안녕하세요. 미디어 아티스트 송준봉입니다.
지난 시간에는 빛(Light) 활용한 다양한 미디어 작업을 소개해 드렸는데요. ‘예술과 IT’ 9번째 시간에는 인공지능(AI), 구체적으로는 머신 러닝(Machine Learning) 기술을 활용한 미디어 작업을 소개해 드리려고 합니다.
머신 러닝은 요즘 워낙 다양한 분야에서 이슈가 되고 있는 기술이기도 해서 많은 분이 관심을 가지고 계실 것 같은데요. 인공지능이 미디어 아트 분야에는 어떻게 적용되고 있는지 함께 살펴보도록 하겠습니다.
컴퓨터가 그린 그림
지금 이 문단의 제목을 보고 ‘전에 한 번 썼던 제목 아닌가?’ 라고 생각하시는 분이 계신다면 정말 눈물이 날 만큼 기쁠 것 같습니다. 바로 ‘예술과 IT’ 연재 기획의 첫 번째 주제였죠.
● 예술과 IT – 컴퓨터가 그린 그림
http://blog.lgcns.com/1111
머신 러닝을 통해 ‘렘브란트’ 풍의 그림을 그리는 넥스트 렘브란트 프로젝트1와 꿈속에서 본 것 같은 이미지를 만들어내는 Deep Dream Project2등을 소개해드렸었습니다.

(출처: https://www.nextrembrandt.com(좌), http://deepdreamgenerator.com(우)
연재를 시작하지도 벌써 9개월이 되었는데요. 짧다면 짧다고 할 수 있는 기간이지만, 그동안 머신 러닝 연구 분야는 정말 눈부신 발전을 이루었습니다. 사실 ‘발전했다’는 말보다는 ‘퍼졌다’는 말이 더 맞을지도 모르겠습니다. 이러한 ‘퍼짐’의 중심에는 tensorflow3를 비롯한 몇몇 머신 러닝 라이브러리의 대중화가 있었다고 생각합니다.
대부분의 머신 러닝 라이브러리의 오픈 소스 정책 시행과 함께, 수많은 개발자가 일반인들도 조금만 공부하면 머신 러닝 라이브러리를 사용할 수 있도록 만들어 준 것이죠. 미디어 아트 분야에서도 예외는 아니었고, 최근 머신 러닝을 활용한 다양한 작업이 쏟아져 나오고 있습니다.
예를 들면, 이전 연재 내용 중 주어진 이미지를 고흐 풍으로 바꾸어 표현하는 머신 러닝 관련 논문4을 소개해 드린 바 있는데요. 소프트웨어 엔지니어인 유스케 토마토(Yusuke Tomato)는 해당 논문을 토대로 이미지를 명화 풍으로 변환하는 라이브러리를 오픈 소스로 공개했습니다.
● 유스케 토마토의 오픈소스 라이브러리
https://github.com/yusuketomoto/chainer-fast-neuralstyle
이제 누군가가 특정 작가의 그림 이미지를 프로그램에 업로드하는 것만으로 컴퓨터를 화가로 만드는 것은 놀랍지 않은 일이 되었습니다.

(출처: https://github.com/yusuketomoto/chainer-fast-neuralstyle)
프로그래머이자 예술가인 진 코건(gene kogan5)은 작품을 큐비스트 미러(Cubist Mirror)와 칸딘스키 미러(Kandinsky Mirro) 라는 작업으로 만들었습니다. 웹캠이 설치된 디스플레이 앞에 서면 실시간으로 나의 모습을 큐비니즘 또는 칸딘스키 풍의 그림으로 그려서 보여주게 됩니다. 이 작업은 작년 서울에서 전시되기도 했는데, 관객들이 사진 찍기에 여념이 없을 정도로 큰 인기를 끌었습니다.

