
기업의 가장 기본적인 목표가 ‘오래 생존하는 것이다.’라는 말은 불변의 법칙입니다. 이를 위해 기업은 경영전략 전반에 걸쳐 ‘하나의 사업에 선택과 집중할 것인가?’ 혹은 ‘끊임없이 변화하고 혁신해야 하는가?’ 하는 두 가지 패러다임에 직면합니다.
빠른 비즈니스 환경의 속도 변화는 이 두 가지 패러다임에 공통적으로 적용되며, 생존하기 위한 도구로써 디지털 트랜스포메이션의 중요성이 대두되고 있습니다. 고객과 시장의 변화 요구에 대응하기 위해서 민첩성과 적시 의사결정의 중요성이 강조되고 있으며 이를 지원하기 위한 고객 가치 혁신의 도구로써 클라우드 아키텍처, 애자일(Agile)한 조직 문화, 거버넌스 등을 앞서 살펴보았습니다.
하지만 기업의 최전선에서 기업의 영리 활동을 도모하는 현업 사용자에게는, 거시적인 관점에서의 디지털 트랜스포메이션으로 전환보다는 당장 자신이 하고 있는 일에 어떤 가치를 제공받을 수 있는지가 더 중요할 수도 있습니다.
비즈니스를 수행하는 현업 입장에서는 자신이 사용하고 있는 시스템이 클라우드 기반인지 온프레미스(On-Premise) 기반인지 차이를 못 느끼며 어쩌면 중요하지 않을 수도 있습니다. 다만 자신이 수행하고 있는 비즈니스 데이터를 활용해 업무의 전략과 개선의 도구로써 더 많은 가치와 솔루션을 제공받을 수 있다면 고객 가치를 제고할 수 있는 충분한 밑거름이 될 것입니다.

이번 원고에서는 디지털 기술의 일환으로서 클라우드의 유연성 기반 하의 데이터 분석 및 활용의 장점, 각 클라우드 서비스 제공자(Cloud Service Provider, 이하 CSP)가 제공하는 Cloud Native Application(이하 CNA) 기반의 End-to End 데이터 플랫폼의 이점, 마지막으로 성공 사례를 살펴보겠습니다.
클라우드는 유연하다
혹자는 클라우드가 유연한 것과 최적화된 빅데이터 분석 환경을 구축하는 것이 무슨 관련이 있냐고 물을 수 있습니다. 두 수식어가 약간은 모호하고 포괄적인 개념이기 때문인데요. 여기서 클라우드의 유연함이란 ‘내가 원하는 서비스만을 골라 쓸 수 있다.’라는 점과 ‘내가 쓴 만큼 비용을 지불한다.’라는 점을 의미합니다.
즉, 빅데이터 분석의 세 가지 요소 기술인 ‘대량의(Volume)’ ‘다양한(Variety)’ 데이터를 ‘빠르게(Velocity)’ 최적화된 비용으로 가공할 수 있는 환경을 클라우드는 제공합니다.
예를 들어 매달 5TB의 신규 데이터가 발생하는 A사에서 데이터 분석을 위한 일반적인 온프레미스(On-Premise) 시스템을 구축한다고 가정해 보겠습니다.
[가정1]
A사는 6개월 치 데이터 처리량에 해당하는 30TB의 라이브 스토리지 서버를 구축하고, 6개월 이후 데이터를 옮겨 저장할 아카이브용 스토리지 서버를 따로 30TB 구축했습니다. 그리고 6개월에 한 번씩 데이터 통합 분석을 하기 위해 CPU 및 메모리 등의 컴퓨팅 서버 또한 최적화했습니다.
막상 구축하고 나니 스토리지와 컴퓨팅 파워는 초기에 여유가 있는 상황이며, 문제없이 잘 돌아가는 것 같으니 만족하면서 사용을 합니다. 하지만 더 의미 있는 데이터 분석 결과를 도출하기 위해 새로운 종류의 고객 정보인 위치 정보와 결제 정보를 추가 수집하기로 의사 결정됨에 따라 매달 유입되는 데이터양이 초기 예상보다 10TB로 증가했습니다. (혹은, 반대로 유관 사업을 중단해 매달 유입되는 데이터양이 줄 거나 없어질 수도 있습니다.)
