
지난 글에서 짚어본 문제점에 대한 해결책으로 HBase 기반의 Big Table System을 제시했는데요. 지금부터는 그 처방과 효과에 대해 살펴보겠습니다.
조치된 빅데이터 처방
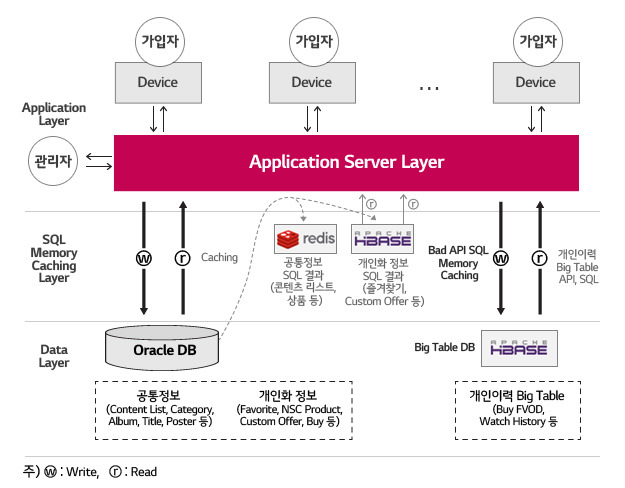
Redis와 HBase로 구성된 Data Caching System으로 Read 집중 문제를 해결하고 HBase만으로 구성된 Big Table로 Write 집중 문제를 해결합니다. ORACLE을 대치하지 않고 NoSQL과 RDBMS 각각의 장점을 융합한 Hybrid 구조입니다. Big Table은 구현되지 않았기 때문에 본 글에서 이야기 하지 않겠습니다.
① 데이터의 특성
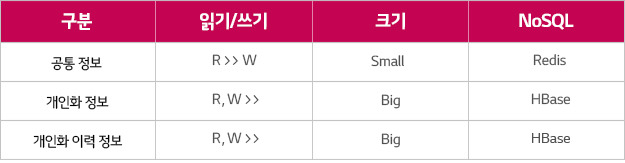
시스템의 데이터는 공통 정보와 사용자 개인화 정보 그리고 개인화 이력 정보로 나눌 수 있습니다. 공통 정보는 Master Data입니다. 개인화 정보는 즐겨찾기와 같은 개인 입장에서의 Master Data이고, 개인화 이력 정보는 구매나 시청과 같이 Time-Series Data입니다.
Read 집중 문제는 공통 정보와 개인화 정보에서 일어나고 Write 집중 문제는 개인화 이력 정보에서 일어납니다. 공통 정보는 읽기 비율이 쓰기에 비해 월등히 높지만 크기는 작습니다. 관리자가 만들고 사용자가 읽기 때문입니다. 개인화 정보와 개인화 이력 정보는 사용자가 만들기 때문에 읽기와 쓰기가 많고 크기도 큽니다(Tab. 1).
② Redis
작지만 읽기가 쓰기보다 많은 공통 정보를 담을 수 있는 NoSQL로 Redis를 선택했습니다. Redis는 메모리 기반의 Key-Value Store입니다. 다양한 특징 중 빠른 Replication 성능을 주목했습니다.
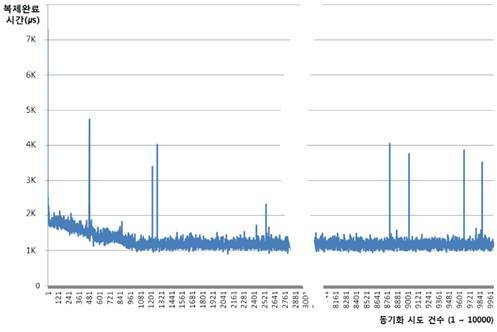
Redis Slave 10개에 초당 30만 읽기 부하 상황에서 Master에 1만번 쓰기를 하고 매번 모든 Slave에 복제가 이뤄졌는지 확인하고 동기화가 완료되지 않았을 때 1ms 후 다시 확인하는 프로그램으로 시험한 결과는 평균 1.2ms에 복제가 완료되었습니다.
