지난 시간의 펫 카페 사장의 고민 예제에 이어 딥러닝 기반의 AI에 대해 설명을 계속하도록 하겠습니다.
● 딥러닝, 데이터로 세상을 파악하다(1)
지난 편을 확인하지 못하신 분들은 위를 클릭해 ‘딥러닝, 데이터로 세상을 파악하다(1)’편을 확인해주시기 바랍니다.
딥러닝 기반의 AI, 자동화 패러다임의 전환
위의 두 가지 방식(룰 기반, 머신러닝 기반)은 사람이 생각했을 때 강아지와 고양이를 구분하는 주요 특징들을 기계에게 알려줘야 합니다. 그런데 아래 몇가지 특이한 케이스를 보겠습니다.

이 데이터들은 우리가 정의했던 강아지와 고양이의 특징에 부합하지 않습니다. 이러한 몇몇 특정 케이스에 대해 예외 규칙을 추가하면 된다구요? 하지만 예외란 언제 어떤 케이스들이 발생할지 알 수 없으며, 그 때마다 매번 규칙을 수정하거나 추가해주는 유지보수에 공수가 많이 들어가는 문제가 발생합니다.
하지만 우리 사람들은 특징이 조금 다르더라도 척 보면 이 친구들이 강아지인지 고양이인지 알 수 있습니다. 사람은 도대체 어떻게 이런 예외들에 대해서도 강아지와 고양이를 잘 분류할 수 있을까요?
‘모라벡의 역설’이라는 개념이 있습니다. 인간에게 쉬운 일이 기계에게는 어렵고, 기계에게 쉬운 일은 인간에게 어렵다는 말입니다. 우리가 별 생각을 들이지 않고도 할 수 있는 강아지와 고양이의 구별, 손을 뻗어 물체 집기, 걷고 뛰는 것, 지인들의 얼굴 구별하기, 자동가입 방지를 위한 꼬부랑 글자 식별 등의 행위는 기계가 수행하기 어렵습니다.
반면 금융 시장에서 주가 시계열 예측, 어려운 학술지 번역하기, 복잡한 미적분 계산 등 이런 것들은 사람이 시간을 들여서 어렵게 수행해야 하지만 기계는 눈깜짝할 새 계산할 수 있죠.
위에서 본 것처럼, 기계에게 강아지와 고양이를 잘 구별하게 하는 것은 어렵지만 사람은 다양한 예외 케이스가 있더라도 고양이와 강아지를 순식간에 구별할 수 있습니다. 애초에 사람은 어떻게 이 둘을 구별할까요? 사람이 강아지와 고양이에 대해 어떻게 배웠는지를 생각해보겠습니다.
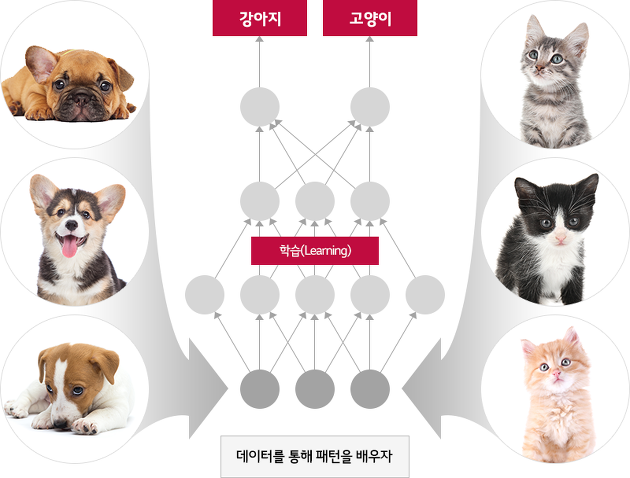
우리가 세상에 태어나서 ‘고양이는 주둥이가 짧고 귀가 뾰족하고 박스를 좋아한단다’같은 규칙이라든지, 사전적인 정의를 통해 고양이를 배우진 않았습니다. 동물 그림 카드를 보면서 ‘아 강아지는 이렇게 생겼구나’ 라든지, TV나 동화책에 나온 여러 동물들, 지나가면서 마주친 고양이를 부모님이 ‘저기 귀여운 야옹이가 있구나!’라고 말씀하신 걸 들으면서 배우게 됩니다.
간혹 어릴 적의 여러분이 헷갈려 강아지를 보고 ‘야옹이?’라고 해도 부모님이 ‘아니야, 저건 멍멍이란다’하고 교정해주셨겠죠. 우리는 사전적 정의나 규칙이 아닌, 다양한 여러 사례들을 보고 귀납적으로 강아지와 고양이에 대한 정보를 습득합니다. 말로는 구체화하기 어렵지만, 대충 강아지와 고양이는 각각 이러저러한 특징들이 있다는 것을 깨닫습니다.
그렇다면 기계에게도 수많은 사례를 통해 구별하게 하면 다양한 예외에도 잘 대처할 수 있지 않을까요? 딥러닝은 바로 이러한 모티브를 기계학습에 녹였습니다.
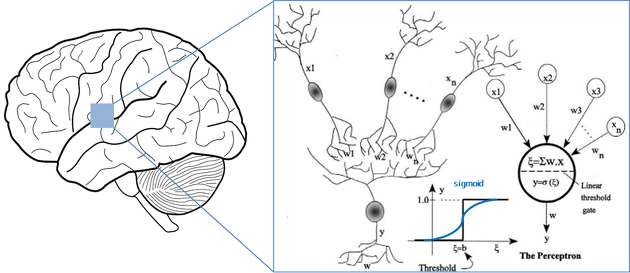
사람의 사고방식을 기계에 적용하기 위해, 이제부터 컴퓨터공학과 신경과학이 손을 잡습니다. 사람에게는 ‘뉴런(Neuron)’이라는 신경 세포가 있어서, 세포의 한 쪽에서 받아들인 전기 자극 정보를 다른 쪽 끝에서 다음 세포로 전달하곤 합니다.

