엄청난 양의 데이터와 연산 과정에 의해 구현되는 인공지능은 인간의 학습 과정, 사고방식과 비교하면 매우 비효율 적입니다. 인간은 대부분의 경우 직관과 일반화를 통해 상황을 판단하고 매우 빠르고 즉각적으로 결정하는데요. 그 답이 반드시 정답이 아닐지라도 근사치에 가까운 답을 빠르게 찾아내는 것입니다. 예를 들어 3.14 * 3.14의 값을 정확히 계산하지 않아도 3*3의 결과인 9 보다 크다는 것을 인간은 즉시 알 수 있는 것과 같습니다.
이렇게 인간처럼 계산하고 사고하는 방식으로 인공지능도 구현된다면 데이터와 컴퓨팅의 비효율성을 개선할 수 있을 것입니다. 물론 정교하고, 정확한 작업을 요구하는 분야에는 적용이 어려울 수 있습니다. 하지만 인간의 일상생활에서도 매우 정확한 계산과 정교한 판단 요구되는 상황은 제한적인데요.

반대로 단지 몇 번의 경험에 의존해 새로운 상황에 대응하거나, 변화하는 환경에 직관적이며 빠르게 대응해야 하는 상황이 더 빈번하게 발생합니다. 따라서 이러한 측면을 고려해 다음과 같이 크게 두 가지 측면에서 인공지능 구현을 위한 연구, 개발이 진행 중입니다.
Approximate Computing
매우 적은 양의 데이터와 컴퓨팅 파워를 사용하면서 일정 수준 이상의 지능을 매우 빠르게 구현하려 합니다. 우선 적은 양의 데이터를 학습하면서도 지능을 고도화 시키는 방법인데요. 방대한 빅데이터를 모두 학습하는 것이 최선이지만 학습 시간, 비용 등 측면에서는 소량의 데이터를 학습 시키는 것이 더 효율적입니다. 만약 방대한 빅데이터 중 대표성을 갖는 데이터를 정교하게 선별해 소량의 데이터만 학습 과정에 활용한다면 매우 효과적일 것입니다.
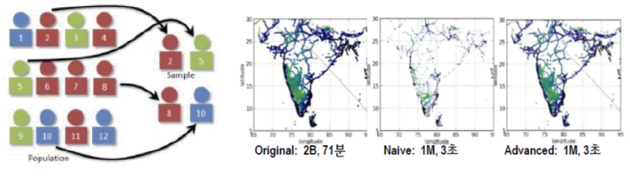
실제 미시건 대학의 연구팀은 이러한 데이터 샘플링 방식의 고도화에 대한 논문1을 발표했습니다. 아래 그림과 논문에서 연구된 샘플링 방식을 활용해 데이터 처리 속도를 약 200배(400초 → 2초) 이상 단축시켰습니다. 물론 정확도 측면에서는 약 2%~5%의 하락이 있었지만 속도 측면의 향상과 비교했을 때 의미 있는 결과라고 할 수 있습니다.
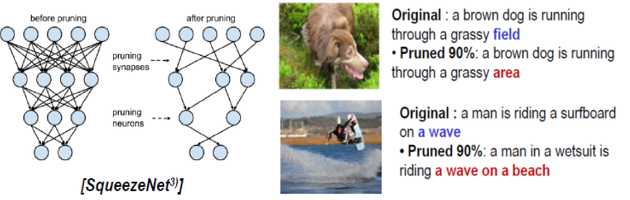
또한 인공신경망 구조를 단순화해 컴퓨팅 비용을 최소화하려는 연구도 진행 중입니다. SqueezeNet2이라는 이 연구는 그림 1의 왼쪽 그림과 같이 매우 복잡한 형태로 연결된 인공 신경망을 매우 단순화 시키는데요. 논문에 따르면 비슷한 성능을 유지하면서도 신경망을 약 30~50배로 압축시키는 것이 가능하다고 밝히고 있습니다.
물론 압축된 인공 신경망의 결과는 원래의 복잡한 신경망의 결과와는 다를 수 있습니다. 그림 1의 오른쪽 그림과 같이 같은 사진을 보고 인공지능의 해석이 조금씩 차이가 있다는 것을 알 수 있는데요. 하지만 그 해석의 의미가 인간의 해석과 크게 어색하지 않은 수준이라는 것을 알 수 있습니다.