1만건 중 9,988건이 첫회 동기화되었고 12건도 1ms 후 확인했을 때 정상 복제되었습니다. 복제 시간이 튀는 것도 있었으나 5ms 이내이고 그래프에서 최초 10ms 소요는 접속 시도 때문입니다. (Fig. 1)
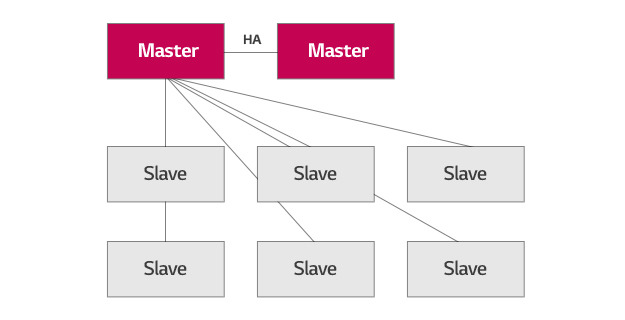
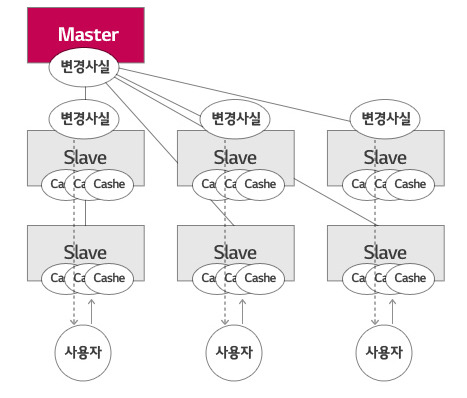
여러 개의 Redis를 Coherent Hashing 기술을 바탕으로 Ling 형태로 구성하는 것이 일반적이지만 대규모 Caching을 목적으로 하지 않고 작은 공통 정보를 N개로 복제하여 읽기 부하를 수평적으로 분산시키는 것이 목적이기 때문에 일반적인 구성 대신 1개 Master에 N개의 Slave를 구성했습니다(Fig. 3).
③ HBase
사용자가 생성하고 조회하는 개인화 정보를 담을 수 있는 NoSQL로 HBase를 선택했습니다. HBase는 Redis와 달리 Permanent Storage를 가지며 Table-like 데이터 구조로 Column을 갖는 NoSQL입니다. Block Cache1 기능과 Sharding2에 주목했습니다.
Block Cache는 Disk I/O를 줄일 목적으로 한번 읽은 블록 전체를 설정한 크기의 Memory 안에서 유지시키는 기능입니다. 메모리를 충분히 확보하고 사용하면 Memory DB와 같은 성능을 낼 수 있습니다.
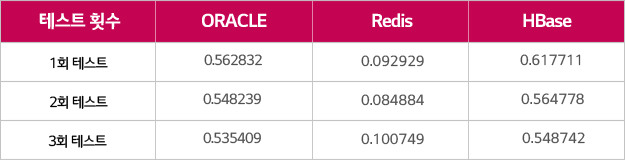
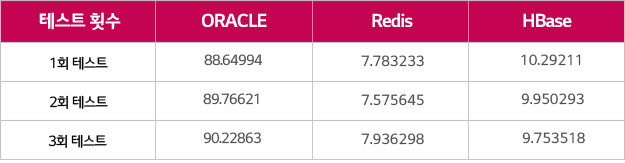
Result Set의 크기가 0.8KB인 Light SQL과 300KB인 Heavy SQL의 Result Set의 결과를 Redis와 HBase에 각각 Caching하여 100회 수행시켜 소요된 시간은 ORACLE과 비교했습니다. 무거운 SQL일수록 ORACLE보다 Redis와 HBase를 읽는 게 빠르다는 것을 보여줍니다.
더불어 Memory DB 중 가장 빠른 Redis와 속도를 비교하면 Light한 경우에 6배 정도 차이가 나지만 Heavy한 경우 HBase와 거의 비슷하게 나옴을 알 수 있습니다.
HBase는 Row Key3를 기준으로 Sharding을 합니다. 논리적으로 Sharding은 분산 환경에서 수평적으로 데이터를 분할하는 것입니다. 앞에서 이야기했듯이 Redis도 Coherent Hashing으로 분산 캐시를 구현해 대량의 데이터를 Sharding해 처리4할 수 있습니다. 그러나 두 가지 단점이 있는데요.
