
인공지능을 개발하는 스타트업인 오픈에이아이(OpenAI)가 올해 초 ‘달리2(DALL-E 2)’라는 인공지능 엔진을 선보였습니다. 달리2는 텍스트로 지시어를 입력하는 것만으로 고품질 이미지를 생성해 주는 인공지능 엔진인데요. 단순한 사물의 고유명사뿐 아니라 동작이나 주제어 등을 입력하면 그 단어에 맞는 그림을 생성할 수 있습니다.

인공지능 달리1 “글자를 입력하면 그림이 그려져요”
달리를 만든 OpenAI의 CEO 샘 알트만은 달리를 만드는 과정에 대해 “지금까지 만든 것 중에서 가장 즐거웠고, 오랜만에 기술에서 느껴보지 못한 재미가 있었다”라고 말했습니다. 이번에 나온 달리2의 뿌리는 작년에 만들어진 달리1인데요. 달리1은 다양한 분야에서 사용할 수 있는 것이 특징입니다.
예를 들어 캐릭터 그림을 그리고 싶다면 검색창에 ‘강아지를 산책시키는 아기 무’를 검색하면 되는데요. 해당 글자를 입력하는 것만으로도 캐릭터를 그림이 생성됩니다. 산업 디자인 분야에서도 달리를 활용할 수 있는데요. ‘아보카도 모양의 의자’를 입력하면 아래 그림처럼 매우 다양한 모양의 아보카도 그림을 볼 수 있습니다. 또한 ‘검은 가죽 재킷과 금색 스커트’를 입력하면 다양한 패션 디자인을 그려냅니다.

또, 달리는 이미지가 마음에 들지 않을 경우 편집도 할 수 있습니다. 예를 들어 ‘물속에서 트럼펫을 연주하는 테디 베어’라고 입력하면 해당 내용을 담은 그림이 생성되는데요. 만약 그림 속에 그려진 트럼펫이 마음에 들지 않을 때, ‘물속에서 기타를 연주하는 테디 베어’를 입력하기만 하면 이미지가 곧바로 수정됩니다.
인공지능 달리2, 인공지능이 예술 작품을 그린다
올해 1월 론칭해 4월에 본격적으로 공개된 달리2는 달리1과 비교해 한 차원 더 업그레이드됐습니다. 달리1이 ‘어디서 본 것 같은 그림’을 그렸다면, 달리2는 매우 독창적이고 예술작품 같은 그림을 그리는 것이 그 특징인데요. 예를 들어 ‘우주 비행사가 말을 타고 달을 달리고 있다’를 입력하면 아래와 같은 그림이 생성됩니다.