(출처: http://genekogan.com(좌))
놀라운 것은 이 모든 과정이 아주 짧은 기간 안에 이루어졌다는 것입니다. 2015년 논문이 발표된 이후 2016년 초 오픈 소스 라이브러리를 공개하고, 2016년 중반 미디어 작업이 이루어질 때까지 약 1년이 조금 넘은 기간밖에 걸리지 않았습니다.
인공지능 머신 러닝, 연구인가? Art 인가?
인공지능(머신 러닝) 분야에서 연구가 아트(Art)로 전이되어버리는 일이 자주 일어나게 되다 보니, 연구인지 아트인지 구분이 되지 않는 경우도 많습니다. 개인적으로는 Google I/O 2016의 한 발표 꼭지였던 Machine learning & Art 발표 영상을 보고 느낀 바가 컸습니다.
● Google I/O 2016 ‘Machine Learning & Art’ 발표 영상
https://www.youtube.com/watch?v=egk683bKJYU
발표에서 나왔던 몇 가지 재미있는 내용을 소개해 드리겠습니다. 먼저 보실 작품은 ‘Ernst’라 불리는 콜라주 메이킹 프로그램입니다. 이 프로그램은 이름부터 콜라주로 유명한 초현실주의 작가 막스 에른스트(Max Ernst)를 추종하고 있습니다. 주어진 이미지 데이터들을 가지고 에른스트 풍의 콜라주 작업을 만들어내는 프로그램입니다.
머신 러닝을 사용하지 않고 이미지들을 랜덤하게 콜라주 형태로 만드는 알고리즘을 구현했을 가능성이 보입니다만, 그 방법과 관계없이 결과물은 세련되고 훌륭하다는 생각이 들었습니다. 발표자는 작업 과정에 콜라주로 사용될 기본 이미지를 사람이 직접 넣어야 하는 한계가 존재했고, 이미지의 수집부터 기계(Machine)에 맡기면 어떨까 생각했다고 합니다. 아직도 만족스럽지 않다는 얘기인데 무섭네요.
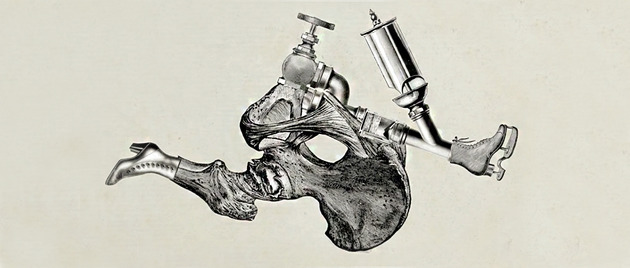
(출처: https://www.youtube.com/watch?v=egk683bKJYU)
최근 미국이나 유럽 대부분의 미술관에서는 모든 그림의 고화질 이미지를 데이터베이스화하고 있습니다. 구글은 이 데이터베이스에 주목하였습니다. 그리고 이들을 분류(classifying)하는 데 머신 러닝, 좀 더 정확히는 비교사 학습(Unsupervised Learning)을 적용했는데요. 쉽게 말하면 머신이 알아서 비슷한 그림들끼리 분류해 주는 것이었습니다.
그 결과, 수많은 그림을 집단화(clustering)할 수 있게 되었습니다. ‘분류’라는 게 ‘그렇게 대단한 것인가?’라고 생각할 수도 있겠지만, 컴퓨터가 ‘이유는 알 수 없지만, 이 그림들은 비슷한 것 같아’라고 했을 때 누군가가 “이건 자화상이고, 이건 우는 여자야”라고 알려주면, 컴퓨터는 ‘우는 여자 그림’을 배우게 되는 것이죠. 심지어는 꼭 사람이 알려주지 않아도 될 겁니다. 인터넷 어딘가에는 우는 여자라는 제목의 이미지가 있을 테니, 몇 번의 검색으로도 곧 알아낼 수도 있을 테니까요.

갑자기 섬뜩한 미래가 떠오르는 얘기를 한 것 같은데요. 이러한 결과가 나오는 아주 재미있는 작업이 있습니다. ‘Portrait Finder’라는 작업인데요. 아마 대부분의 독자께서는 미술관에서 본 그림 속의 어떤 사람을 보고 ‘어!? 이거 내 친구랑 너무 똑같다!’고 생각해 보신 경험이 있으실 겁니다. ‘portrait finder’는 이와 유사하게, 나와 가장 닮은 명화 속의 인물을 찾아주는 프로젝트였습니다.
결과는 참으로 놀라웠습니다. 단순히 얼굴의 각도나 표정만이 아니라 그 사람의 분위기까지 파악한 듯이 보여준다는 생각이 들 정도였습니다. 그 외에도 재미있는 연구들을 영상에서 소개하고 있으니 관심이 있으신 분들은 꼭 한번 보시길 권장해 드립니다. 또한, 구글에서는 ‘Google A.I. Experiments’6라는 사이트를 통해 인공지능을 활용한 다양한 작업을 주기적으로 소개하고 있으니 참고해보시면 좋을 것 같습니다. 주로 미디어 작업이 많이 올라오는 듯합니다.

(출처: https://www.youtube.com/watch?v=egk683bKJYU)
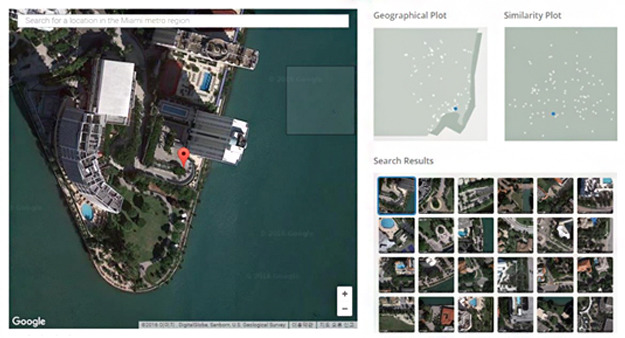
2016년 발표된 골란 레빈(Golan Levin)과 카일 맥도날드(Kyle McDonald) 등이 함께 발표한 ‘테라패턴’(Terrapattern)도 비슷한 예라고 할 수 있습니다. 구글의 지도 데이터를 데이터로 활용하여 학습시킨 후, 특정 지형이나 물체(물탱크, 항구, 다리 등)를 선택하면, 유사한 형태를 가진 다른 지역의 지형들을 찾아주는 프로그램입니다.
간단한 예로 베를린의 한 야구장을 선택하면, LA에 비슷하게 생긴 야구장을 찾아주는 등의 체험을 볼 수 있는데요, 추후에는 사람에 의해 기록되지 못한 버려진 지형, 지물들을 프로그램이 스스로 인식하고 분류하는 것으로 발전하게 될 것 같습니다.
인공지능에 대한 생각
국내에서도 인공지능을 주제로 작업을 진행하고 있는 미디어 작가들이 있습니다. 대표적으로 신승백, 김용훈 작가를 들 수 있는데요. 2012년 작업인 ‘Cloud face’로 Are Electronica 2014에 소개된 바 있습니다. 우리가 어렸을 적, 한 번쯤 생각해봤던 것을 구현해주었는데요. ‘Cloud face’는 구름 이미지 속에서 얼굴이라고 인식되는 부분을 찾아서 보여주는 작업입니다. 이 역시 머신 러닝의 얼굴 검출(Face detection)을 적용하였다고 할 수 있습니다.