첫째, Redis Cluster가 데이터의 위치를 결정해주지 않습니다. 데이터가 분산환경 어디에 위치할 지는 Client에서 구현해줘야 합니다. 반면 HBase는 Cluster-Side 설정으로 해결합니다. 분할 기준을 설계해 Table을 생성해두면 Client는 연결하고 읽고 쓰기만 하면 됩니다.
둘째, HBase는 CP5 계열의 NoSQL로 Data Consistency를 보장합니다. 사용자가 구매 정보와 같은 주요 정보를 일관되게 볼 수 있도록 해줍니다. 반면에 Redis Cluster는 Cassandra6와 같은 구조를 가지고 있어 AP 계열로 볼 수 있습니다. AP 계열의 NoSQL은 Consistency를 보장해주지 않습니다.
④ 질의 결과 Caching
질의 결과를 Caching하면 SQL 기반인 응용 프로그램을 수정하지 않아도 됩니다. 또한 Tab. 2와 Tab. 3이 보여주듯이 경중(輕重)에 상관없이 일정한 속도의 서비스를 제공할 수 있는 장점도 있습니다.
하지만 SQL의 조회 조건 별로 Cache가 만들어지기 때문에 대용량의 저장소를 필요로 하는 단점이 있습니다. 이런 면에서 저렴하면서 대용량이 가능한 NoSQL이 유리합니다. 또한 ORACLE과 Cache의 동기화를 Row 수준으로 할 수 없습니다.
SQL의 특성상 Bind Variable Input 없이 Join된 Table들의 경우 실행 시 어떤 Row들을 처리하는 지를 RDBMS가 아니면 알 수 없기 때문입니다. 그러한 이유로 아래 예시(Fig. 4)에서 A, D Table은 Row 단위로 동기 제어가 가능하지만 B와 C는 Table 단위로만 가능합니다.
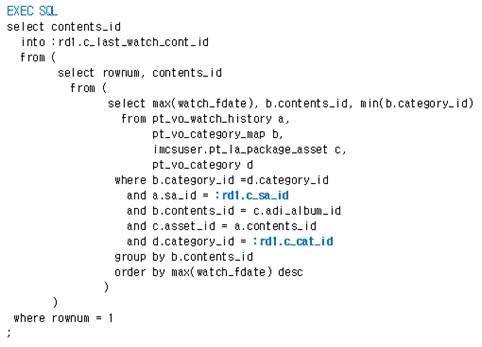
Table 단위로 동기화할 경우 SQL의 결과와 무관한 Row때문에 Cache가 갱신되어 Cache의 수명이 짧아지는 문제가 있습니다. 그러나 짧아져도 Table 단위 동기화는 효과적입니다. 읽기가 쓰기보다 극도로 많은 시스템에서 Cache 수명이 어느 정도 짧은 것은 Cache 자체의 효율을 크게 떨어뜨리진 않습니다(Fig. 5).
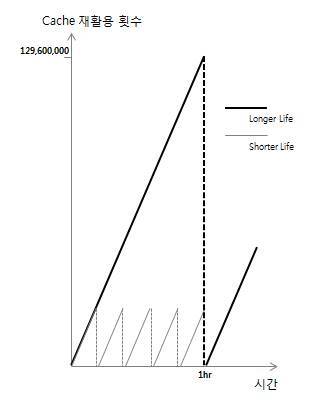
적용 후 한 Node에서 관측된 Redis Cache의 초당 읽기가 6,000인 사실을 바탕으로 하나의 가상 Cache가 1시간 간격으로 갱신되는 것과 시간당 다섯 번 갱신 되는 것을 비교한 것입니다. Y축의 Scale이 X축보다 매우 크기 때문에 Cache의 효율은 큰 차이가 없습니다.
Row 단위 동기 제어는 유지보수가 어렵기 때문에 일반화해 쓰기 어렵습니다. 실제 운영되는 시스템의 데이터를 변경하는 주체는 수작업 변경을 포함해 다양합니다. 변경 주체들을 관리하는 인원과 조직도 다르기 때문입니다(Fig. 14). 그러나 주요 Data에 한해서(여기서는 사용자 ID와 방송 대상 항목들) Row 단위로 제어하도록 했습니다.
⑤ Cache 갱신의 주체는 사용자
관리자가 Cache를 직접 갱신하지 않고 사용자 Transaction이 갱신의 주체가 되도록 했습니다. 작은 Dataset을 Caching하는 경우 전자의 방법을 큰 문제 없이 쓸 수 있지만 Dataset의 크기가 큰 경우에는 적합하지 않은 방법입니다.