이런 경우에 A사는 추가적인 스토리지, 컴퓨팅 자원을 확보(혹은 감가상각을 감수하고 재판매)할 수밖에 없고 그런데도 데이터 분석 환경과 관련된 불확실 요소들이 제거되지 않는 경우가 발생할 수 있습니다. 더욱 최악인 경우는 서버 증설로 인한 비용 증가를 막기 위해 추가적인 비즈니스 요건을 수용할 수 없는 점입니다.

[가정2]
이번에는 A사가 클라우드 환경을 통해서 데이터 분석 환경을 구축한 경우를 생각해 보겠습니다. 첫 달에는 5TB를 위한 스토리지와 컴퓨팅 파워만을 사용했으며 두 번째 달에는 10TB를 위한 스토리지를 사용했습니다. 5개월 차부터 위치 정보, 결제 정보를 추가 수집하기로 했지만, 확장성에 있어서 아무런 문제가 되지 않습니다.
5개월 차에는 30TB(5+5+5+5+10), 6개월 차에는 40TB의 스토리지를 사용하면 됩니다. (반대로 데이터 유입이 줄 거나 없어지면 다시 자원을 조정하면 됩니다) 6개월에 한 번 시행하는 통합 데이터 분석 또한 그 시점에 필요한 40TB를 분석하기 위한 컴퓨팅 파워를 추가로 구성하면 됩니다.
그뿐만 아니라, CSP들은 다양한 서비스를 제공하기에 6개월 이후의 데이터는 더 값싼 가격으로 보관할 수 있고(e.g. AWS S3 Glacier), 더 높은 컴퓨팅 파워를 위해 GPU를 활용할 수도 있으며(e.g. AWS EC2 P3 인스턴스) 대규모 데이터 처리를 위한 스토리지의 고성능 파일 시스템을 추가 확보할 수도 있습니다. (e.g. AWS FSx for Lustre)
이처럼 원하는 서비스를 선택해 사용할 수 있는 유연한 클라우드의 특성은 최적화된 빅데이터 분석 환경 구축을 가능하게 합니다. 그러므로 급변하는 비즈니스 환경에서 데이터 분석을 통한 애자일하고 초 개인화된 맞춤형 서비스, 제품을 개발하기 위해서 클라우드는 선택이 아닌 필수라 말할 수 있습니다.
클라우드는 자기 완결형 분석 환경을 제공한다
현업이 데이터를 분석하고 활용하는 일련의 활동은 기존에도 수행해 온 업무입니다. 하지만 조직에서 데이터를 처리하고 분석할 수 있는 가용자원의 한계 및 기존 IT 조직과의 협업이 원활하지 못한 점이 발목을 잡는 경우가 많은 것 또한 현실입니다. IT를 통해 받고 싶은 데이터는 규모, 속도, 다양성 측면에서 한계가 있으며 이는 곧 비즈니스 활동의 제약으로 이어집니다.
반면 각 CSP는 이러한 불편함을 해소하기 위해 미리 준비해 둔 CAN을 활용한 데이터 플랫폼을 사용자가 End-to-End로 빠르고 손쉽게 사용할 수 있게 해 줌으로써, 디지털 시대 비즈니스 환경 변화에 민첩하게 대응하기 위한 기존 방식과는 비교할 수 없는 장점을 제공합니다. 가트너(Gartner) 리서치 결과에 따르면 약 80% 이상의 기업에서 CSP가 제공하는 클라우드 환경 기반의 데이터 관리를 고려하고 있습니다.
가트너에서 제공하는 Data & Analytics 아키텍처에서는 데이터 플랫폼의 End-to-End 프로세스의 Core Component를 7개 영역으로 구분하고 있습니다.
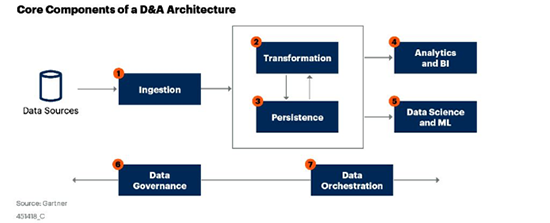
Core Component는 데이터의 수집(① Ingestion)부터 데이터를 변환 가공(② Transformation) 및 저장, 보존하고(③ Persistence) 이를 사용해 데이터 분석, 활용(④ Analytics and BI)에 적용, 나아가 데이터 사이언스, 기계학습(⑤ Data Science and ML)을 통한 보다 고도화된 분석 가치를 끌어내는 데이터 애플리케이션 프로세스와 이를 관리하기 위한 데이터 거버넌스(⑥ Data Governance) 및 데이터 워크플로우 자동화(⑦ Data Orchestration)로 구성되며, 주요 CSP사에서는 CAN 및 ISV(Independent Software Vendor)로 구성된 데이터 플랫폼을 제공하고 있습니다.