최근에는 ‘Flower’라는 작업을 통해 본격적으로 인공지능을 주제로 한 작업을 진행하고 있습니다. 이 작업은 구글의 머신 러닝 이미지 인식 API7를 사용하여, 꽃의 원본 이미지를 왜곡시켜 가면서 프로그램은 어디까지 왜곡된 이미지를 ‘꽃’이라고 인식하는지에 대한 실험 작업입니다.
기계가 바라보는 ‘꽃’이라는 대상은 어떤 이미지인지, 그리고 사람은 어떻게 왜곡된 이미지에서도 ‘꽃’을 바로 인식할 수 있는지 다시 한번 생각해 볼 수 있는 작업이라는 생각이 드네요.

미디어 아트 분야에서의 인공지능의 미래는?
최근 인공지능에 대한 의견이 분분한데요. 인간에게 도움이 될 것으로 생각하는 사람도 있지만, 영화에서처럼 인류를 지배하게 될 것으로 생각하는 분도 상당히 많은 것 같습니다. 사람과는 비교할 수 없을 만큼 짧은 시간에, 엄청난 양의 데이터를 습득하고 사람보다 나은 결과를 내는 것을 보면 두려워지는 것도 사실입니다. 하지만, 그 흐름을 막을 수는 없기에 좋은 방향으로 나아갈 수 있도록 모두가 관심을 가지는 것이 현재로써는 최선이 아닐까 싶습니다.
인공지능의 올바른 성장을 위해서는 우리도 공부하는 수밖에 없겠지요! 미디어 아트 분야에서 머신 러닝에 관해 공부할 수 있는 몇 가지 방법을 소개해 드리겠습니다. 구글의 텐서플로(TensorFlow)와 이미지 분류(Image classifying) 라이브러리의 한 종류인 t-sne를 활용하는 진 코건의 ‘머신 러닝 포 아티스트’8를 뽑을 수 있는데요. 저도 공부 중이긴 하지만, 역시 쉽지는 않습니다. 연초를 맞아, ‘작심삼일’이 되지 않도록 꾸준히 해보도록 하겠습니다.
글 | 송준봉 | 미디어 아트 그룹 teamVOID
teamVOID는 현재 송준봉, 배재혁으로 이루어진 미디어 아트 그룹으로, 기술과 예술의 융합을 주제로 로봇, 인터렉티브, 키네틱, 라이트 조형 등 다양한 뉴미디어 매체를 통해 실험적인 시스템을 구상하고 그것을 작품으로서 구현하고 있습니다.
[‘예술과 IT’ 연재 현황]
- [1편] 예술과 IT – 컴퓨터가 그린 그림
- [2편] 예술과 IT – 프로젝션 맵핑(Projection Mapping)
- [3편] 예술과 IT – 인터랙티브 아트(Interactive Art)
- [4편] 예술과 IT – 인터랙티브 아트의 기술과 구현
- [5편] 예술과 IT – 인터랙티브 아트 : 카메라를 활용한 작업들
- [6편] 예술과 IT – 키네틱 아트(Kinetic Art)
- [7편] 예술과 IT – 로봇(Robot)
- [8편] 예술과 IT – Lighting Art
- [9편] 예술과 IT – 인공지능과 Media Art
- [10편] 예술과 IT – Sound Art
- 넥스트 램브란트 프로젝트: https://www.nextrembrandt.com [본문으로]
- Deep dream project: http://deepdreamgenerator.com [본문으로]
- Tensorflow: https://www.tensorflow.org [본문으로]
- A neural algorithm of artistic style, Leon et.al, 2015. [본문으로]
- https://github.com/yusuketomoto/chainer-fast-neuralstyle [본문으로]
- https://aiexperiments.withgoogle.com [본문으로]
- https://cloud.google.com/vision/ [본문으로]
- 머신 러닝 포 아티스트: https://ml4a.github.io [본문으로]