이 모양을 그대로 본따서 만든 것이 ‘인공 뉴런(Artificial Neuron)’으로, 노드로부터 받아들인 데이터를 가중합 연산을 한 뒤 비선형함수를 적용하여 정보를 가공하여 다음 인공 뉴런으로 넘기는 역할을 합니다.
이런 인공 뉴런을 다양한 방식으로 여러 층 쌓아 연결하게 되면 딥러닝의 기본 구조인 ‘인공신경망(Artificial Neural Network)’이 됩니다. 그리고 수많은 강아지와 고양이 사진을 인공신경망에게 보여주면 자동으로 강아지, 고양이 분류를 위한 최적의 연산 모델을 찾아냅니다. 여기엔 귀가 어떻다든지, 주둥이 길이가 어떻다든지 하는 인간의 지식은 필요 없습니다.
딥러닝 모델은 데이터를 통해 자동으로 필요한 특징(말로는 표현할 수 없지만)을 찾아내고 분류를 수행합니다.
규칙으로 짠 분류, 전통적인 머신러닝 기법의 분류, 그리고 딥러닝 기반의 분류에 이르기까지, 기계 자동화를 위한 방법은 점점 사람의 개입이 줄어드는 방향으로 발전하고 있습니다.
예전엔 어떻게 해서든지 인간이 알고 있는 지식(규칙)을 기계에 전수하려고 했다면, 이제는 인간이 사고하는 방식 그 자체를 기계에게 알려주고 데이터를 제공하는 입장이 되었습니다.
그 뿐이 아니라 최근 발전하는 ‘AutoML’이라는 기술은 인공신경망 구조 자체를 기계가 알아서 디자인하기도 합니다. 사람으로 따지면 뇌를 구성하는 최적의 방법 자체를 기계가 스스로 찾아나가는 것이죠.

딥러닝 방식은 규칙 없이도 다양한 예외 케이스를 처리할 수 있지만, 쉽게 적용할 수 있는 것은 아닙니다. 데이터로부터 특징을 스스로 찾아야 하니 양질의 많은 데이터를 확보해야만 높은 성능을 얻을 수 있고, 복잡해지는 인공신경망 구조의 연산을 수행해야 함에 따라 높은 스펙의 하드웨어를 필요로 합니다.
최근 딥러닝이 화두가 되는 것은 이 두가지의 제약조건을 해결할 방법이 점점 생겨나고 있기 때문입니다. 몇 년 전부터 발생하는 빅데이터 붐으로 인해 많은 기업들이 데이터의 중요성을 깨닫고 양질의 데이터를 다량 확보하는 데 총력을 기울이고 있습니다. 그 중에서도 특히 비정형 데이터의 비중이 높아지고 있죠.

규칙 기반이나 머신러닝 기반의 방식에 비정형 데이터를 이용하려면 태스크에 필요한 특징을 발라내는 작업이 필요한데, 딥러닝 방식은 이미지나 동영상, 텍스트 자료를 그대로 이용할 수 있으니 안성맞춤이죠.
그런가하면 더 많은 데이터를 저장하고, 더 빠른 연산을 도와주는 하드웨어의 발전도 뒷받침을 해주는 요인입니다. 1950년대에는 사람크기만한 서버에 5MB를 저장하는 하드디스크뿐이었지만, 요즘은 누구나 집에 몇 TB씩을 손바닥만한 외장하드에 저장할 수 있습니다.
뿐만 아니라 GPU나 TPU를 활용하기 위해서도 비싼 서버장비를 구매할 필요 없이 클라우드 서비스 플랫폼을 통해 필요한 만큼만 이용할 수 있는 등, 장비 접근성도 용이해졌습니다.

이러한 환경의 변화에 따라 성능이 좋은 딥러닝 알고리즘도 계속 발전하고 있으니, 모라벡의 역설이 바뀔 날도 곧 오지 않을까요? 기계에게 쉬운 일이 사람에게는 어려울 수 있다. 사람에게 쉬운 일은 기계에게도 곧 쉬워질 것이다!
오늘은 간단한 예제를 통해 딥러닝이 기존 방식들과 어떤 차이가 있고, 특장점이 무엇인지를 알아보았습니다. 다음 시간부터는 이러한 바람에 따라 최신 딥러닝 기술 트렌드에 대해 설명드리는 시간을 갖겠습니다.
글 l LG CNS AI빅데이터연구소
[참고 문헌]


