고, 심지어 쉼 없이 계속 학습하죠. 이 세상의 그 누구보다도 인터넷 검색 엔진은 많은 언어를 보유하고 있을 것입니다.
언젠가는 외국어 공부를 하지 않아도 되고, 통 번역가가 필요 없는 시대가 오길 기대해 봅니다.

우리나라에서 빅데이터를 공공서비스 개선에 성공적으로 활용한 케이스를 알아보도록 하겠습니다.
서울은 밤이 되어도 불이 꺼지지 않는 도시입니다. 늦은 밤에 집으로 돌아가기 위해서는 대중교통을 이용해야 하는데요. 하지만 버스, 지하철은 막차 시간이 있고, 택시는 승차 거부 등 여러 가지 문제로 충분한 대안이 되지 못하고 있었죠.
그래서 서울시에서는 저렴한 비용으로 시민이 필요로 하는 심야시간대에 버스 서비스를 제공하기로 했습니다. 일명 ‘올빼미버스’인데요.

이 버스 노선을 설계하는 과정에서, 이용자 관점에서 수요를 반영하고 실제 행동 패턴을 이해하기 위해서 빅데이터를 활용했다고 합니다. 늦은 시간까지 돌아다니는 사람이 아무리 많다고 해도, 주중의 버스 승객수와는 비교할 수 없을 정도로 그 수가 적기 때문에, 수익성을 높이기 위해서는 철저한 데이터 분석이 필요했던 거죠.
늦은 시간 귀가를 할 때 집에 전화를 걸어서 ‘이제 출발해’라고 말한 적이 있으신가요? 집에서 기다리는 가족에게 전화를 걸거나, 메시지를 보내고 출발한 경험이 있으실 텐데요.
그런 경험에 힌트를 얻어 자정부터 오전 5시까지 서울 시내에서 발생한 통신 데이터와 택시 스마트카드 데이터를 분석했다고 하네요. 통화 위치정보를 ‘출발지 데이터’로 청구지 주소정보를 ‘목적지 데이터’로 가공한 것이죠.
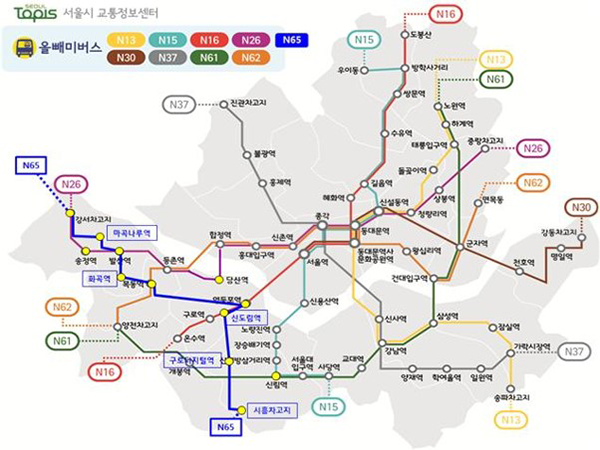
그 이전까지 버스 노선은 어떻게 설계가 되었을까요? 사용자 중심이라기보다 버스 회사의 편의에 맞게 노선이 결정되었을 텐데요.
올빼미버스는 빅데이터를 활용해서 수요자 중심의 공공 정책을 설계했다는 점에서 큰 의의가 있고, 또한 적은 비용으로 시민의 불편함을 눈에 띄게 해소해 매우 실용적인 사례로 꼽히고 있습니다.

지난 글에서 빅데이터의 개념을 소개해드리면서 유튜브의 추천 알고리즘에 대해 잠깐 말씀드렸었는데요.
코로나19등의 영향으로 집콕이 늘어나면서 온라인으로 동영상 스트리밍 서비스를 하는 ‘넷플릭스’ 의 인기도 더욱 높아졌습니다. 전 세계 구독자 수가 1억 명을 넘었는데요. 모건스탠리는 2028년에는 3억 명을 넘을 것으로 예상했다고 합니다.
‘넷플릭스’라는 이름이 인터넷(NET)과 영화(flicks)에서 따온 것처럼, 인터넷으로 영화를 보는 서비스를 말하는데요. 대표적인 OTT(Over The Top, 셋톱박스를 넘어서는) 서비스로, 기존 지상파 방송과 케이블 TV의 역할을 대체하며 무섭게 성장하고 있습니다. 넷플릭스의 성공 요인 중 하나가 정교한 추천 알고리즘인데요. 여기에도 역시 빅데이터가 사용되었습니다.

