
인터넷 서비스가 고도화됨에 따라 사용자가 생성하는 정보의 저장과 처리가 필요하고, 이를 위한 Big Cache System이 요구되고 있습니다.
DB의 장애와 증설 비용을 고민하던 800만 사용자를 가진 B2C 서비스 시스템에 Open Source Software인 Redis와 HBase기반의 Cache System을 구축하여, 목표한 수준으로 CPU 사용률을 낮출 수 있었죠.
알파고와 빅데이터
알파고와 이세돌의 바둑 대결은 현재를 살아가는 사람들에게 많은 충격을 주었고, 새로운 세상에 대한 상상력을 자극했습니다. 이러한 알파고의 뒤에는 Deep Learning이란 기술이 숨어있고, 그 뒤로는 분산 병렬 컴퓨팅이라는 든든한 형님이 버티고 있는데요. 무려 1,202개의 CPU와 176 개의 GPU로 동시에 연산을 수행하는 것입니다.

빅데이터(Big Data)란 말이 나온 지는 오래되었지만, 아직 실체가 없이 추상적인 느낌이고 외국에서나 제대로 활용할 것만 같은 느낌이 드는 것도 사실입니다. 매체나 일반인들 사이에서 빅데이터는 ‘분석’의 뉘앙스가 강하고 또 ‘빅 브라더’의 이미지도 겹쳐있어 그리 좋은 느낌을 주지 못하고 있는데요. 이러한 빅데이터의 뒤에도 알파고와 마찬가지로 분산 병렬 컴퓨팅이 버티고 있습니다.
빅데이터를 적용할 사용처를 찾고 있는 현업의 입장에서는 빅데이터를 분산 병렬 컴퓨팅 기술 그 자체로 보는 것이 멀게만 느껴지는 빅데이터를 친구로 만들 수 있는 첫걸음이라고 할 수 있습니다. 일단 ‘분석’이란 단어는 잊고 분산 처리를 적용할 곳을 찾는 것이죠. 찾다 보면 적용하게 되고 적용하게 되면 빅데이터가 모이게 될 것입니다. 그 때 가서 분석을 논하면 되는 것이죠.
지금부터 소개해드릴 사례는 분산 병렬 컴퓨팅 기술을 이용해 DB의 부하를 덜어주는 아키텍처입니다. 분석과는 무관하지만 이어지는 프로젝트들은 이 아키텍처를 기반으로 큰 데이터를 모을 수 있게 되었습니다.
RDB만으로 B2C 서비스를?
인터넷 기업에서는 흔한 분산 병렬 아키텍처이지만, 우리나라의 공공기관과 민간기업은 아직도 상용 소프트웨어로 구성된 전통 아키텍처를 고수하고 있습니다. 이런 아키텍처에서 가장 문제가 되는 부분은 DB입니다.
RDBMS(Relational Database Management System)가 상용이기 때문에 유지와 증설에 많은 비용이 드는데요. 증설을 한다고 해도 다시 증설이 필요해집니다. 장애도 이어지죠. 가장 큰 문제점은 RDBMS의 한계입니다. 개인화 추천과 같은 고급서비스가 사업 측면에서 구상되더라도 이전의 아키텍처로는 RDB 증설만으로는 해결할 수 없는 한계 때문에 불가능 합니다.
서비스와 사용자가 급증하면서 DB에서의 장애와 증설 비용으로 고민하는 한 IPTV 서비스 업체의 의뢰로 OSS(Open Source Software)인 Redis와 HBase를 기반으로 하는 Big Cache System과 Big Table System을 2013년 초 제안했습니다. 이 중 Data Caching System을 가장 트랜젝션이 많은 휴대폰 서비스에 구축하기로 하고 2013년 11월부터 시작하여 2014년 6월 25일 800만 가입자에게 오픈했습니다.
