SSDP(Self Service Data Preparation)는 BI/DW에서의 데이터 전처리 도구(Data Preparation Tools)의 차세대 버전으로, 데이터 전처리 과정을 자동화 및 지능화해 주는 도구입니다. 비즈니스 사용자의 데이터 분석을 지원하는 기술인 ‘셀프서비스 BI’가 데이터 준비 절차인 ‘셀프서비스 데이터 프레퍼레이션’으로 확장된 것입니다.
가트너는 ‘SSDP는 현업 사용자가 분석을 수행할 때 다양한 원천 데이터 소스와 각종 분석 도구의 중간인 데이터 전처리 과정(데이터 탐색, 통합, 카탈로깅, 정제, 변환, 모델링 등)에서 요구되는 복잡도와 소요시간을 줄여주는 도구’라고 정의하고 있습니다.
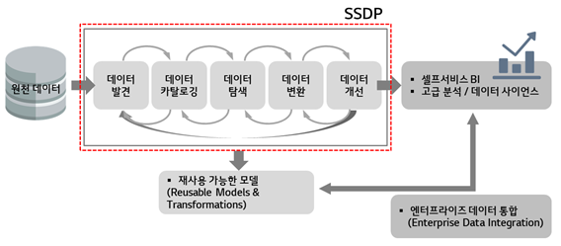
SSDP 등장 배경
인공지능과 빅데이터의 급부상으로 인해 현업 사용자가 파일과 데이터들을 함께 통합해서 보려는 니즈가 많아지고 있습니다. 또한, 레거시 데이터뿐만 아니라, 정형•비정형 데이터, 내•외부 데이터, 소셜 데이터 등 다양한 데이터가 폭증함에 따라, 데이터 전처리 업무도 증가하고 있습니다.
전통적인 데이터 전처리 과정에서는 현업 사용자가 분석요건 변경 및 새로운 데이터 필요 시 IT 부서에 요청하고, IT 부서는 이에 대한 ETL 과정을 수행하게 되는데, 이때 수일에서 수개월이 소요됩니다.
통상 대부분 기업은 분석 시간의 70~80%를 데이터 수집 및 가공에 할애한다고 하는데요. 주로 데이터 웨어하우스 및 데이터 마트 구축과 요구사항 변경에 수개월이 소요되는 상황으로, 분석을 위한 데이터가 적시에 공급되지 않아 의사결정이 지연되고, 이로 인해 기업 경쟁력이 저하되거나 가시성 없는 경영을 초래할 수 있습니다.
이에 따라 비즈니스 유저가 IT 부서로부터 독립되어 직접 데이터 전처리 과정을 빠르게 수행할 수 있도록 SSDP가 해결 방안으로 등장했습니다.
SSDP는 원천 데이터부터 최종 대시보드까지 분석의 모든 과정에서 IT 부서의 개입을 최소화합니다. 미가공 데이터를 데이터 사이언스, 데이터 디스커버리 및 BI 분석을 위해 최적화된 데이터셋으로 쉽고 빠르게 큐레이팅 해주기 때문에 현업 사용자가 데이터 탐색, 변환 및 정제 작업을 능동적으로 수행할 수 있고 이로 인해 비즈니스 로직이나 업무 지식을 활용해 분석 과정에 집중할 수 있게 해줍니다.
아래 그림에서 보는 바와 같이 전통적인 데이터 통합 방식에 비해 SSDP를 도입하면 데이터 전처리 과정에서 80% 이상의 시간과 노력을 절약할 수 있습니다.
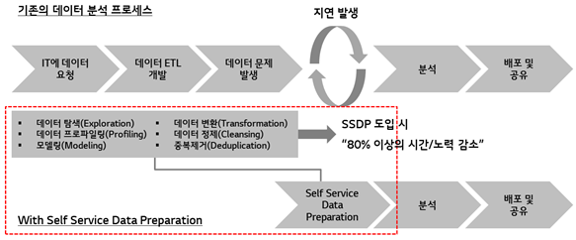
SSDP는 전통적인 데이터 통합 기술과 비교했을 때 주로 사용자, 사용자 경험, 데이터 모델링 및 통합 방법, 데이터 종류, 그리고 소요시간 관점에서 차이가 있습니다.
정리해서 말하자면, 전통적인 데이터 통합 기술은 사용자 및 데이터 종류, 소스 등 전반적인 측면에서 제한적이며, 많은 시간이 소요되는 반면, SSDP는 Citizen Data Scientist를 비롯해 다양한 사용자들 포함시키면서 정형•비정형•오픈 데이터까지 처리하는 등 유저 중심의 민첩한 플랫폼의 형태를 갖추고 있습니다.