기존 시스템에도 일부 공통 정보에 대해서 File 형태의 Cache를 운영 중인데 별도의 서버에서 장시간 Dataset을 만들고 있습니다. Database와 Cache의 실시간 동기화가 어려운 구조입니다.
실시간에 가까운 동기화를 위해 Dataset을 이동시키는 대신 변경 사실만 이동시키는 구조로 설계했습니다. 변경 사실은 Dataset의 크기가 작아 관리가 쉽고 변경 주체로부터 Cache System까지 정보 전달의 시간을 최소화할 수 있습니다.
사용자 Transaction이 Cache System에 접속하면 자체 Logic으로 변경 사실을 확인하고 연관된 Cache를 갱신합니다. 다음 변경 사실이 전달될 때까지 Cache는 이후 사용자들에게 공유됩니다.
Redis Cluster에서 변경 정보는 Master에 써지고 여러 Slave들로 자동 복제됩니다. 사용자는 Load Balancing Logic에 의해서 어떤 Slave에서 접속하고 복제된 변경 정보를 참조해 Cache를 읽거나 생성합니다(Fig. 6).
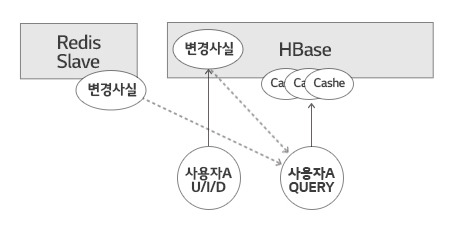
HBase Cluster에서 변경 주체는 사용자 자신의 Update, Insert, Delete 처리입니다. 변경 사실을 자신의 Transaction 안에서 HBase로 씁니다. 이것이 개인화 정보의 변경 정보입니다. 공통 정보의 변경은 Redis에서 읽습니다. 두 정보를 참조해 Cache를 만들거나 읽습니다(Fig. 7).
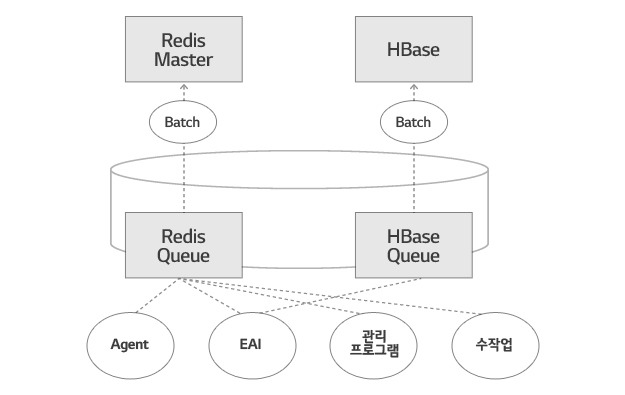
⑥ 동기화 Queue Batch
Database에서 일어나는 변경 사실을 Cache System에 전달하기 위해 비동기적인 방식을 선택했습니다. Queue Table과 그것을 일정한 주기로 읽어 Cache System에 쓰는 Batch 프로그램 입니다.
변경 주체가 다양하고 개발된 프로그램 언어도 다르기 때문에 NoSQL인 Cache System을 직접 갱신할 수 있도록 각자에 맞는 환경을 제공하는 것이 만만치 않기 때문입니다. 변경 주체는 SQL을 이용해 Queue Table에 Insert하면 되기 때문에 적용이 간편해집니다.
비동기식이지만 대상이 매우 작기 때문에, 시간 단위로 최대 2만여 건, 변경 사실은 수초 이내로 Cache에 반영됩니다(Tab. 4).