● Amazon AWS 데이터 플랫폼
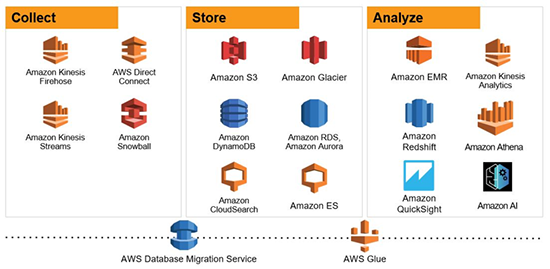
Amazon AWS의 데이터 플랫폼은 실시간 처리, 대용량 데이터의 다양성을 수용할 수 있는 저장, 사용자 분석을 용이하게 수행할 수 있는 비즈니스 인텔리전스(이하 BI) 및 기계학습(Machine Learning, 이하 ML) 등 Full Stack을 보유하고 있습니다.
특히, 수요에 따른 빅데이터 애플리케이션을 더 쉽게 구축, 배포, 조정할 수 있음으로 사용자는 이러한 업데이트와 관리보다는 비즈니스 문제 자체에 집중할 수 있습니다.
Amazon Redshift는 빠르고 완벽하게 관리되는 페타바이트(Petabyte) 규모의 데이터 웨어하우스(DW) 서비스로서 간편하고 비용 효율적으로 기존 BI 도구를 사용해 모든 데이터를 효율적으로 분석할 수 있습니다.
컬럼 방식의 스토리지 기술을 사용해 여러 노드에서 쿼리를 병렬로 실행하고 분산함으로써 데이터 세트 크기에 상관없이 빠른 쿼리 및 I/O 성능을 제공하며, 데이터 웨어하우스(DW)에 대한 프로비저닝, 구성, 모니터링, 백업 및 보안과 관련된 일반적인 관리 작업을 대부분 자동화하므로 유지 및 관리가 간편하면서도 비용이 적게 듭니다.
Amazon ML을 활용하면 누구나 예측 분석 및 기계 학습 기술을 손쉽게 사용할 수 있기에 현업 사용자도 복잡한 ML 알고리즘과 기술을 배우지 않아도 시각화 도구 및 대화식의 마법사 기능을 통한 모델 프로세스 작성할 수 있습니다.
야간에 다양한 데이터 소스를 통합하고 처리하는 데이터 프로세스 작업을 고려해 Amazon EC2 스팟 시장을 제공하며 이를 통해 최대 90% 할인된 금액으로 사용할 수 있는 다양한 요금제 또한 제공하고 있습니다. 다만 테라바이트(Terabyte) 규모의 데이터 수집은 지원하지 않으며 시퀀스 예측 및 비감독 클러스터링은 지원되지 않는 등 ML 모델의 한계는 존재합니다.
● Google GCP 데이터 플랫폼
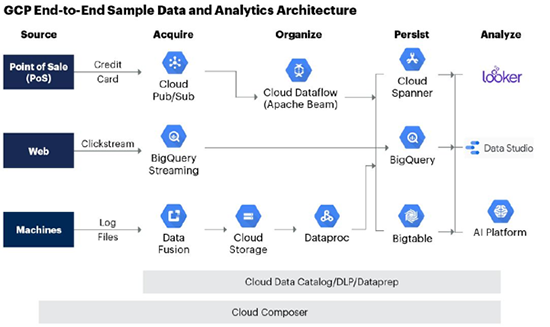
GCP를 통해 제공되는 퍼블릭 클라우드 서비스 기반 데이터 분석 도구와 솔루션 또한 서버리스 데이터 플랫폼을 지향하며 클라우드 DW 제품인 빅쿼리(BigQuery)와 다양한 AI 제품군을 장점으로 꼽을 수 있습니다.