SSDP 기능을 탑재한 솔루션은 대부분 ‘엔터프라이즈 데이터 전처리 플랫폼(Enterprise Data Preparation Platform)’의 형태로 제공되고, 빅데이터 분석 준비를 위해 전통적인 데이터 통합 방식 대비 데이터 전처리 과정을 자동화, 지능화 및 간소화해주기 위한 기술들로 자연어 처리 기술, AI 및 머신러닝 기술(시맨틱 오토 디스커버리, 지능형 조인, 지능형 프로파일링), HTML5 기반 웹 UI, 병렬 인메모리 분산처리 기술 등을 활용합니다.
SSDP가 제공하는 주요 기능은 다음과 같습니다.
(1) 데이터 접근 및 연결성(Data Source Access, Connectivity)
- 다양한 데이터 소스 수집 및 외부 BI 분석 툴과의 연결 제공
- 현업 사용자는 이기종 데이터의 형식에 관계없이 데이터 Import 가능
- 원천 데이터부터 정형•비정형 데이터, 클라우드•온프레미스 데이터, RDB, NoSQL, 하둡(Hadoop) 및 다수의 파일 포맷(Excel, .csv, .pdf, XML, JSON)까지 포괄적 지원
- 이기종 데이터에 대한 APIs 및 표준 기반의 연결성(Connectivity) 지원
- 메타데이터 저장소(Metadata Repository) 및 메타데이터 카탈로그에 접근하기 위한 APIs 지원
(2) 데이터 변형, 병합, 보강, 모델링(Transformation, Blending, Enrichment, Modeling)
- 데이터에 대한 전처리 기능인 데이터 변형부터 병합, 보강, 정제, 마스킹, 필터링, 민첩한 데이터 모델링 까지 포괄적으로 지원
- 자연어 처리(Natural Language Processing) 기술: 데이터를 정제할 때, 자연어 처리 알고리즘으로 글자 및 배열 순서의 오류 등 불일치 데이터를 정제하여 그룹핑
- 데이터를 필터링할 때, 수천만, 수억 건의 원천 데이터를 필터링해 웹브라우저에서 즉시 시각화
(3) 인터랙티브한 데이터 전처리 기능(Interactive Data Preparation, Data Exploration & Profiling)
- 현업 사용자는 HTML5 기반 웹 UI를 통해 코딩, 스크립팅 없이 Drag & Drop만으로 손쉽게 전처리 수행 가능
- 비주얼 환경에서 사용자는 Interactive 하게 데이터 준비, 검색, 샘플링, 프로파일링, 카탈로깅, 목록생성, 태깅 및 주석처리 가능
- 최종 분석용 결과 데이터셋을 만들어 배포 시 기존 BI 툴에 접속해 바로 사용 가능
(4) 인공지능 및 머신러닝 역량(Intelligent Capabilities, AI, Machine Learning)
- 머신러닝과 AI를 사용하여 SSDP 프로세스를 자동화
- 머신러닝 알고리즘 기반 엔진을 통해 어떤 통계 패턴이나 데이터에 대한 원천 데이터를 자동으로 판단, 파싱(Parsing)하거나 데이터 형태에 따라 결과를 추천
- 머신러닝 기반의 시맨틱 오토 디스커버리(Semantic Auto-discovery), 지능형 조인(Intelligent Joins), 지능형 프로파일링(Intelligent Profiling)을 포함
(5) 데이터 큐레이션(Data Curation, Governance)
IT 부서는 데이터 준비와 분석 과정을 모두 사용자에게 맡기면 데이터를 추적하고 통제하며, 동시에 사용자 권한 관리까지 해야 하는 어려움을 보유하게 됩니다. 따라서 다음과 같은 기능이 필요합니다.