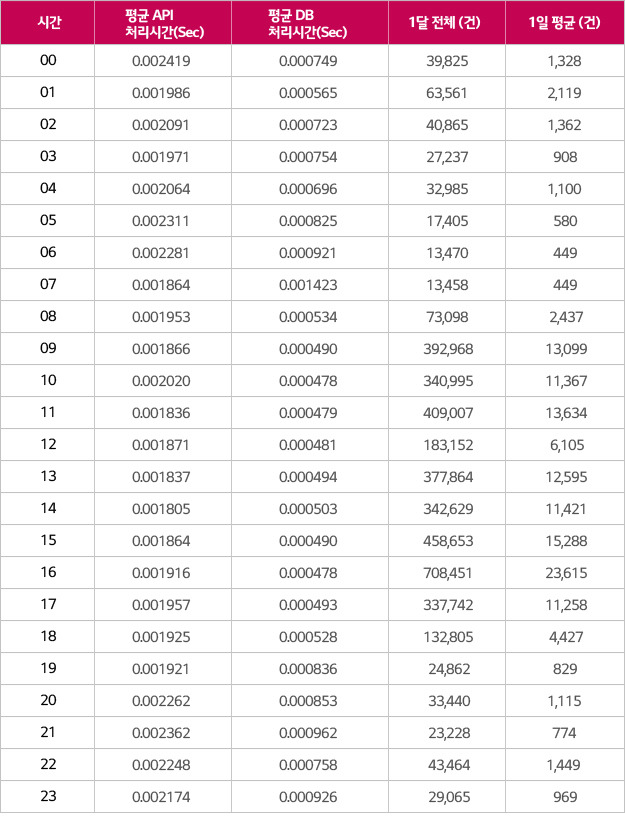
(2015년 1월 한달 동안의 Redis 쪽에 대한 통계. HBase 통계는 EAI로부터 들어오는 사용자 기본 정보이기 때문에 양이 적어 제외)
⑦ 공통 모듈
크게 세 부분이 있습니다. NoSQL에 대한 연결과 Read, Write을 담당하는 HBase와 Redis core가 각각 있습니다. 그리고 Interface를 담당하는 부분이 있습니다. 기존 응용 프로그램들이 Middleware인 TMAX사의 TP Monitor 위에서 Pro*C 기반으로 구축되어 있기 때문에 공통 모듈은 C/C++ 기반의 API 형태로 제공해야 했습니다.
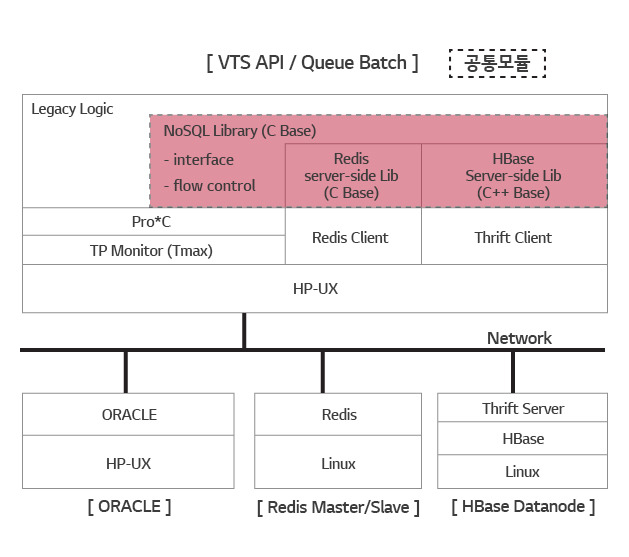
공통 모듈의 기본 기능은 사용자가 SQL을 수행했을 때 Cache의 내용이 최신인지 확인하고 최신이면 돌려주고 그렇지 않으면 ORACLE에서 읽어와 Cache를 새로 만들고 결과를 주는 것입니다.
Load Balancing 기능이 있습니다. NoSQL Cluster의 Redis Slave들과 Thrift Server들에 대해 부하가 고르게 분산되도록 합니다. 장애 감지를 위해 Cluster 내부와 소통이 필요하기 때문에 Hardware인 L4를 사용하지 않았습니다.
Runtime Blocking 기능이 있습니다. Cluster 내 N개의 Node들에게 부하를 분산하여 처리하는 과정에서 한 Node의 장애를 감지하면 그쪽을 폐쇄하고 정상 Node로 우회할 수 있도록 합니다. HBase의 경우 HBase RegionServer 장애와 Thrift 장애를 구분하여 대응해야 합니다. 후자는 연결 장애지만 전자는 데이터 장애이기 때문입니다.
Full Blocking 기능이 있습니다. Redis와 HBase Cluster를 각각 또는 모두 사용하지 않도록 하는 기능입니다. NoSQL 전체 장애 대응과 유지보수 차원에서 필요한 기능입니다.