빅데이터를 처방하기 전
① 문제가 되었던 RDB만의 아키텍처
사용자는 휴대폰이나 STB(Set Top Box), PC 등의 단말을 통해 응용 서버에 데이터를 요청합니다. 응용 서버는 요청 중 일부를 Local File System에 위치한 File Cache로 서비스하지만 대부분 ORACLE에서 데이터를 읽어 서비스합니다.
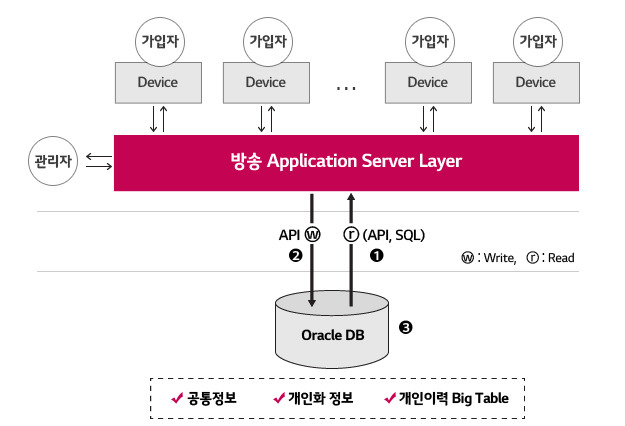
② 발생하는 문제 현상들
서비스의 특성상 짧은 시간에 사용자의 이용이 집중될 수 있습니다. 응용 서버는 서비스와 사용자별로 여러 대를 운영하고 있어 이러한 집중에 대응할 수 있지만 DB는 사정이 다릅니다. 모든 사용이 집중되죠. 사용자가 800만 명이나 되기 때문에 대비해야 할 Transaction 밀도는 예측하기 어렵고 또 크기는 RDBMS가 감당할 수 있는 수준을 상회합니다. 이런 집중 상황에서 RDBMS의 한계가 나타납니다. Read 또는 Write에 따라 다른 형태의 문제점들이 나타나는 것이죠.
[Read 집중]
안정적인 운영과 증설 시점 판단에 있어서 DB 서버의 CPU 사용률은 가장 중요한 지표입니다. 이 시스템의 CPU 사용률 추이는 LRB1 추이와 일치하는데요. Fig.1에서 전반적으로 아래에 위치한 선은 LRB의 추이이고 위는 CPU 사용률의 추이입니다. PRB2 추이는 일치하지 않습니다. LRB에 비교했을 때 PRB는 거의 없는 수준입니다.
Fig.3을 보면 LRB와 PRB는 3,510배나 차이가 납니다. 일반적인 시스템의 CPU사용률 증가는 PRB를 동반하는 데 여기서는 전혀 다른 형태를 보입니다. 모든 조회 데이터는 메모리 상의 ORACLE의 SGA에 위치하고 있다는 의미입니다.
수행 횟수가 너무 많아 논리적인 읽기만으로 CPU 부하가 올라가는 것입니다. ORACLE은 이미 메모리 DB인 셈입니다. 이런 사실로 혹자의 메모리 DB 도입 의견을 무시할 수 있었습니다. 여기 필요한 것은 Distributed Architecture입니다. 이를 가진 Data Cache와 Big Table System이 필요한 것이죠.
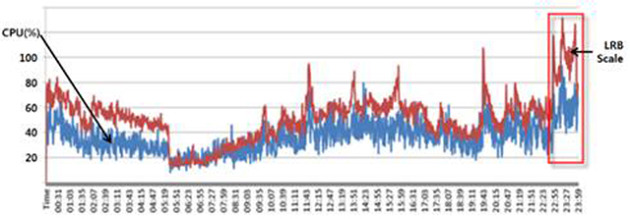
24시간 CPU와 LRB 변화를 겹쳐보았다. 전구간에서 일치한다. 상자 안 23시는 최번시로 CPU 사용률이 평상시보다 월등히 높다.