빅쿼리는 GCP의 장점을 극대화한 제품으로, 별도의 설치작업을 거치지 않는 구글 클라우드 기반의 완전 관리형 DW 제품이며 SQL을 통해 현업도 쉽게 분석할 수 있고 페타바이트 규모의 처리 성능과 인프라 운영 등을 제공해 부가적인 관리 포인트를 전혀 신경 쓸 필요가 없습니다.
구글은 20년간 ML 및 AI 분야에서 혁신을 이룬 결과 다양한 솔루션을 보유하고 있습니다. 현업이 간단한 SQL만 사용해 쉽게 구조화 또는 반 구조화된 데이터를 기반으로 ML 모델을 만들고 예측할 수 있는 BigQueryML, 간단한 그래픽 사용자 인터페이스를 사용해 데이터를 기반으로 모델을 학습, 평가, 개선, 배포할 수 있는 Cloud Auto ML 등 별도의 전문화된 기술 및 지식 없이도 예측 모형을 현업이 직접 만들 수 있는 기능이 제공됩니다.
● Microsoft Azure 데이터 플랫폼
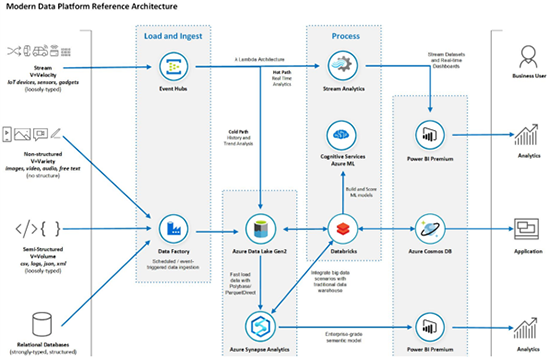
Microsoft Azure 데이터 플랫폼은 PaaS 형태의 클라우드 서비스로, 사용자 친화적인 OS 및 Office365 도구 등과 밀접하게 연계가 가능합니다. 유연성 측면에서는 제한적이지만 플랫폼 구축에 대한 비용 및 유지 보수 차원에서 더 효율적이라는 점 또한 장점으로 꼽을 수 있습니다.
현업 분석 활용에서는 기존 온프레미스에서 사용한 Azure SQL Database 및 Power BI 솔루션을 그대로 클라우드 환경에서 활용할 수 있고, 분석 측면에서는 Azure Machine Learning에서 제공하는 별도 제공 디자이너를 통해 사용자가 쉽게 기계 학습 모델을 만들 수 있습니다. Deep Learning 기반의 Pre-built 된 BOT Service를 통한 지능형 대화봇, Cognitive Services를 통한 시나리오 기반의 자연어 처리봇 등을 제공합니다.
주요 3사에서 제공하는 데이터 플랫폼의 특징은, 데이터 수집부터 분석까지 기구축되어 있는 최적화된 환경을 제공한다는 점이며, 현업 사용자가 전문 프로그래밍의 지식 없이도 간단한 조작만으로 비즈니스 가치에 더 집중할 수 있도록 한다는 점입니다.
대세로서의 클라우드
클라우드의 도입과 이에 기반한 빅데이터 분석 환경의 구축은 이미 대세라고 말할 수 있습니다. 영화 산업에서 블록버스터 기업이 넷플릭스에 자리를 내어 주고 쇠퇴한 것처럼 새로운 흐름을 읽지 못하고 낡은 것에 안주하는 기업은 경쟁력을 잃고 몰락할 수밖에 없습니다. 실제로 많은 분야의 기업과 정부 기관에서 이 점을 인지하고 각종 클라우드 관련 사업을 활발히 발주하고 있습니다.
한국정보화진흥원(NIA)의 경우 공공기관 최초로 원내 전체 시스템을 민간 클라우드로 전환하겠다고 천명하고 ‘NIA ICT 클라우드 플랫폼 운영 환경 구축’ 공고를 발주했습니다. 정부 시스템인 만큼 민감한 정보와 컴플라이언스 이슈가 많아 PPP(Public Private Partnership) 방식으로 사업이 이루어지며 데이터 센터를 비롯한 IaaS 구축부터 PaaS-TA를 활용한 PaaS 구축까지 사업 범위가 매우 방대합니다.