주기적으로 정합성을 점검하는 기능이 있습니다. Cache와 DB의 동기화가 깨질 수 있는 위험이 항상 존재하기 때문에 깨진 채 방치되는 것을 막기 위해서입니다. 어떤 Cache의 읽기가 설정된 횟수에 도달하면 RDB와 Cache의 데이터 정합성을 강제 확인합니다.
확인 결과가 다르면 해당 Cache를 더 이상 사용하지 못하도록 하고 관리자에게 Reporting합니다. 점검 간격과 횟수를 2단계로 설정할 수 있습니다. 따라서 초반을 짧게 하고 후반을 길게 설정하여 개발자 실수에 의한 부정합을 초반에 대응할 수 있습니다.
HBase 쓰기 실패에 대한 대응 기능이 있습니다. HBase가 부분 및 전체 장애 시 RDB와 Cache의 정합이 깨질 수 있습니다. 이에 대한 대비로 RDB에 Queue 개념의 Table을 만들어 Batch를 통해 장애 복구 후 동기화되도록 했습니다.
Long Running SQL에 대한 대응 기능이 있습니다. 실행에 오래 걸리는 SQL은 Cache 생성에 오래 걸리기 때문에 만드는 동안 응답속도를 위해 Dirty Cache가 조회되도록 했습니다.
빅데이터 처방의 효과
① 시험 환경 및 시나리오
ORACLE Database를 공유하는 7개 서비스 중 D 시스템의 28개 프로그램에 Cache를 사용하도록 적용했습니다. D 서비스는 RAC의 한쪽 Node에서 서비스되고 있었습니다.

운영 Database 서버는 RAC 2 Node이고 사양은 아래와 같습니다.
● HP Superdom 32 core (3,910,767 tpmc)
● Memory 256GB
● Storage VNX5300
● Oracle 10.2.04
Redis Cluster는 하기 사양의 서버 8대로 구성된 LG CNS SBP Appliance 를 씁니다. 이중 2대는 Master, 6 대는 Slave입니다.
● HP DL360p Gen8
● CPU 1P/8 Core 2.6 GHz
● Memory 64GB
● Redis 2.8.0
HBase Cluster는 하기 사양의 서버 8대로 구성된 SBP Appliance를 씁니다. 이중 2대는 Hadoop Namenode이고 6대는 Datanode입니다.
● HP DL380p Gen8
● CPU 2P/16 Core 2.6 GHz
● Memory 64GB
● Apache HDFS 1.1.2
● Apache HBase 0.94.5
● Thrift 0.8.0
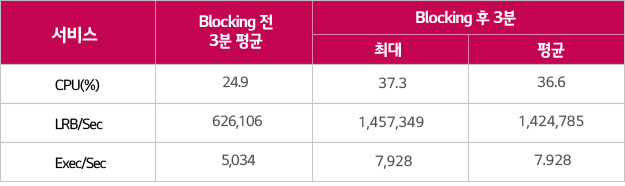
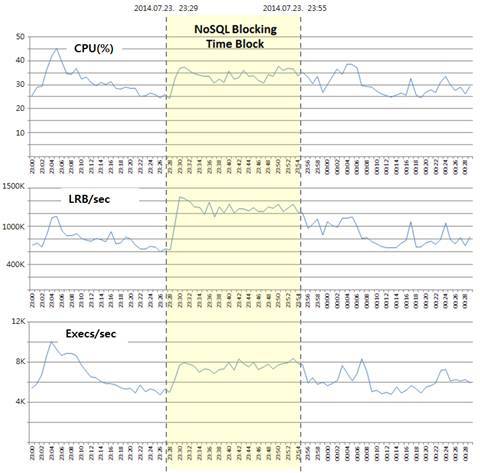
사용률이 가장 높은 시간대 직후인 23시 29분에 Cache를 사용하지 않게 Blocking하고 ORACLE만 사용하도록 했습니다. Blocking 시점 전후로 3분간 사용률이 같다고 가정하고 서버 지표인 CPU 사용률과 Database 지표인 초당 LRB 수, 초당Executions 수를 비교했습니다. Blocking은 26분간 유지했습니다.
