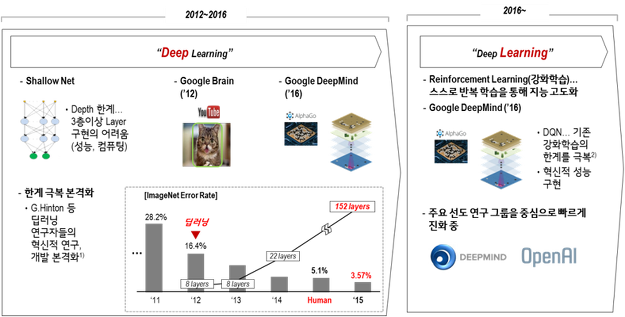
2012년을 시작으로 본격화된 딥러닝의 발전은, 2016년을 기점으로 전환점을 맞이했습니다. 딥러닝의 가장 큰 한계였던 깊이(Depth)1의 문제가 해결되며 시각•청각 지능에 대해서는 Human-level 혹은 그 이상의 인공지능이 구현되고 있는데요.

과거 인공 신경망 구현에 있어 알고리즘, 컴퓨팅, 데이터의 한계로 인해 얕은 신경망(Shallow Net)에 그쳤던 딥러닝이 이제는 깊이(Depth)의 한계를 극복했다고 말할 수 있습니다. 알파고의 출현을 시작으로, 2016년 초까지 진행되었던 딥러닝의 깊이(Deep) 경쟁은 이제 학습(Learning)의 경쟁으로 전환되고 있습니다.
강화학습 기반의 인공지능 학습 과정은 과거의 방식과 전혀 다릅니다. 기존 기계학습 기반의 인공지능은 목표 달성 과정을 인간(전문가)이 일일이 모델링하고 구현해야 했습니다. 또한 환경, 목표가 달라지면, 모델을 매번 변경하거나 모델을 전혀 새롭게 설계해야 했는데요. 하지만 강화학습 방법은 인공지능이 스스로 현재의 환경을 인식하고 행동하며 목표를 달성해 나갈 수 있습니다.
게다가 이러한 방식은 범용적으로 활용 가능해, 새로운 환경에서 학습만 반복하게 되면 하나의 알고리즘을 가지고 매우 다양한 환경에 적용 가능한 인공지능을 구현해 낼 수 있는데요.
구글은 이러한 강화학습의 폭발적인 잠재력을 매우 빨리 인지하고, 2014년에 딥마인드를 약 4,500억 원에 인수했습니다. 당시만 해도 딥마인드가 보유한 핵심 기술은 인공지능이 반복 학습을 통해 주어진 목적을 달성하는 방법을 스스로 깨우치게 하는 강화학습 알고리즘이 전부였는데요. 이후 딥마인드는 더욱 고도화된 강화학습 알고리즘을 통해 1년 만에 알파고를(AlphaGo)를 구현해냈습니다.
물론 기본적인 이론들은 매우 오래전부터 제안됐었지만, 딥마인드는 그것을 실제 구현해 내고 인간 수준 혹은 그 이상의 성능으로 검증해냈습니다. 강화학습에 딥러닝을 접목한 ‘Deep Reinforcement Learning’2을 개발하면서 게임 환경에서 인공지능을 먼저 구현한 것입니다.
이 알고리즘은 인공지능이 처한 환경에서 달성하고자 하는 목표와 각 과정에 보상(Reward) 값만 정해지게 되면, 인공지능이 스스로 보상을 최대로 받으며 목표를 달성하는 방법을 깨우칩니다. 딥마인드가 초기 강화학습 구현하며 검증을 위해 공개한 영상3에서는 학습 초기 과정에서는 게임을 전혀 진행하지 못하지만, 수 시간에 걸친 시행착오를 통해 인간 수준 이상으로 게임을 능숙하게 진행하는 것을 볼 수 있습니다.