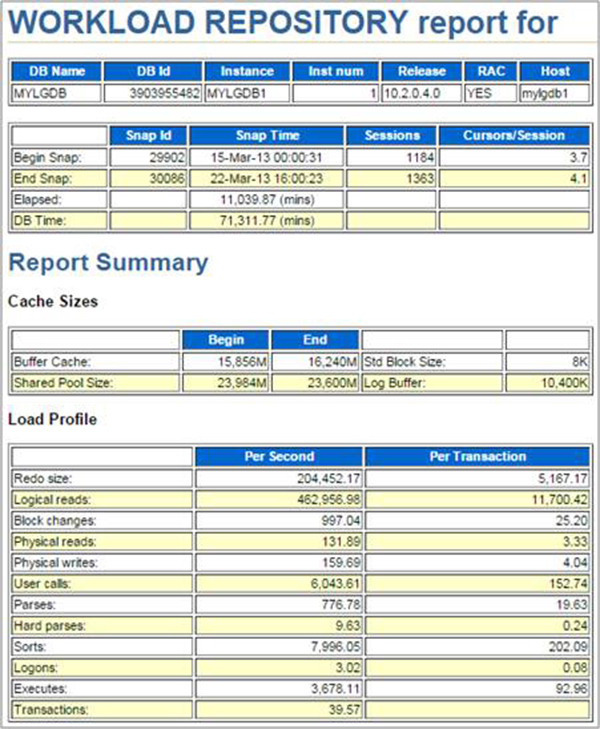
2013년 3월, RAC 2 Node 중 한 Node의 1주일 간의 통계. 초당 Logical reads가 Physical reads를 매우 높이 상회한다.
최번시(最繁時, busy hour)와 그렇지 않은 시간대의 CPU 사용률의 편차가 크지만 운영 안정성 때문에 최번시 기준으로 보수적인 증설 계획을 세울 수 밖에 없습니다. 따라서 대부분의 시간대에서는 자원이 놀게 됩니다. 이런 어쩔 수 없는 잉여 자원도 사업자에게 부담이 됩니다.
Fig.2는 예측 가능한 증가이지만 Fig.4는 예측할 수 없는 증가입니다. 가입자 수가 크기 때문에 프로그램 인기도, 이벤트, 연휴, 올림픽과 같은 변수로 인해 사용률이 크게 바뀔 수 있어 최번시 통계만을 가지고 증설하는 것도 용량 부족의 위험을 안고 있습니다.
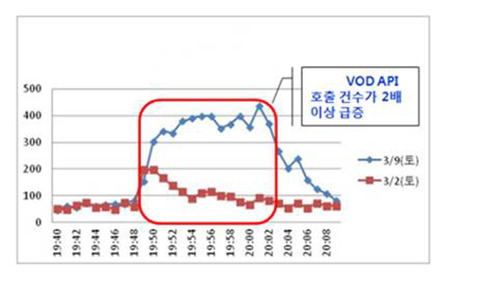
[Write 집중]
시청과 구매 Table에는 많은 쓰기가 발생합니다. Table 별로 일 200만 건 정도 발생하는데요. 성능과 비용 문제로 모든 데이터를 유지할 수 없어 일주일치만 남기고 삭제합니다. 고급 서비스를 위해서는 사용자가 생성하는 정보에 대한 쓰기와 장기간 보관이 필요하지만 DB의 한계로 못하고 있는 것이죠.
Read 집중보다 정도는 심하지 않지만 사용률 증가 시 Read에 의한 CPU 사용률 증가와 함께 Write도 급격히 증가합니다. 이 때 ORACLE의 Wait Event인 ‘TX: index contention’과 ‘gc buffer busy’가 과도하게 발생하고 쓰기 지연 장애가 발생합니다.