또한 행정안전부에서도 ‘전자정부 클라우드 플랫폼 구축’ 프로젝트를 통해 정부 부처의 클라우드 기반 AI•빅데이터 활용 능력을 향상하기 위해 노력하고 있습니다. 플랫폼은 포털, 클라우드 어시스트, 클라우드 엔진, 플랫폼 통합 관리, 연계 채널의 5개 모듈로 구성되며 클라우드 인프라 모듈의 경우 별도의 사업으로 발주해 진행 중입니다.
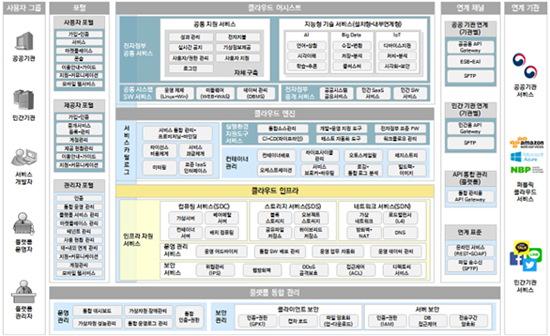
과학기술정보통신부는 민관 협력을 통해 유통•소비, 통신, 금융, 헬스케어, 교통, 환경, 문화 미디어, 중소기업, 산림, 지역 경제의 10가지 분야에 10종의 빅데이터 플랫폼을 클라우드 기반으로 구축했습니다. 이 중 민감한 정보가 많은 헬스케어의 경우 프라이빗 클라우드(Private Cloud), 교통과 유통•소비는 하이브리드(Hybrid)로 구성되었으며 나머지 플랫폼은 퍼블릭 클라우드(Public Cloud)로 구성되어 있습니다.
정부뿐만 아니라 일반 기업도 클라우드 전환 및 데이터 분석 환경 구축에 힘을 쏟고 있는데, 금융업계의 경우 데이터 3법의 시행을 앞두고 적극적으로 클라우드 기반 빅데이터 분석 환경 구축에 앞장서고 있습니다.
NH농협은행이 하이브리드•멀티 클라우드 전략을 펼치면서 빅데이터 분석, 클라우드 포털 등의 업무를 PaaS에 적용한 바 있고, KB국민은행도 클라우드 플랫폼 클레이온(CLAYON)의 운영을 통해 빅데이터를 활용한 초개인화 서비스 개발에 박차를 가하고 있습니다.
AI 헬스케어 스타트업인 뷰노(Vuno)는 코로나19 확진자의 데이터를 기반으로 X-Ray 판독 솔루션을 무료로 제공하는데, 이 과정에서 고사양의 컴퓨팅 파워를 확보하기 위해 AWS의 EC2 인스턴스와 Azure의 컴퓨팅 인스턴스를 사용하고 있습니다.

이처럼 많은 주체가 앞다투어 클라우드와 빅데이터 분석 기술을 차용하고 있습니다. 클라우드와 빅데이터는 IT 기업만의 전유물이 아니며 모든 기업의 대세이자 흐름입니다. 아직은 도입 초기인 만큼 가시적인 성과가 현저하게 나타나고 있지는 않지만 향후에 선두주자들이 어떠한 경쟁력을 가지게 될지, 후발주자들은 어떤 후폭풍을 겪게 될지 지켜보는 것도 좋을 듯합니다.
글 l LG CNS Entrue Consulting 클라우드그룹
[‘클라우드 서비스의 모든 것’ 연재 현황]
[1편] 디지털 트랜스포메이션의 필수 전략! 기업의 클라우드 전환
[2편] 클라우드 서비스 제공 업체(CSP)와 그 특징은?
[3편] 클라우드 도입으로 변화하는 ‘조직, 문화, 거버넌스'(上)
[3편] 클라우드 도입으로 변화하는 ‘조직, 문화, 거버넌스'(下)
[4편] 디지털 전환 시대의 조직 문화는 무엇일까?
[5편] 기업의 클라우드 도입, 조직은 어떻게 바뀌어야 하는가?
[6편] 클라우드 도입에 따른 IT 거버넌스의 변화는 무엇인가?
[7편] 이 속도 실화? 클라우드가 빅데이터의 ‘대세’인 이유