- 데이터 관리(Stewardship), 데이터 암호화(Encryption), 사용자 권한 및 데이터 계통(Lineage) 기능
- 프로젝트에서 진행한 모든 시간대별 작업 내용에 대한 버전을 관리해 버전 별 주석을 입력, 쉬운 인식 및 복원 기능
- 편집 단계에서는 프로젝트의 단계를 확인 및 수정, 추가, 조정 및 삭제할 수 있는 기능
- 프로젝트 자동화 기능: 설정한 스케줄에 따라 해당 프로젝트의 처리 결과 데이터를 업데이트하고, 모든 작업에 대한 기록, 추적 및 작업 재수행•재사용
- 라이브러리 자동화 기능: 라이브러리 내 데이터를 설정한 스케줄에 따라 업데이트
- 협업(Collaboration) 지원: 사용자 간 쿼리 및 데이터셋 공유
(6) BI&A 및 고급분석 플랫폼과의 통합 기능(Integration with BI&A & Advanced Analytics Platforms)
- APIs나 파트너社의 파일 포맷(.tde for Tableau Software, .qvd for Qlik, .pbi for MS Power BI 등) 지원을 통해 큐레이팅 된 데이터셋들을 BI&A 및 고급분석 플랫폼들과 통합 가능
- 데이터 전처리가 완료된 데이터를 출력한 후, 외부 BI 분석 툴로의 연결 및 URL 방식의 기능 호출을 지원
- 클라우드, 온프레미스 또는 하이브리드 환경에서 SSDP 플랫폼 배포 가능
(7) 병렬 인메모리 분산처리(Distributed In-Memory Parallel Processing)
- 기존에는 하둡 기반의 맵리듀스를 사용하여 빠르게 분석 결과를 제공하였으나, 맵리듀스 작업은 단계별 Disk I/O가 불가피해 지연시간이 존재
- 이에 따라, SSDP는 Spark를 통해 병렬 인메모리 분산처리 시스템이 동작
- 해당 시스템은 Resilient Distributed Dataset(RDD) 방식으로 하드디스크를 거치지 않고 메모리 사용을 극대화함으로써 맵리듀스 대비 빠른 성능 및 유연한 확장성을 제공
- 명령어를 컴파일해 Spark에 명령을 내림으로써 기존 개발 방식보다 최적화된 처리가 가능

적용 사례
◎ 펩시코
펩시코(PepsiCo)는 Trifacta Wrangler Enterprise를 도입해 더욱 정확하고 민첩한 세일즈 예측을 위한 SSDP 플랫폼을 개발했습니다.
● 문제 상황
펩시코(PepsiCo)는 펩시콜라, 프리토레이(Frito-Lay), 퀘이커(Quaker), 트로피카나(Tropicana) 등 식음료를 공급하는 식음료(F&B) 전문 업체입니다. 각 펩시코의 애널리스트는 매주 4~5개의 리포트를 수동으로 빌드, 업데이트하여 10개 이상의 소매업자에 대한 퍼포먼스 세일즈를 분석해야 했는데요.
이를 위해 애널리스트는 CPFR(Collaboration, Planning, Forecasting, Replenishment) 툴을 사용했습니다. 이 툴은 느리고, 에러에 취약한 엑셀 및 MS Access를 활용하여 펩시코 서버에서 리포트를 직접 다운받아, 액세스 데이터베이스를 통해 리포트를 실행시켰으며, 다시 펩시코 서버상에서 해당 데이터를 수동으로 변형시켜 사용했습니다.
● 해결 방안
펩시코는 이를 해결하기 위해 Trifacta Wrangler Enterprise를 도입해 더욱 정확하고 민첩한 세일즈 예측을 위한 SSDP 플랫폼을 개발했습니다.
이 플랫폼은 하둡 상에서의 리포트 실행을 지원함으로써, 기존 다수의 서버 대신 단일 서버를 활용 가능 하게 되었고, 데이터 전처리에 대한 직관적인 UI를 제공하는 것은 물론 태블로(Tableau, 데이터 시각화에 초점을 맞춘 셀프서비스 분석 플랫폼)로 전처리 완료된 데이터셋을 발행해 시각화까지 가능하게 되었습니다.
또한 인벤토리 및 생산 계획 수립을 위해 실제 제품별 판매량을 세일즈 예측 결과에 반영하여 인벤토리를 최적화하고 있습니다.
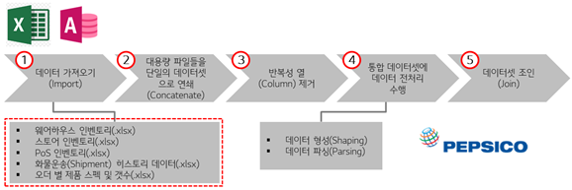
● 효과
펩시코는 소매업자에 대한 퍼포먼스 세일즈 분석에 SSDP를 활용함으로써 기존 방식 대비 리포팅 타임이 약 70% 감소했으며, 세일즈 데이터 빌드 타임은 약 90% 감소했습니다. 전반적으로 리포트 생성 프로세스를 간소화했고, 세일즈 동향에 더 정확하고 민첩하게 대응할 수 있게 되었습니다.
◎ 프리시전프로파일
생물정보학 전문 업체 프리시전프로파일(PrecisionProfile)는 Paxata Adaptive Information Platform을 도입해 셀프서비스 데이터 전처리 가능한 게놈 분석 플랫폼을 개발했습니다.