쓰기 경합이 발생하는 ORACLE의 Object는 이력 Table에 위치한 Timestamp를 갖는 Index들 입니다. 동시에 여러 Process들이 한 Block에 INSERT하는 Right Hand Index입니다. 최근 이력 조회를 서비스가 요구하기 때문에 조회에 필요한 Timestamp열에 대한 Index 생성을 안할 수 없습니다. Fig.4는 Right Hand Index의 실 목록입니다.
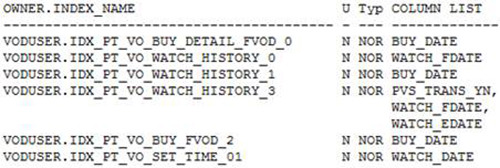
최근 시간 데이터 색인이 위치하는 가장 오른쪽 Leaf Block에 부하가 집중되고(Fig.6) 여러 RAC Node에서 Process들에 의해 번갈아 불려지면서 ‘gc buffer busy’가 대량 발생됩니다. 이 문제를 해결하기 위해서는 Timestamp열에 대한 Index를 포기하거나 Hash Partitioning을 해야 합니다.
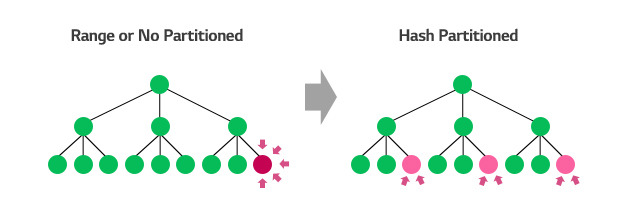
Partitioning을 Hash로 하게 되면 Right Hand Index 문제가 해결되나 TRUNCATE를 못해 대량의 데이터를 Delete해야 합니다. 이 또한 자원 소모가 많아 서비스 장애로 이어질 수 있는 요인이 됩니다. Range로 하게 되면 TRUNCATE는 가능하나 Right Hand Index 문제가 계속됩니다.
지역과 같이 사용자를 나눌 수 있는 열을 전치시켜 Timestamp열과 묶어 Composite Partitioning을 하면 완화시킬 수 있지만, 큰 쓰기 집중 상황에서는 근본적인 해결책이 되지 않습니다.
이 문제에 대해 제시한 대안인 HBase 기반의 Big Table System에 대해서는 다음 시간에 함께 살펴보도록 하겠습니다.

글 ㅣ LG CNS 빅데이터사업담당
[혁신의 시작, 빅데이터 활용 연재 현황]
[1편] SRA와 함께라면 당신도 데이터 분석 전문가!
[2편] 빅데이터로 실시간 장애감지 및 분석까지!
[3편] 금융 정보계에 HIA 도입의 필요성
[4-1편] 빅데이터를 친구로 만드는 첫 걸음, 바라보는 관점 바꾸기 ①
[4-2편] 빅데이터를 친구로 만드는 첫 걸음, 바라보는 관점 바꾸기 ②
[5편] 빅데이터 시대, 자연어 기반의 빠른 검색이 온다
[6편] 하둡 기반 데이터 웨어하우스 모델링
[7-1편] 빅데이터 시각화 분석 ①
[7-2편] 빅데이터 시각화 분석 ②
[8편] 소셜 빅데이터 분석을 통해 신(新)소비 트렌드를 읽다
[9-1편] 고객 시선 강탈의 중요 요소 ‘빅데이터 추천 시스템’ ①
[9-2편] 고객 시선 강탈의 중요 요소 ‘빅데이터 추천 시스템’ ②
- LRB(Logical Read Blocks). ORACLE의 내부 지표로 SGA에서 읽혀진 Block들의 개수이다. [본문으로]
- PRB(Physical Read Blocks). ORACLE의 내부 지표로 Disk에서 읽혀진 Block들의 개수이다. [본문으로]
- AWR(Automatic Workload Repository). ORACLE이 자동 생성한 Workload의 통계를 조회할 수 있다. [본문으로]