넷플릭스는 이용자들이 스트리밍 콘텐츠를 언제 재생하고, 언제 멈추는지, 뒤로 혹은 앞으로 돌려보는지, 에피소드 하나를 본 후 다음 에피소드를 보는 데 얼마나 걸리는지 등의 모든 사용자 동작 정보를 수집하고, 콘텐츠 관련 모든 정보 (줄거리, 배우, 감독, 영상의 색감이나 음량, 엔딩 크레딧 정보까지)를 여기에 결합해 엄청난 개인별 맞춤형 데이터를 만들어내는데요.
이용자들이 넷플릭스를 계속 보게 하려면, 보고 싶어 할 프로그램을 추천하는 추천 알고리즘이 필수적이기 때문이죠. 실제로 시청자 행동(View Activities)의 약 75%가 넷플릭스의 추천에 기반하고 있다고 하네요.
그리고 넷플릭스의 이러한 추천 시스템은 평점보다는 실제 시청자들이 시청한 데이터에 기반하고 있는데요. 시청자들은 의미가 있고 진지한 영화에 4~5점으로 점수를 주지만, 실제로 퇴근 후에는 평점이 높은 다큐멘터리 영화보다는, 2~3점짜리 바보 같은 코미디 영화를 더 많이 본다는 데이터를 기반으로 추천을 하는 것이죠.

또한 넷플릭스는 빅데이터를 활용해 직접 콘텐츠를 제작하기까지 했는데요. 이것을 오리지널 콘텐츠라고 하며, 시청자 선호도를 파악해서 연출 스타일, 배우, 기획, 배급까지 선정하기도 했습니다.
넷플릭스가 ‘하우스 오브 카드’라는 드라마를 직접 제작하기 전에 이미 넷플릭스는, ‘하우스 오브 카드 BBC 영국 원작이 인기가 많았고’, ‘BBC 드라마를 좋아하는 회원들은 케빈 스페이시가 주연한 드라마와 데이비드 핀처 감독을 검색해서 보고’, ‘데이비드 핀쳐 감독의 ‘소셜 네트워크’ 영화를 본 사람들은 중간에 멈추지 않았다’ 는 등의 사실들을 알고 있었죠. 빅데이터가 바로 프로듀서가 된 셈이죠.
‘넷플릭스는 오늘 밤 당신이 뭘 볼지 알고 있다’, ‘넷플릭스가 나보다 내 영화 취향을 더 잘 안다’라는 말이 괜히 나온 말은 아닌 것 같네요.
패션 마켓도 한번 알아볼까요?
스페인 브랜드 ‘ZARA(자라)’는 몇 년 전까지는 해외 직구만 구매 가능했지만, 이제는 우리나라에도 입점해서 인기를 끌고 있죠. 다른 경쟁업체들이 광고비에 엄청난 비용을 지출하는 것과 달리, 자라는 광고에 큰 비용을 지출하지 않습니다. 정기 세일 기간을 제외하고는 별다른 세일 행사도 하지도 않습니다. 하지만 스페인에서 자라의 고객은 평균 일 년에 17번이나 매장을 방문한다고 합니다.

자라가 탄탄한 고객층을 보유한 경쟁력 있는 브랜드가 된 배경에도 빅데이터가 있습니다.
자라는 연간 4억 5천만 개의 제품을 생산하고, 스타일 수는 1만여 개에 달합니다. 이렇게 많은 제품을 효율적으로 생산하고 관리하기 위해, 자라는 모든 옷에 RFID(Radio Frequency Identification) 태그를 부착해 소비자 선호도와 재고 등을 파악합니다.
SNS나 설문을 통해 고객들의 패션 센서빌리티에 대한 데이터를 수집하고 있죠. 데이터 분석 전문가들이 모든 데이터를 일별로 분석해 시장의 변화에 즉각적으로 대응해 새로운 디자인을 출시하고, 매장으로 2 주 안에 제품을 배송시킨다고 합니다.

자라는 이처럼 데이터를 바탕으로 소비자의 니즈를 실시간으로 파악하기 때문에 효율적으로 생산하고 재고를 줄여, 궁극적으로는 기업의 매출 증대를 가져왔고 세계적인 의류 브랜드로 성장할 수 있었다고 합니다.

다양한 산업 분야에서 빅데이터는 기업의 경쟁력을 넘어서, 생존에 필수 불가결한 요소가 된 것 같네요.
빅데이터는 이제 특정한 산업이나 기술을 다루는 사람만 알아야 하는 신기술이 아닙니다. 누구나 자신이 하는 일에 전문성을 더하기 위해 데이터를 분석하고 해석하는 연습이 필요합니다. 그러나 이 말이 빅데이터 전문가 수준으로 통계 시스템을 학습한다든지 데이터 분석 언어를 이해해야 한다는 말은 아닙니다.
나의 업무에서 문제를 파악하고 의사결정을 내릴 때, 기존에는 경험과 직관에만 매달렸다면, 이제는 데이터를 활용하는 것이 나의 경쟁력에 도움이 되니, 데이터에 대한 이해가 꼭 필요하다는 말이죠.
그런 의미에서 다음에는 데이터를 이해해보고 해석해보는 연습에 대해 소개해드리겠습니다.
글 l LG CNS 대외협력팀