② 시험 결과
Cache 없었을 때와 비교해 CPU 사용률은 약 32% 감소하였고 초당 LRB는 56%, 초당 Executions 는 36% 감소하는 결과를 얻었습니다. 사용자의 이용이 많을수록 Cache 효과가 높아지는 아키텍처이기 때문에 최번시에 더 높은 효과를 보였을 것으로 예상됩니다.
빅데이터 처방 후기
주변에 많은 우려가 있었지만 OSS인 HBase와 Redis 그리고 Commodity Linux Server로 구성된 LG CNS SBP Appliance를 B2C 성격의 1등급 시스템에 적용하여 안정적으로 운영하는 성과를 얻었습니다. 2014년 6월 25일 오픈부터 글을 쓰고 있는 2015년 2월 12일까지 6개월 이상 무 장애로 운영되고 있습니다.

Big Cache System의 관점에서는 Big Data를 OSS로 Caching할 수 있는 Architecture와 기술을 성립했습니다. 그리고 SQL 결과를 Caching하는 구조는 기존 응용 시스템의 수정이 크게 요구되지 않기 때문에 다양한 목적의 시스템에 적용할 수 있을 것입니다. Big Cache System은 Big Table System과 더불어 RDB 증설의 악순환을 끊을 수 있을 것입니다.
Big Cache System의 한 부분으로 운영된 HBase가 성능과 안정성을 고객으로부터 인정받은 것도 성과입니다. Hbase가 중요한 이유는 영구 저장소를 가지고 있기 때문인데요. 향후 다양한 Data를 저장하는 용도로 사용될 것입니다.
Big Cache System의 Cache Monitoring을 통계 기반으로 강화하고, 수집된 정보의 분석을 통해 개발자 오류 등을 찾아 Cache의 수명을 늘리는 것이 앞으로의 과제가 될 것입니다.
지금까지 빅데이터의 새로운 활용법에 대해서 소개해 드렸는데요. 여러분과 빅데이터가 한 걸음 더 가까와지는 계기가 될 수 있기를 바랍니다.
글 ㅣ LG CNS 빅데이터사업담당
[혁신의 시작, 빅데이터 활용 연재 현황]
[1편] SRA와 함께라면 당신도 데이터 분석 전문가!
[2편] 빅데이터로 실시간 장애감지 및 분석까지!
[3편] 금융 정보계에 HIA 도입의 필요성
[4-1편] 빅데이터를 친구로 만드는 첫 걸음, 바라보는 관점 바꾸기 ①
[4-2편] 빅데이터를 친구로 만드는 첫 걸음, 바라보는 관점 바꾸기 ②
[5편] 빅데이터 시대, 자연어 기반의 빠른 검색이 온다
[6편] 하둡 기반 데이터 웨어하우스 모델링
[7-1편] 빅데이터 시각화 분석 ①
[7-2편] 빅데이터 시각화 분석 ②
[8편] 소셜 빅데이터 분석을 통해 신(新)소비 트렌드를 읽다
[9-1편] 고객 시선 강탈의 중요 요소 ‘빅데이터 추천 시스템’ ①
[9-2편] 고객 시선 강탈의 중요 요소 ‘빅데이터 추천 시스템’ ②
[참고문헌]
(1) ORACLE, Oracle Clusterware and Oracle Real Application Clusters Administration and Deployment Guide 10g Release 2 (10.2), 2010, pp.17
(2) ORACLE, Overview of hot block contention, 2012
(3) 정성준, Redis 복제 성능 시험, LG CNS, 2013
(4) Lars George, HBase: The Definitive Guide, 2011, pp216
(5) Lars George, HBase: The Definitive Guide, 2011, pp7
(6) Tiago Macedo and Fred Oliveira, Redis Cookbook, O’Reilly, 2011, pp53
(7) http://blog.nahurst.com/visual-guide-to-nosql-systems
- Oreilly, HBase: The Definitive Guide 2011, Lars George, p216 [본문으로]
- Oreilly, HBase: The Definitive Guide 2011, Lars George, p7 [본문으로]
- HBase 테이블의 검색 가능한 유일한 대표 열 [본문으로]
- 한빛미디어, 대용량 서버 구축을 위한 Memcached 와 Redis 2012, 강대명, P23~p36 [본문으로]
- CP(Consistency-Partitioning Tolerance) in CAP [본문으로]
- Facebook에서 개발하여 Apache Software Foundation에 공개한 AP 계열의 NoSQL [본문으로]