달리2는 캡션을 보다 정교하게 입력할 수 있는데요. 오브젝트를 넣을 위치를 글로 입력하면 해당 오브젝트의 위치까지 바뀐다고 합니다. 또한 빛과 그림자, 질감도 문자로 입력해 수정할 수 있는데요. 뿐만 아니라 이미지 원본에서 영감을 받아 새로운 그림을 그릴 수 있습니다.
이는 앞서 소개한 이미지를 보면 잘 알 수 있는데요. 요하네스 페르메이르의 <진주 귀고리를 한 소녀>라는 17세기 예술품을 학습해서 다양한 유사 이미지를 생성한 것입니다. 가장 왼쪽에 있는 그림이 진품이고, 나머지는 달리2가 그려낸 그림입니다.
달리1가 출시된 지 1년 만에 나온 달리2가 훨씬 발전한 이유는 사람들이 집어넣은 텍스트와 결과 값인 이미지를 인공지능이 학습했기 때문입니다. 예를 들어 ‘모자를 쓰고 타이핑을 하는 원숭이’를 입력했다고 가정해보겠습니다. 인공지능은 원숭이 그림을 먼저 불러오고 뒤이어 모자가 위치할 원숭이 머리 윗부분을 지운 다음 그 위치에 모자를 그려 넣습니다. 이후 원숭이 손 앞에 있는 배경을 지우고, 다시 해당 위치에 노트북 이미지를 가져다 놓는 프로세스로 작동합니다.
OpenAI에 따르면 달리2는 달리1과 비교해 4배나 더 높은 해상도로 작업을 할 수 있다고 합니다. 달리2의 그림이 얼마나 더 사실적인지 평가하고자 비전문가를 대상으로 달리1과 달리2가 그린 그림을 비교해달라고 요청했을 때, 88.8%가 달리2가 더 사실적이라고 답했습니다.
달리2가 그림을 그리는 방식 Diffusion과 Clip
달리2가 이처럼 다양한 그림을 그릴 수 있는 이유는 디퓨전(Diffusion)모델을 사용했기 때문입니다. 디퓨전 모델은 아래와 같은 절차를 거치는데요. 먼저, 프롬프트를 표현 공간에 매핑할 수 있도록 훈련된 텍스트 인코더에 텍스트 프롬프트가 입력됩니다. 그 다음 프라이어(Prior) 모델은 텍스트 인코딩에 포함된 프롬프트 의미 정보를 캡쳐 하는 이미지 인코딩에 텍스트 인코딩을 매핑하는데요. 마지막 단계에서 이미지 디코딩 모델이 의미 정보의 시각적 표현인 이미지를 확률적으로 생성합니다. 이는 달리2가 그림을 그리는 프로세스입니다.
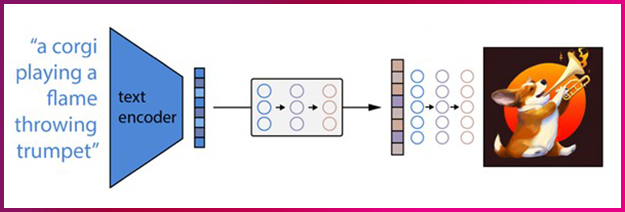
달리2에는 클립(CLIP, Contrastive Language Image Prtraining)이라는 모델도 활용이 됩니다. 예를 들어 달리2에 ‘타임스퀘어에서 스케이트보드를 탄 테디 베어’라는 텍스트를 입력한다고 가정해 봅시다. 이때 모든 이미지와 관련 캡션이 각각의 인코더를 통해 전달되고 모든 개체를 공간에 매핑하는데요. 그런 다음 각 이미지와 텍스트의 코사인 유사도가 계산됩니다. 인공지능이 학습을 통해 올바르게 인코딩 된 이미지와 캡션 쌍 간의 코사인 유사성을 동시에 최적화하는데요. 반대로 클립 모델은 잘못된 쌍의 코사인 유사성을 최소화합니다. 그리고 이를 통해 보다 정확한 그림을 그릴 수 있습니다.
의료 교육 패션에 스며드는 인공지능 이미지 기술
달리2는 아직 상업적 용도로 쓰이지는 않고 있지만, 다른 이미지 인공지능들이 우리의 삶에 스며든 것처럼 달리2도 곧 그렇게 될 수 있을 것 같습니다. OpenAI는 “우리의 희망은 달리2가 사람들이 자신을 창의적으로 표현할 수 있도록 돕는 것”이라고 했는데요. 인류에게 도움이 되는 인공지능이 그들의 사명이라는 것이죠. 올해 들어 주목받고 있는 달리2의 몇몇 사례들을 조금 더 살펴보겠습니다.
인공지능 이미지 기술들은 이미지의 누락된 부분을 복원하거나 질 낮은 이미지를 업스케일링하여 초고해상도 이미지로 변경이 가능합니다. 또, 노이즈를 제거할 수 있는데요. 이러한 특징 덕분에 인공지능 이미지 기술은 특히 의료 분야에서 주목받고 있습니다. 예를 들어 MRI 품질을 높이려면 방사선 양을 높여야 하는데, 이는 몸에 해롭습니다. 이때 생산적 적대 신경망(GAN)을 활용해 해상도를 높이는 것이 가능한데요. 다만 현재 수준에서는 인공지능이 인위적으로 이미지를 생성할 수도 있어서 조심스럽게 연구하고 있는 단계라고 합니다.
한편 미국의 스타트업 로즈버드AI(rosebud.ai)는 가상의 패션 모델을 만들어주는 인공지능을 선보였는데요. 공을 들여 촬영을 했지만 패션 모델 이미지가 이상하다고 느끼면 인공지능 이미지 기술을 활용해 사진을 수정할 수 있습니다. 또, 로즈버드AI는 토킹헤드라는 앱을 내놓았는데요. 토킹헤드는 이미지뿐 아니라 애니메이션에도 적용할 수 있는 기술입니다.
NFT 누구나 만들어 팔 수 있다
달리2가 상당한 잠재력을 갖고 있는 것은 사실이지만 우려의 시선이 아예 없는 것은 아닙니다. 누군가 유해한 그림 혹은 편견이 들어간 그림을 그릴 수 있다는 지적을 받는데요. 그래서 현재 OpenAI는 달리를 사용할 수 있는 인원을 총 400명으로 제한했습니다. 당장 사용자를 확장하기보다는 조금 더 연구를 하겠다는 것입니다.
또, 달리의 기술이 아직은 100% 정확한 것은 아니라고 하는데요. 예컨대 ‘달 위에 있는 에펠탑’을 입력하면, 에펠탑이 아닌 일반적인 탑 위에 달을 그리는 실수를 하기도 합니다.

하지만 인류는 항상 이러한 염려를 덜어내고 기술을 싹 틔워 왔습니다. 이미지 생성 기술이 어떻게 꽃을 피울지는 모르지만, 오늘날 인공지능이 확산되는 속도를 보면 분명 몇 년 후에는 이러한 이미지 생성 인공지능이 널리 퍼져 있을지도 모릅니다. 미래에 이러한 인공지능 이미지 생성 기술들이 검색 엔진을 개선하고 디지털 비서로 활동하며, 더 나아가 그래픽 아티스트의 역할을 할 것이 분명해 보입니다.
글 | 이상덕 | 매일경제 실리콘밸리 특파원