이러한 인공 신경망의 압축 방식은 인간의 뇌 발달 과정과도 유사한 측면이 있습니다. 인공 신경망의 연결과 유사한 인간의 뇌의 시냅스의 연결 개수를 보면 2세 까지는 매우 빠르게 증가하지만 이후 다시 감소하는 것으로 알려졌습니다. (50조: 1세 → 1,000조 개: 2세 → 500조: 10세)
이것은 인간의 지능이 점차 발달하면서 불필요하거나 중복된 시냅스의 연결이 약해지거나 끊어지는 과정을 의미하는데요. 즉, 인공 신경망의 구현도 마찬가지로 중복되거나 성능에 큰 영향을 미치지 않은 연결들을 삭제(Pruning) 함으로써 성능을 최적화하는 것입니다.
One-shot Learning (Transferring Intelligence)
인공지능 구현 시 기존에 학습된 지능을 활용한다면 학습 과정에 요구되는 데이터와 컴퓨팅 비용을 최소화할 수 있습니다. 즉, 유사한 기능을 수행하는 인공지능이 이미 존재한다면 기존의 지능을 새로운 인공지능에 활용하는 지능의 이식(Transferring Intelligence)이 가능한 것입니다. 실제 딥마인드 등 선진 연구 기관에서는 지능의 이식, 재활용에 대한 연구가 활발히 진행3중 입니다.
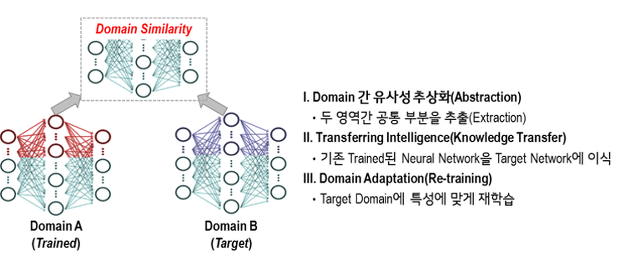
인공지능이 새로운 영역에 활용될 때 적용 분야가 서로 다르더라도 기존 지식을 최대한 활용하기 때문에 단시간에 성능을 발휘하는 것이 가능한데요. 새로운 영역에 대한 학습 과정이 매우 짧다는 의미에서 ‘One-shot Learning’ 혹은 ‘Zero-shot Learning’이라 불리기도 합니다. 지능의 이식 과정은 아래 그림과 같이 크게 세 단계로 나뉩니다.
서로 다른 두 영역 간의 유사성을 추출하고 학습된 지능을 새로운 지능에 이식합니다. 지능이 이식된 새로운 인공지능은 새로운 데이터를 통한 재학습 과정을 걸쳐 목적한 영역에 최적화된 형태로 구현됩니다.
이러한 지능의 이식 관련 연구는 매우 초기 단계이지만 실제 산업 영역에 활용될 가능성을 두고 연구, 개발이 진행 중입니다. 예를 들어 언어 인식의 경우 각 언어가 갖는 특성으로 인해 매우 다릅니다. 하지만 기본적인 언어의 속성들은 유사한 측면이 많습니다.
주어•동사•목적어 등의 문장의 구성 요소 혹은 서술문•의문문•감탄문 등 문장의 속성 등이 이에 속합니다. 따라서 이러한 언어의 기본 속성들과 관련된 지능은 공통적으로 활용 가능할 것입니다. 실제 인공지능 선도 기업인 바이두는 영어와 중국어에 대한 언어 인식 관련 인공지능 구현 시 이러한 언어의 유사성을 고려했다고 밝혔습니다.
영어 인식 지능을 구현하며 학습한 지능에서 언어의 기본적인 속성과 관련된 지능을 중국어 인식 지능에 이식합니다. 그 후 중국어만이 갖는 문장 구조•어순 등의 특성을 중국어 데이터를 통해 학습한 것입니다.

폭스바겐의 선행 연구팀에서도 자율 주행 기능 구현 시 유사한 개념을 활용합니다. 기본적으로 자동차를 주행하는 방식은 공용화하는데요. 차선 유지, 서행, 급정지 등과 같은 일반적으로 모든 나라에 적용 가능한 주행 기능은 범용적인 지능으로 구현하는 것입니다. 이후 각 국가별 차이가 있는 주행 방식은 개별적으로 재학습 과정을 통해 맞춤화합니다. 교통신호, 주행 우선순위, 표지판 등이 이에 해당합니다.
이러한 지능의 이식, 활용은 인공지능의 학습 과정에 요구되는 비용을 혁신적으로 줄 일 수 있습니다. 한 발 더 나아가 모든 영역에 활용 가능한 범용 인공지능(General Artificial Intelligence) 구현의 초기 연구 단계로써 많은 선진 인공지능 연구소를 중심으로 활발히 연구 중에 있습니다.
글 l 이승훈 책임연구원(shlee@lgeri.com) l LG경제연구원