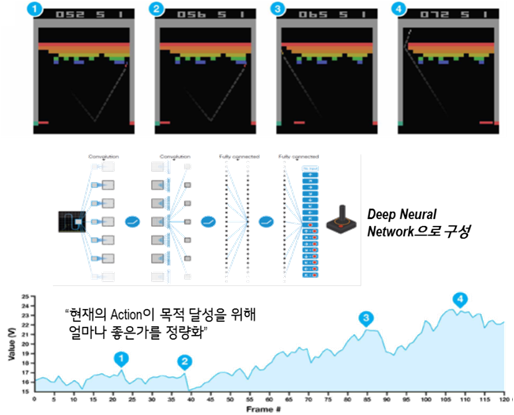
아래의 그림처럼, 매 순간 인공지능은 자신이 처한 환경과 행동 가능한 옵션들을 인지하고 각 행동에 대해 정량화된 보상 값을 최고로 달성할 수 있는 행동을 반복적으로 선택하며 최종 목적을 달성해 나갑니다. 알파고의 경우도 수를 둘 때마다 다양한 착점 중 가장 승률이 높을 것으로 계산된 수를 선택하며 바둑을 진행하는 것이며, 매일 128만 번4에 이르는 반복 학습을 통해 바둑을 두는 과정을 깨우쳐 나간 것입니다.
알파고를 시작으로 강화학습에 대한 연구가 활발히 진행되며, 2016년 이후 빠르게 발전하고 있습니다. 이를 가능하게 한데에는 딥마인드, OpenAI와 같은 선행 연구 기관들이 공개한 오픈소스의 역할이 컸습니다. 인공지능 연구자들은 자신들이 개발한 강화학습 알고리즘을 실험하고 검증하기 위한 환경이 필요한데요. 알고리즘 검증을 위해 매번 게임 자체를 개발할 수는 없기 때문입니다. 이러한 어려움을 해결하기 위해 OpenAI는 자신들의 연구결과물을 모두 공개하고 있습니다.
OpenAI는 약 200개 이상의 게임 환경을 오픈소스로 공개 하고 있습니다. Tensorflow, Theano등과 같이 인공지능 구현에 주로 사용되는 개발 환경과 연동되기 때문에, 강화학습 개발자와 연구자들은 단 몇 줄의 코드만 사용하면 다양한 환경에서 자신의 알고리즘을 테스트 하는 것이 가능해졌습니다.
연구자들이 자신이 구현한 인공지능을 동일한 환경에서 성능을 검증하고 경쟁하는 것이 가능해진 것입니다. 이러한 경쟁의 결과로 강화학습 분야의 연구 논문은 매우 빠르게 발표되고 있습니다.

하루가 다르게 진화하고 있는 강화학습 분야의 연구는 이제 현실 세계의 문제해결을 위해 한 단계 더 발전해가고 있습니다. 단순한 2차원 공간을 넘어 3차원 공간에서 문제를 해결하거나, 로봇과 같이 다수의 기계 부품들이 물리적 조합으로 구동되는 환경에서 강화학습을 적용하려는 시도들이 최근 잇따르고 있습니다.
아직은 Google, UC Berkeley, MIT Robotics 등 소수의 선행 연구소들을 중심으로 강화학습에 대한 연구가 이루어 지고 있지만, 향후 빠르게 발전되어 현실 세계의 문제에 적용 시 인공지능이 인간의 능력을 초월하는 수준으로 구현되는 시기가 매우 앞당겨질 것으로 전망됩니다.
글 | 이승훈 책임연구원(shlee@lgeri.com) | LG경제연구원
- 인공신경망 구조의 층(Layer)의 개수 [본문으로]
- V. Minih, et al. Playing Atari with Deep Reinforcement Learning, NIPS 2013, V. Minih, et al, Human-level control through deep reinforcement learning, Nature 2015 [본문으로]
- https://www.youtube.com/watch?v=V1eYniJ0Rnk [본문으로]
- 16만개의 기보, 3000만개의 착점 정보, 128만번/1일 [본문으로]