● 문제 상황
프리시전프로파일은 암 연구자 및 연구과학자가 게놈 특성 분석을 수행하고, 암 환자에 맞춤치료 계획을 만들어주는 생물정보학(Bioinformatics) 기술 전문 업체입니다.
다량의 데이터(게놈 데이터, 임상 데이터, 환자 데이터 등)가 생성되면서 데이터 핸들링이 어려워짐에 따라, 암 연구자 및 연구과학자는 데이터 전처리에 소요되는 시간과 노력 단축이 필요했으며, 데이터 사이언스의 전문성 또한 불필요해지기를 희망했습니다.
또한, 다음과 같은 복잡한 데이터 소스가 존재했습니다.
– 암 관련 게놈 데이터(대용량의 VCF 파일 – 1인의 DNA가 약 50GB를 차지)
– 임상 데이터(XML 형식)
– 유전자 데이터(정형•비정형, 높은 변동성)
● 해결 방안
프리시전프로파일은 과거 치료된 암 환자들의 데이터 및 외부 지식 데이터베이스를 새로운 암 환자에 대한 속성과 매칭시켜 유사한 증상, 질병 및 치료를 식별하기 위해 Paxata SSDP 솔루션을 도입했습니다. Amazon S3, FTP 사이트 및 로컬 파일에서 가져온 데이터를 바탕으로, Paxata 솔루션으로 관련 데이터를 통합하고, 데이터 디스커버리 및 전처리 과정을 수행하고 있습니다.
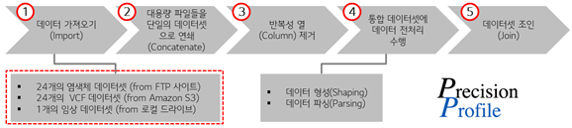
● 효과
프리시전프로파일은 SSDP 도입을 통해 약 1~3개월 소요되던 게놈 임상 스터디를 2~8시간으로 줄일 수 있었고, 데이터 사이언스 전문성이 없는 생물학자 또한 데이터 전처리를 빨리 수행하여 분석에 집중할 수 있게 되었습니다. 이를 통해 전체 연구 사이클을 가속하여 신약 개발에 집중이 가능해졌습니다.
현재 SSDP 기술 도입 수준은 5% 정도지만, 인공지능과 빅데이터 시장 확대 추세와 맞물려 ‘19년에는 SSDP 솔루션 시장이 급격히 성장할 것으로 전망되고 있습니다.
SSDP 시장의 기대감에 부흥해 관련 솔루션이 해외에서 활발히 출시되고 있으나 성숙도는 아직 성장기(Adolescent) 단계인데요. 가트너는 SSDP 기술이 ‘17년 현재 기대감 최고조(Peak of Inflated Expectations) 단계에 있다고 발표했으며, SSDP 글로벌 시장 침투 수준은 타겟 고객의 5~20%라고 전망했습니다.
또한 가트너는 ‘18년까지 대다수 기업에서 분석을 위한 데이터 준비에 SSDP 툴을 도입할 예정이며, ‘18년까지 SSDP 솔루션들은 향후 End-to-End 분석 솔루션•플랫폼으로 확대되거나 기존의 분석 플랫폼 기능으로 통합될 것으로 전망하고 있습니다.

데이터 과학자에 의존하여 데이터 전처리를 처리하던 전통적인 ETL 방식에 SSDP 기술을 적용하면, 기존 데이터 분석 시간의 약 70~80% 상당 차지하던 데이터 전처리 과정을 현업의 비즈니스 사용자가 쉽고 빠르게 수행할 수 있습니다.
이러한 이점으로 인해 앞서 업체 동향에서 언급된 것처럼 글로벌 시장에서 SSDP의 솔루션 성숙도는 충분히 높은 것으로 보이나, 국내에는 생각보다 아직 시장 규모가 그리 크지 않은 것으로 보입니다. 실제로 니즈가 없다기보다 SSDP에 대해 인지하지 못하고 있기 때문이기도 합니다.
SSDP는 기존에 BI/DW가 없어서 빠르게 데이터 분석을 할 수 없는 경우나, 데이터 과학자들의 분석 범위가 넓어서 BI/DW로 커버가 되지 않을 경우에 필요한 솔루션으로 볼 수 있습니다. 최근 각 기업에서 빅데이터 조직을 갖추면서 데이터 과학자들이 늘어나고 있어 이 시장을 관심 있게 지켜볼 필요가 있습니다.
글 l LG CNS 정보기술연구소



